本文共 7153 字,大约阅读时间需要 23 分钟。
文章目录
1.OSI,TCP/IP,五层协议的体系结构,以及各层协议
OSI分层 (7层):物理层、数据链路层、网络层、传输层、会话层、表示层、应用层。
TCP/IP分层(4层):网络接口层、 网际层、运输层、 应用层。 五层协议 (5层):物理层、数据链路层、网络层、运输层、 应用层。| 层 | 作用 | 数据单位 | 协议 |
|---|---|---|---|
| 物理层 | 通过媒介传输比特,确定机械及电气规范 | 比特Bit | RJ45、CLOCK、IEEE802.3 (中继器,集线器) |
| 数据链路 | 将比特组装成帧和点到点的传递 | 帧Frame | PPP、FR、HDLC、VLAN、MAC (网桥,交换机) |
| 网络层 | 负责数据包从源到宿的传递和网际互连 | 包PackeT | IP、ICMP、ARP、RARP、OSPF、IPX、RIP、IGRP(路由器) |
| 传输层 | 提供端到端的可靠报文传递和错误恢复 | 段Segment | TCP、UDP、SPX |
| 会话层 | 建立、管理和终止会话 | 会话协议数据单元 | NFS、SQL、NETBIOS、RPC |
| 表示层 | 对数据进行翻译、加密和压缩 | 表示协议数据单元 | JPEG、MPEG、ASII |
| 应用层 | 允许访问OSI环境的手段 | 应用协议数据单元 | FTP、DNS、Telnet、SMTP、HTTP、WWW、NFS |
2.TCP和UDP的区别
TCP协议不会自动检测连接是否断开
| TCP | UDP | |
|---|---|---|
| 连接方式 | 面向连接的、可靠的数据流传输 | 非面向连接的、不可靠的数据流传输 |
| 通信方式 | 一对一、点对点 | 一对一、一对多、多对一、多对多 |
| 传输单位 | TCP报文段 | 用户数据报 |
| 对系统资源要求 | 较多(TCP的20个字节信息包),负载高,采用虚电路 | 较少(UDP信息包的标题很短,只有8个字节) |
| 安全性 | 可靠,安全 | 数据传输快,但是不可靠(尽最大努力交付) |
| 对应协议 | FTP、Telnet、SMTP、POP3、HTTP | DNS、SNMP、TFTP |
TCP提供超时重发、丢弃重复数据、检验数据、窗口技术、流量控制等功能,保证数据能传到另外一端。
UDP常用于QQ等即时通讯软件(适合于实时通信,当网络阻塞时,不影响发送端的发送效率。- TCP对应的协议 (1) FTP:定义了文件传输协议,使用21端口。 (2) Telnet:一种用于远程登陆的端口,使用23端口,用户可以以自己的身份远程连接到计算机上,可提供基于DOS模式下的通信服务。 (3) SMTP:邮件传送协议,用于发送邮件。服务器开放的是25号端口。 (4) POP3:它是和SMTP对应,POP3用于接收邮件。POP3协议所用的是110端口。 (5)HTTP:是从Web服务器传输超文本到本地浏览器的传送协议。
- UDP对应的协议 (1) DNS:用于域名解析服务,将域名地址转换为IP地址。DNS用的是53号端口。 (2) SNMP:简单网络管理协议,使用161号端口,是用来管理网络设备的。由于网络设备很多,无连接的服务就体现出其优势。 (3) TFTP(Trival File Transfer Protocal),简单文件传输协议,该协议在熟知端口69上使用UDP服务。
3.TCP三次握手和四次挥手的全过程
- 三次握手 第一次握手:客户端发送syn包(syn=x)到服务器,并进入SYN_SEND状态,等待服务器确认; 第二次握手:服务器收到syn包,必须确认客户的SYN(ack=x+1),同时自己也发送一个SYN包(syn=y),即SYN+ACK包,此时服务器进入SYN_RECV状态; 第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=y+1),此包发送完毕,客户端和服务器进入ESTABLISHED状态,完成三次握手。 握手过程中传送的包里不包含数据,三次握手完毕后,客户端与服务器才正式开始传送数据。理想状态下,TCP连接一旦建立,在通信双方中的任何一方主动关闭连接之前,TCP 连接都将被一直保持下去。
- 四次挥手 与建立连接的“三次握手”类似,断开一个TCP连接则需要“四次握手”。 第一次挥手:主动关闭方发送一个FIN,用来关闭主动方到被动关闭方的数据传送,也就是主动关闭方告诉被动关闭方:我已经不 会再给你发数据了(当然,在fin包之前发送出去的数据,如果没有收到对应的ack确认报文,主动关闭方依然会重发这些数据),但是,此时主动关闭方还可以接受数据。 第二次挥手:被动关闭方收到FIN包后,发送一个ACK给对方,确认序号为收到序号+1(与SYN相同,一个FIN占用一个序号)。 第三次挥手:被动关闭方发送一个FIN,用来关闭被动关闭方到主动关闭方的数据传送,也就是告诉主动关闭方,我的数据也发送完了,不会再给你发数据了。 第四次挥手:主动关闭方收到FIN后,发送一个ACK给被动关闭方,确认序号为收到序号+1,至此,完成四次挥手。
- 为什么会采用三次握手,若采用二次握手可以吗? 采用三次握手是为了防止失效的连接请求报文段突然又传送到主机B,因而产生错误。 失效的连接请求报文段是指:主机A发出的连接请求没有收到主机B的确认,于是经过一段时间后,主机A又重新向主机B发送连接请求,且建立成功,顺序完成数据传输。考虑这样一种特殊情况,主机A第一次发送的连接请求并没有丢失,而是因为网络节点导致延迟达到主机B,主机B以为是主机A又发起的新连接,于是主机B同意连接,并向主机A发回确认,但是此时主机A根本不会理会,主机B就一直在等待主机A发送数据,导致主机B的资源浪费。
- 为什么会采用四次挥手,若采用三次挥手可以吗? 因为关闭连接时,server端收到客户端的FIN报文,并不会立即关闭socket,只能先回复一个ACK告诉client我已经收到你的关闭请求了,同时可能server还有数据没传输完,只有等server端数据传输完成了 才能发送FIN报文,所以这个地方要分两次发送,这样就有了四次挥手。 -服务端的Time_Wait状态再哪个阶段出现?持续多久?为什么要设计这么一个状态?
- timewait阶段是最后阶段发送确认收到server端的fin报文释放连接请求后回复给server端ack报文,之后client端就进入time_wait阶段.
- 持续多久即是问为什么不马上关闭直接进入closed阶段,主要是考虑到网络的不可靠,假如client最后阶段发送给server端端ack报文由于网络原因丢失了server没收到呢,server端会重新发送fin报文过来,这个时候client端就要等. 等多久?等一个计时器时间2MSL,如果该时间段内再次收到server的fin报文 那client就必须回复. 如果没有收到,client就认为server端已经接收到了最后的ack报文.
4.IP地址
IP地址分为两个部分,网络号和主机号。
A类地址:以0开头, 第一个字节范围:1~126(1.0.0.0 - 126.255.255.255); B类地址:以10开头, 第一个字节范围:128~191(128.0.0.0 - 191.255.255.255); C类地址:以110开头, 第一个字节范围:192~223(192.0.0.0 - 223.255.255.255); D类地址:以1110开头,第一个字节范围:224~239(224.0.0.0 - 239.255.255.255);(作为多播使用) E类地址:保留 其中A、B、C是基本类,D、E类作为多播和保留使用。以下是留用的内部私有地址:
A类 10.0.0.0–10.255.255.255 B类 172.16.0.0–172.31.255.255 C类 192.168.0.0–192.168.255.255IP地址与子网掩码相与得到网络号:
ip : 192.168.2.110 &Submask : 255.255.255.0 网络号 :192.168.2 .0 注: 主机号,全为0的是网络号(例如:192.168.2.0),主机号全为1的为广播地址(192.168.2.255)5.ARP和RARP
- ARP地址解析协议 ARP是地址解析协议,作用是完成IP地址到硬件地址的映射。 工作流程: 1:首先,每个主机都会在自己的ARP缓冲区中建立一个ARP列表,以表示IP地址和MAC地址之间的对应关系。 2:当源主机要发送数据时,首先检查ARP列表中是否有对应IP地址的目的主机的MAC地址,如果有,则直接发送数据,如果没有,就向本网段的所有主机发送ARP数据包,该数据包包括的内容有:源主机 IP地址,源主机MAC地址,目的主机的IP 地址。 3:当本网络的所有主机收到该ARP数据包时,首先检查数据包中的IP地址是否是自己的IP地址,如果不是,则忽略该数据包,如果是,则首先从数据包中取出源主机的IP和MAC地址写入到ARP列表中,如果已经存在,则覆盖,然后将自己的MAC地址写入ARP响应包中,告诉源主机自己是它想要找的MAC地址。 4:源主机收到ARP响应包后。将目的主机的IP和MAC地址写入ARP列表,并利用此信息发送数据。如果源主机一直没有收到ARP响应数据包,表示ARP查询失败。 广播发送ARP请求,单播发送ARP响应。
- RARP逆地址解析协议 RARP是逆地址解析协议,作用是完成硬件地址到IP地址的映射,主要用于无盘工作站,因为给无盘工作站配置的IP地址不能保存。 工作流程:在网络中配置一台RARP服务器,里面保存着IP地址和MAC地址的映射关系,当无盘工作站启动后,就封装一个RARP数据包,里面有其MAC地址,然后广播到网络上去,当服务器收到请求包后,就查找对应的MAC地址的IP地址装入响应报文中发回给请求者。因为需要广播请求报文,因此RARP只能用于具有广播能力的网络。
6.HTTP和HTTPS
HTTP协议:超文本传输协议,是一个属于应用层的面向对象的协议,由于其简捷、快速的方式,适用于分布式超媒体信息系统。
7.浏览器请求
【在浏览器中输入www.baidu.com后执行的全部过程】
- 客户端浏览器通过DNS解析到www.baidu.com 的IP地址220.181.27.48,通过这个IP地址找到客户端到服务器的路径。客户端浏览器发起一个HTTP会话到220.181.27.48,然后通过TCP进行封装数据包,输入到网络层。
- 在客户端的传输层,把HTTP会话请求分成报文段,添加源和目的端口,如服务器使用80端口监听客户端的请求,客户端由系统随机选择一个端口如5000,与服务器进行交换,服务器把相应的请求返回给客户端的5000端口。然后使用IP层的IP地址查找目的端。
- 客户端的网络层不用关心应用层或者传输层的东西,主要做的是通过查找路由表确定如何到达服务器,期间可能经过多个路由器,这些都是由路由器来完成的工作,我不作过多的描述,无非就是通过查找路由表决定通过那个路径到达服务器。
- 客户端的链路层,包通过链路层发送到路由器,通过邻居协议查找给定IP地址的MAC地址,然后发送ARP请求查找目的地址,如果得到回应后就可以使用ARP的请求应答交换的IP数据包现在就可以传输了,然后发送IP数据包到达服务器的地址。
8.cookie,session区别,应用场景
保存登录状态用什么?Cookie ,Session
-
Cookie 是在HTTP协议下,服务器或脚本可以维护客户工作站上信息的一种方式。Cookie信息,可以看作是浏览器缓存。
Session可以代表服务器与浏览器的一次会话过程,指从一个浏览器窗口打开到关闭的这个期间.也可以用于指一类用来在客户端与服务器之间保持状态的解决方案. -
cookie机制采用的是在客户端保持状态的方案
session机制采用的是在服务器端保持状态的方案。 同时由于在服务器端保持状态的方案在客户端也需要保存一个标识,所以session机制可能需要借助于cookie机制来达到保存标识的目的,但实际上还有其他选择,比如说重写 URL和隐藏表单域。 -
session比cookies更安全,比如把用户名密码保存在浏览器,下一个用户登录会暴露信息,session占用资源也更多。其他不记得了
一般来说,登陆验证信息,客户的私人信息,如姓名,电话等,应该放在Session中.
Cookie则用于用户登陆网站时的自动登陆以及类似"购物车"的处理.使用Cookie保存信息时最好通过加密形式来保存数据,同时是否保存登陆信息,需要由用户自行选择。9.get,post区别
转载自
GET和POST是HTTP请求的两种基本方法,最直观的区别就是GET把参数包含在URL中,POST通过request body传递参数。当你在面试中被问到这个问题,你的内心充满了自信和喜悦,你轻轻松松的给出了一个“标准答案”:
GET在浏览器回退时是无害的,而POST会再次提交请求。 GET产生的URL地址可以被Bookmark,而POST不可以。 GET请求会被浏览器主动cache,而POST不会,除非手动设置。 GET请求只能进行url编码,而POST支持多种编码方式。 GET请求参数会被完整保留在浏览器历史记录里,而POST中的参数不会被保留。 GET请求在URL中传送的参数是有长度限制的,而POST么有。 对参数的数据类型,GET只接受ASCII字符,而POST没有限制。 GET比POST更不安全,因为参数直接暴露在URL上,所以不能用来传递敏感信息。 GET参数通过URL传递,POST放在Request body中。(本标准答案参考自w3schools)“很遗憾,这不是我们要的回答!”
GET和POST是什么?HTTP协议中的两种发送请求的方法。
HTTP是什么?HTTP是基于TCP/IP的关于数据如何在万维网中如何通信的协议。 HTTP的底层是TCP/IP。所以GET和POST的底层也是TCP/IP,也就是说,GET和POST本质上就是TCP链接,并无差别。但是由于HTTP的规定和浏览器/服务器的限制,导致他们在应用过程中体现出一些不同。GET和POST还有一个重大区别,简单的说:
GET产生一个TCP数据包;POST产生两个TCP数据包。 长的说: 对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据); 而对于POST,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok(返回数据)。 因为POST需要两步,时间上消耗的要多一点,看起来GET比POST更有效。因此Yahoo团队有推荐用GET替换POST来优化网站性能。但这是一个坑!跳入需谨慎。为什么?- GET与POST都有自己的语义,不能随便混用。
- 据研究,在网络环境好的情况下,发一次包的时间和发两次包的时间差别基本可以无视。而在网络环境差的情况下,两次包的TCP在验证数据包完整性上,有非常大的优点。
- 并不是所有浏览器都会在POST中发送两次包,Firefox就只发送一次。
Socket通信流程
套接字是一种通信机制,凭借这种机制,客户/服务器系统的开发工作既可以在本地单机上进行,也可以跨网络进行,Linux所提供的功能(如打印服务,ftp等)通常都是通过套接字来进行通信的,
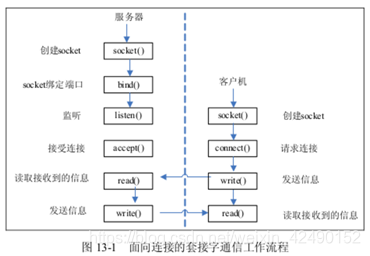
套接字的创建和使用与管道是有区别的,因为套接字明确地将客户和服务器区分出来,套接字可以实现将多个客户连接到一个服务器。 套接字是支持TCP/IP的网络通信的基本操作单元,简单的说就是通信的两方的一种约定,用套接字中的相关函数来完成通信过程。应用层通过传输层进行数据通信时,TCP和UDP会遇到同时为多个应用程序进程提供并发服务的问题。 简单的举例说明:Socket=Ip address+ TCP/UDP + port。1. 面向连接的套接字Socket通信工作流程
为了实现服务器与客户机的通信,服务器和客户机都必须建立套接字。服务器与客户机的工作原理可以用下面的过程来描述。- 1.服务器先用 socket 函数来建立一个套接字,用这个套接字完成通信的监听。
- 2.用 bind 函数来绑定一个端口号和 IP 地址。因为本地计算机可能有多个网址和 IP,每一个 IP 和端口有多个端口。需要指定一个 IP 和端口进行监听。
- 3.服务器调用 listen 函数,使服务器的这个端口和 IP 处于监听状态,等待客户机的连接。
- 4.客户机用 socket 函数建立一个套接字,设定远程 IP 和端口。
- 5.客户机调用 connect 函数连接远程计算机指定的端口。
- 6.服务器用 accept 函数来接受远程计算机的连接,建立起与客户机之间的通信。
- 7.建立连接以后,客户机用 write 函数向 socket 中写入数据。也可以用 read 函数读取服务器发送来的数据。
- 8.服务器用 read 函数读取客户机发送来的数据,也可以用 write 函数来发送数据。
- 9.完成通信以后,用 close 函数关闭 socket 连接。
 2.面向无连接的套接字Socket通信工作流程 无连接的通信不需要建立起客户机与服务器之间的连接,因此在程序中没有建立连接的过程。 进行通信之前,需要建立网络套接字。服务器需要绑定一个端口,在这个端口上监听接收到的信息。客户机需要设置远程 IP 和端口,需要传递的信息需要发送到这个 IP 和端口上。
2.面向无连接的套接字Socket通信工作流程 无连接的通信不需要建立起客户机与服务器之间的连接,因此在程序中没有建立连接的过程。 进行通信之前,需要建立网络套接字。服务器需要绑定一个端口,在这个端口上监听接收到的信息。客户机需要设置远程 IP 和端口,需要传递的信息需要发送到这个 IP 和端口上。 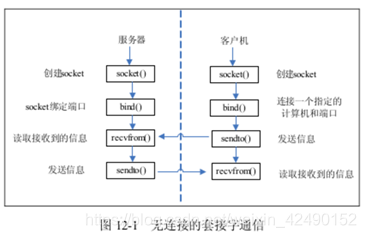
转载地址:https://blog.csdn.net/weixin_42490152/article/details/99694247 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
