本文共 2672 字,大约阅读时间需要 8 分钟。
文章目录
论文链接:https://arxiv.org/abs/2103.07461
代码链接:https: //github.com/xingyizhou/CenterNet2其实一句话就可以概括本文的核心思想:用one-stage的检测器来代替two stage中的RPN可以提升运行速度和检测效果。
对于two-stage的RPN和one-stage的检测器,我一直认为其实它们俩本质上就是同一个东西。但这只是从网络架构的形式上看。本文细节地分析了两者的区别。
其中,3和4两个section阐述了本文的核心思想,第5个section只是描述实现细节。
3. Preliminaries
现有的检测器分为两类,一个是one-stage的,一个是two-stage的。
先说one-stage:使用 L i , c L_{i,c} Li,c表示对第i个candidate和c类别的检测结果,其中candidate可以理解为feature map中的grid。那么 L i , c = 1 L_{i,c}=1 Li,c=1代表第i个candidate检测为c类别, L i , c = 0 L_{i,c}=0 Li,c=0代表第i个candidate检测为背景。大多数的one-stage的检测器parametrize the class likelihood为 s i ( c ) = P ( L i , c = 1 ) s_i(c)=P(L_{i,c}=1) si(c)=P(Li,c=1)。在训练过程中,就是对gt box最大化这个的对数似然, l o g ( P ( L i , c ) ) log(P(L_{i,c})) log(P(Li,c))。
two-stage:two-stage的检测器分为两步,第一步使用RPN尽可能找出proposal,使用objectness P ( O j ) P(O_j) P(Oj)来描述。然后对每个proposal提取特征,在proposal上进行分类,预测 P ( C i ∣ O i = 1 ) P(C_i|O_i=1) P(Ci∣Oi=1), C i C_i Ci的取值是所有类别加上背景类。**但对于two-stage的检测器来说,RPN的设计要求是高recall,进可能找到所有物体,所采取的方法则是与gt有IoU>0.3的就认为是前景类。**这种提取的proposal是有大量冗余的,而且如果使用最终的检测评价来看(比如IoU>0.7才是前景类),很多proposal其实属于背景类。而且,two-stage的方法的最终检测仅依赖 P ( C i ∣ O i = 1 ) P(C_i|O_i=1) P(Ci∣Oi=1),也就是最终检测不依赖第一阶段的概率分布(这一块会在后面再说)。
4. A probabilistic interpretation of two-stage detection
最终输出的概率理论上应该如下,o的选取是{0,1}:
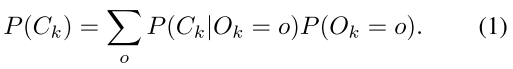 对于前景类,要最大化的似然估计是:
对于前景类,要最大化的似然估计是: 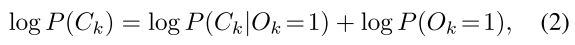 对于背景类,要最大化的似然估计是
对于背景类,要最大化的似然估计是 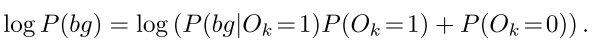
这里先说一下以前的two-stage网络(例如FasterRCNN)采用的方法是:分别在one-stage和two-stage最大化 l o g ( P ( O k = 0 ) ) log(P(O_k=0)) log(P(Ok=0))和 l o g ( P ( b g ∣ O k = 1 ) ) log(P(bg|O_k=1)) log(P(bg∣Ok=1))。那这么一看,说是把最大化 l o g ( A + B ) log(A+B) log(A+B)变成最大化 l o g ( A ) log(A) log(A)和 l o g ( B ) log(B) log(B)也还能理解,但其中的 P ( O k = 1 ) P(O_k=1) P(Ok=1)这一项其实也丢了。之前的two-stage网络是完全的解耦了两个stage,在训练第二个stage的时候,认为所提取的proposal的 P ( O k = 1 ) = 1 P(O_k=1)=1 P(Ok=1)=1。其实这也好理解,因为one-stage就是一个分类任务,分类就是前景类和背景类,那如果训练的好,那可不就是 P ( O k = 1 ) = 1 P(O_k=1)=1 P(Ok=1)=1。
本文使用Jensen不等式,将 l o g ( P ( b g ) ) log(P(bg)) log(P(bg))转成了两个下界:
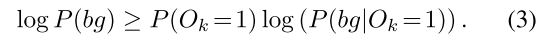
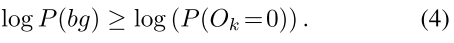
那么在第二个和第一个stage分别最大化这两个下界。第一个stage最大化公式(4)这其实没变,但第2个stage最大化(3)则需要知道 P ( O k = 1 ) P(O_k=1) P(Ok=1)。这就引到了Detector design。这里就直接放原文了:
 就是说,根据公式(1),而且最大化公式(3)需要知道 P ( O k ) P(O_k) P(Ok),所以第一个stage不能说是只是以高recall为目标,而应该是以准确预测objectness为目标,所以需要一个one-stage detector作为第一阶段。
就是说,根据公式(1),而且最大化公式(3)需要知道 P ( O k ) P(O_k) P(Ok),所以第一个stage不能说是只是以高recall为目标,而应该是以准确预测objectness为目标,所以需要一个one-stage detector作为第一阶段。 看到这里,我有个疑问:
对于公式(2)的下界的求取用了Jensen不等式,但其实根据概率不为负数,而且log单调递增,可以轻松将公式(2)找到两个下界: l o g ( P ( O k = 0 ) ) log(P(O_k=0)) log(P(Ok=0))和 l o g ( P ( O k = 1 ) P ( b g ∣ O k = 1 ) ) log(P(O_k=1)P(bg|O_k=1)) log(P(Ok=1)P(bg∣Ok=1))。其实最大化这两个下界和最大化(3)和(4)是没区别的。但这涉及到如何设计loss,不知道把 P ( O k = 1 ) P(O_k=1) P(Ok=1)放入log里面有没有什么影响。soft label能提高检测效果。我认为,其实将第一阶段改为one-stage detector其实和在第一阶段使用soft label想法非常相似。
6、Results
实验效果很好,其中Ablation studies中的第一个实验很有说服力:如果不把第一阶段做改变,把输出的概率直接乘到第二阶段上,并没有很好的提升。说明如果第一阶段不是很strong的话,不能给出一个合适的objectness的预测。
转载地址:https://blog.csdn.net/wqwqqwqw1231/article/details/115285808 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
