本文共 1076 字,大约阅读时间需要 3 分钟。
首先,es 的设计理念就是分布式搜索引擎,底层还是基于lucene的
核心思想就是在多台机器上启动多个es进程实列,组成一个es集群。
es中存储数据的基本单位是索引,假设你要在es中存储数据,首先就要在es中创建一个索引,所有的数据都写到这个索引里面去,一个索引差不多相当于mysql里面的一张表。
index->type->mapping->document->filed
1、index 相当于mysql里的一张表
2、type:一个index里面可以有很多type,每个type的字段都是差不多的。但是有一些差别,例如:订单数据中的实物订单和虚拟订单。就需要在index里建立两个type;
3、每个type有一个mapping.代表type的表结构定义;定义了这个type中每个字段的名称,类型,以及各种配置。
4、document相当于index里type 的一条数据 ;
5、每个document有多个field,field相当于document中每个字段的值
接着你建一个索引,这个索引可以拆分成多个shard,每个shard存储部分数据。实现分布式
每个shard里的数据有多个备份,如果某台机器宕机,别的机器上还是有数据副本,这样就构成高可用。
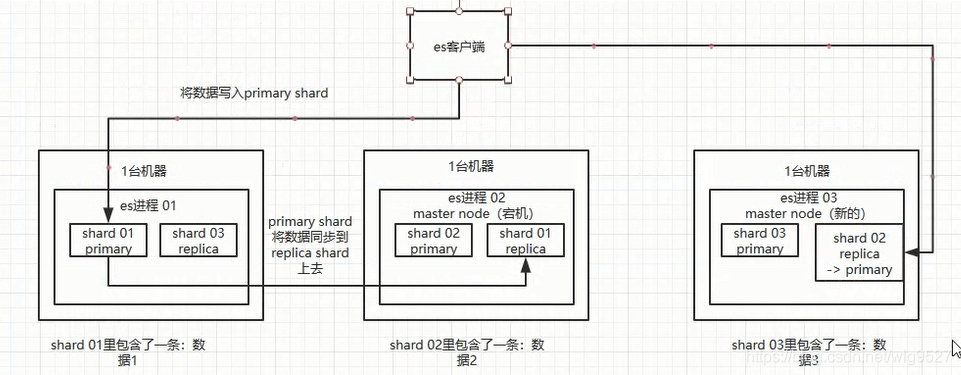
如下图:es客户端会将数据写入primary shard.然后会将数据同步到replica shard.实现数据的备份。es集群会选举一个节点作为master node (es进程02),主要作用就是负责维护索引元数据、切换primary shard 和replica shard 的身份;
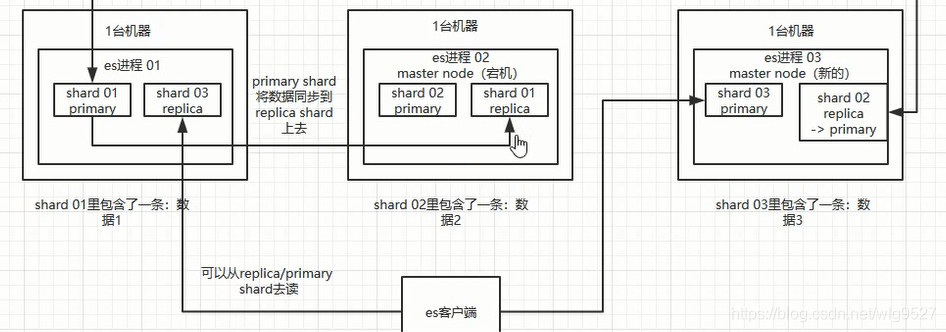
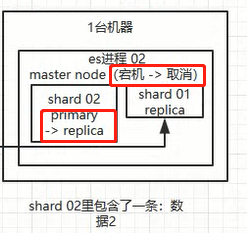
1、如果master node 宕机了,就会重新选举一个新的master node(es进程03).接着新的master node 将es进程03 中的shard 02 replica 变为primary shard ,一旦宕机的机器维护好了,就会将原来的master node 的shard 02 primary 变更为shard 02 replica。这样集群就恢复了
2、如果是非master node 宕机,假设是es进程01宕机,那么master会将它的备份shard身份切换为primary shard .当01修复,master切换01 上shard01 primary为shard 01 replica.
以上就是es分布式部署原理
注意的是es客户端写数据只能写到primary shard ,但是读数据既可以从primary shard ,也可以从replica shard
转载地址:https://blog.csdn.net/wlg9527/article/details/107333756 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
