本文共 4025 字,大约阅读时间需要 13 分钟。
文章目录
SqueezeNet
论文:SQUEEZENET: ALEXNET-LEVEL ACCURACY WITH 50X FEWER PARAMETERS AND <0.5MB MODEL SIZE
论文的目的在于在保证模型精度的情况下,尽量减少模型的参数。本文在此目的下提出了3条设计策略:
1)用1x1的卷积核代替3x3的卷积核 2)输入到3x3卷积层的feature map的通道数,从而减少3x3卷积层的参数量 3)在网络中推迟downsampling的位置,使得feature map(文中叫做activation)比较大文章提出了Fire Module,包括两层:
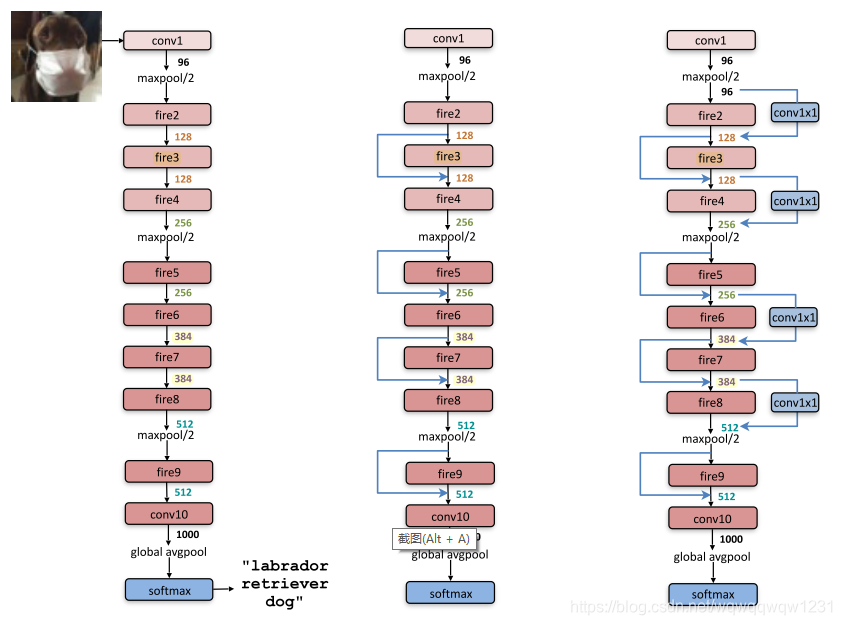
1)squeeze layer:就是用1x1的卷积核压缩维度 2)expand layer:用1x1的卷积核和3x3的卷积核提取特征,扩展维度 这里就用了前两条设计策略。然后将Fire module堆叠起来,使用第3条策略,推迟down sampling,在feature map尺度适中的地方多加几个fire module,形成SqueezeNet,如下左图:
 最后使用Deep compression的技术,将模型压缩到0.5M
最后使用Deep compression的技术,将模型压缩到0.5M 在ablation study中,作者讨论了:
1)squeeze layer的kernel的数量 2)expand layer中1x1和3x3的比例 对结果的影响。作者也做了类似于resnet的shortcut的连接,如上中图和上右图,发现隔层直接连接最好,不要加1x1的卷积核调整维度
最后,该文章的缺点,我认为讲的很好:

MobileNet
v1
论文:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
相比于SqueezeNet,本文是在卷积层面进行了修改。本文提出了使用可分离卷积来代替传统卷积。可分离卷积已经有很多博客讲过了,总体思想就是:
首先对于输入的feature map的每个通道单独看待,把整个M个通道的feature map看做为M个1通道的feature map。每一个feature map配一个3x3的卷积核去处理,可以得到M个1通道的feature map。然后再使用具有N个M通道的1x1的卷积核对整个feature map改变维度,改变为N个通道。
这样子做的好处,可以减少参数量和计算量。计算量的减少比率如下:
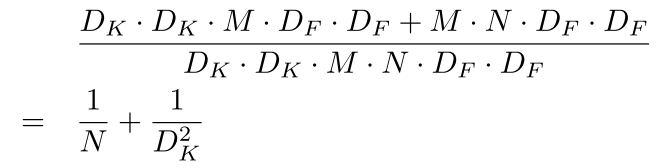 N是输出feature map的通道数,在[32,1024]变动, D k D_k Dk是卷积核的边长,就是3,所以减小的比率基本就是1/9。
N是输出feature map的通道数,在[32,1024]变动, D k D_k Dk是卷积核的边长,就是3,所以减小的比率基本就是1/9。 文章还提出了Width Multiplier,就是每层feature map通道数变少,叫做thinner model,在ablation study中发现,thinner model要比浅层网络在差不多的计算量和参数量的情况下效果要好。
更好的是相比于SqueezeNet,计算量少,效果好。
It is also 4% better than Squeezenet [12] at about the same size and 22× less computation.v2
贴个,我认为这个讲的很好。
这里记录一下我自己的想法。文章中的insight表示为下图:
 低维空间中的兴趣流型先转到n维空间做relu再转回来,当n小的时候,信息丢失的就比较多。
低维空间中的兴趣流型先转到n维空间做relu再转回来,当n小的时候,信息丢失的就比较多。 那么,如果想要兴趣流行保持在低维空间中,本文构造module,先用1x1升维,relu;然后再用3x3做分离卷积提取特征,做relu;然后再用1x1降维到低维空间。既然relu在低维空间做会丢失信息,索性最后一个1x1之后就不用relu了。本文叫做linear bottleneck。
然后再加入ResNet的计算残差的shortcut,新module就成了Res module。但新module不同于ResNet中的输入输出tensor维度高,中间维度低,本文中形成的是中间tensor维度高,输入输出维度低。所以叫做Inverted Residuals。
然后把这些module串联起来,就形成了MobileNetv2.
ShuffleNet
v1
论文:ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
我对于ShuffleNet的理解是联系了ResNeXt和MobileNetv1的。
先说说ResNeXt和MobileNet:ResNeXt和MobileNetv1都是对3x3的那个卷积层做了计算量的缩减。ResNeXt是将3x3进行了分组卷积,而MobileNetv1则更彻底,提出了可分离卷积,实际上ResNeXt的分组,每组只有1个channel,就是可分离卷积了。
从ResNet,沿着上述两种想法走,分组卷积走到了ResNeXt,可分离卷积走到了MobileNet。既然MobileNet计算量减少的更多,那就索性把ResNet中3x3的都给换成可分离卷积。到了这一步,ResNet哪里还可以在减少参量?那就1x1呗。作者发现,在一个ResNeXt中的residual unit,1x1的计算,占了大量的乘加操作,作者给的比例是93.4%。
那怎么减少1x1计算量啊?分组卷积或者可分离卷积呗。可分离卷积就不要想了,如果1x1也用了可分离卷积,那么channel间的联系就被彻底切断了。那就可分租卷积呗,把1x1的运算用分组做。这就出现了问题了:例如,把全部的1x1的都用group=3的分组卷积做,那么其实这三组之间也没有channel之间的connection了。这时,就该做channel shuffle了:
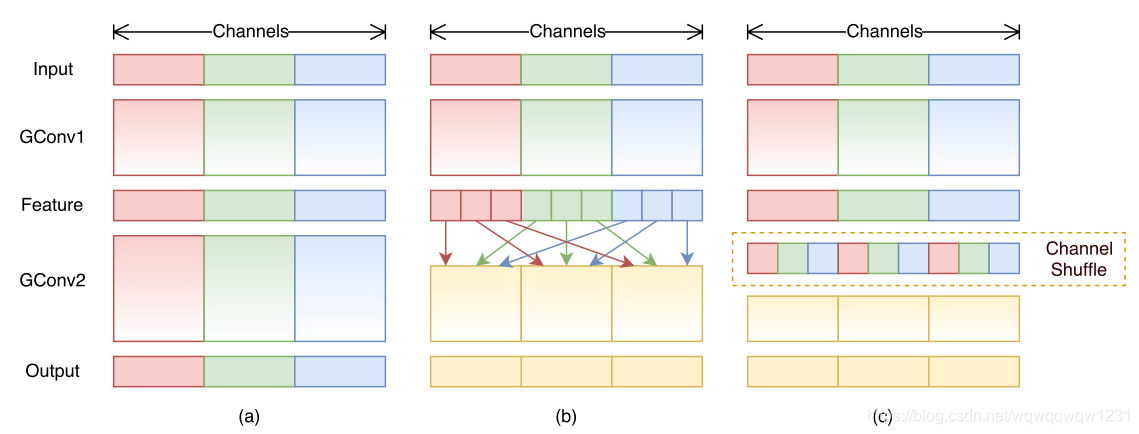 a)是全部都是分组卷积,会出现没有channel之间的交流的情况。b)和c)就是提出的channel shuffle了,恢复了channel之间的联系。
a)是全部都是分组卷积,会出现没有channel之间的交流的情况。b)和c)就是提出的channel shuffle了,恢复了channel之间的联系。 这样就再次减少了1x1的计算量。文中提出,对于 c × h × w c \times h\times w c×h×w的输入,bottleneck channels是 m m m的超参配置,ResNet是 h w ( 2 c m + 9 m 2 ) hw(2cm+9m^2) hw(2cm+9m2),那么其实如果用可分离卷积替换3x3卷积,可以变成 h w ( 2 c m + 9 m ) hw(2cm+9m) hw(2cm+9m),那么再对1x1进行分组,可以变成 h w ( 2 c m / g + 9 m ) hw(2cm/g+9m) hw(2cm/g+9m)。
v2
ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design
该文章写的很长,很详尽,最终效果好。这里就好详细记录一下。
首先作者提出,使用FLOPs这个度量只是表示模型的乘加操作数量,并不能很好的表示模型实际的运算速度。文章中着重分析的是memory access cost(MAC)。由下图可以看到,FLOPs其实只能代表Conv操作的计算时间,其他操作的运算时间是被忽略的:
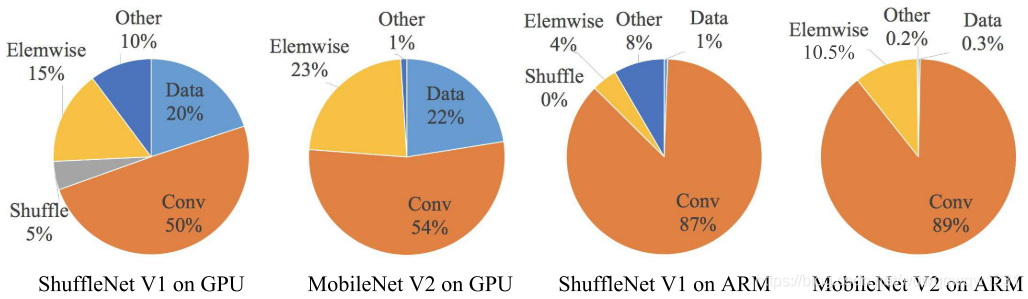
作者对于网络运算速度进行了分析,得到了四条设计指导:
G1)输入和输出的通道数尽可能相等:对于一个 h × w × c 1 h \times w \times c_1 h×w×c1的feature map,对其做1x1的Conv,输出为 c 2 c_2 c2个通道数,则FLOPs为 h w c 1 c 2 hwc_1c_2 hwc1c2。但内存访问是 M A C = h w ( c 1 + c 2 ) + c 1 c 2 MAC=hw(c_1+c_2)+c_1c_2 MAC=hw(c1+c2)+c1c2,第一项是输入输出的tensor的显存访问数,后一项是卷积权重的显存访问操作数。那么在给确定FLOPs的情况下,要减少MAC,就需要 c 1 c_1 c1和 c 2 c_2 c2尽可能的接近。 G2)分组卷积会增加MAC:这个可以从直观上理解,就不放公式了。分组卷积可以在输入输出通道数不变的情况下降低FLOPs,那么对于一定的FLOPs,分组卷积可以提升输入输出的通道数,这就增加了MAC G3)Network fragmentation降低了并行性:这一段我没有看太懂,我认为结论就是保持ResNet这种简单结构比较好 G4)Element-wise operations不可忽略:比如shorcut,ReLU,element-wise addition这种操作的耗时不可忽略。这里我对G2的设计有点异议:分组卷积的设计就是为了减少FLOPs,从最终的效果上看来,还有可以提高精度。固定FLOPs来对比时间消耗这种实验感觉并没有很好,因为固定FLOPs,使用分组卷积可能要比不使用分组卷积效果好,但时间上会增加。所以没有办法很好的展现精度和效率的tradeoff。
接下来就是网络设计:
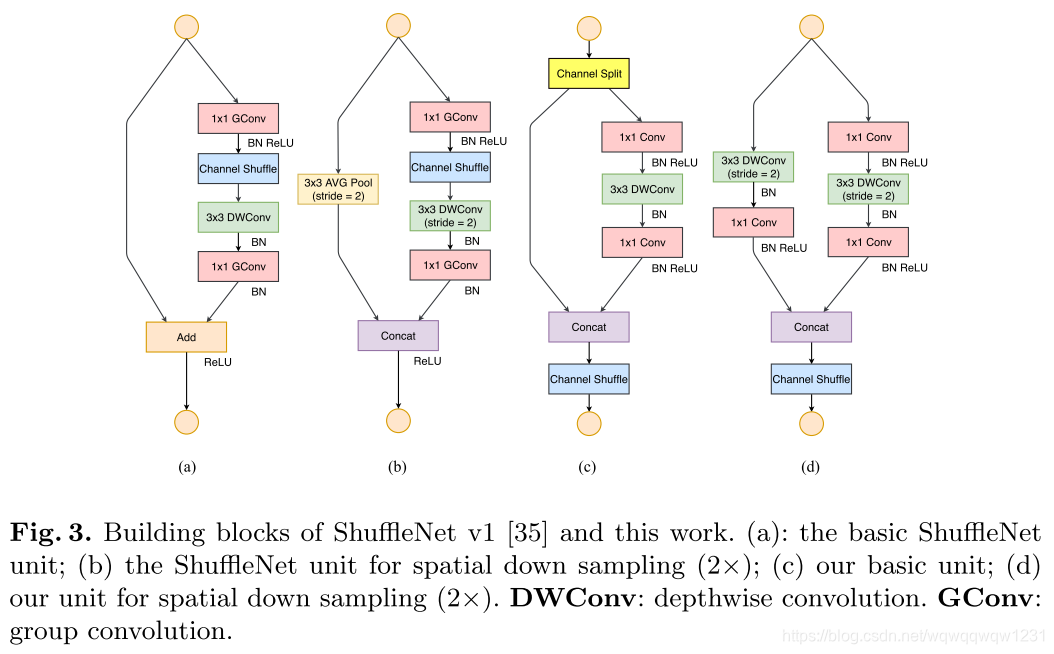 相比于ShuffleNetv1来说,v2是将ResNet的方式改成了DenseNet的方式。Channel Split将channel一分为二,一份走shortcut,一份走卷积,然后concat起来,然后做channel shuffle。实验结果证明了ShuffleNetv2的有效性,而且从对比中可以看出本文提出的几条指导意见还是符合大多数网络。
相比于ShuffleNetv1来说,v2是将ResNet的方式改成了DenseNet的方式。Channel Split将channel一分为二,一份走shortcut,一份走卷积,然后concat起来,然后做channel shuffle。实验结果证明了ShuffleNetv2的有效性,而且从对比中可以看出本文提出的几条指导意见还是符合大多数网络。 这里贴一个讲v2的博客,讲的详细一些:https://blog.csdn.net/u014380165/article/details/81322175
转载地址:https://blog.csdn.net/wqwqqwqw1231/article/details/113604191 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
