本文共 1703 字,大约阅读时间需要 5 分钟。
文章目录
文章:Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection
2020 CVPR 论文地址:https://arxiv.org/abs/1912.02424 代码地址:https://github.com/sfzhang15/ATSS文章写的是真漂亮!!!
Anchor s Anchor Free
文中提出,anchor based的方法和anchor free有以下三个区别:
- 1)每个位置的anchor数量:anchor based的方法每个位置有多个anchor,anchor free的方法每个位置只有一个anchor point
- 2) 正负样本的定义:anchor based的方法根据anchor和GT的IoU定义正负样本,anchor free的方法根据空间位置和GT的scale定义
- 3) 框回归的起始状态:anchor based的方法是回归GT框与anchor的残差,anchor free的方法则是回归anchor point到四个边的距离
有了以上三个区别,文章就要分析,到底是哪个因素影响了Anchor based的和Anchor free的性能差别了呢?
作者选取了RetinaNet(anchor based)和FCOS(Anchor Free)的方法作对比。
RetinaNet Vs FCOS
看RetinaNet和FCOS的结构,都非常简单,而且相似。作者先不讨论第一区别的影响,先讨论后两个。所以先将RetinaNet的anchor的数量设置为1,记作RetinaNet(#A=1),anchor大小为8S。这样RetinaNet(#A=1)的性能下降到32.5%,与FCOS的37.8还有很大差距。但此时,FCOS其实还有很多Trick在里面,当把这些trick加入到RetinaNet(#A=1)中,RetinaNe(#A=1)t的性能上到了37.0,仍然有些差距。但目前来看,两者网络一模一样了,区别只能是在anchor based和anchor free的差别了,也就是上述的前两个问题。
针对2)和3)问题,作者做了实验。2)是在说怎么确定正负样本,3)是在说用anchor box还是anchor point去回归框。这里,会觉得,没有anchor box怎么能用IoU的方式确定正负样本呢?
其实,这两个问题可以分开看。2)是怎么说确定正负样本,即便用了anchor确定正负样本,仍然可以用anchor point的方式回归框。
于是,作者做了四个实验,分别对应2)和3)问题的两种组合。
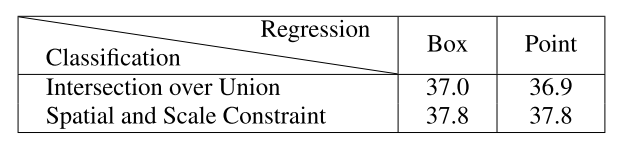 于是发现,如何确定正负样本才是关键,如何回归框不重要。
于是发现,如何确定正负样本才是关键,如何回归框不重要。 ATSS
有了上述发现,作者提出一个自适应确定正负样本的方法:

上述方法结合IoU和center确定正样本的框,而且IoU的阈值是自适应的。而且确定了每个特征图上最多9个框。
而且可以起到,当一个特征图特别适合预测某一个物体,该物体的 v g v_g vg会很大,使得 t g t_g tg也大,使得只有这个特征图有正样本,其他scale的特征图为负样本。反之,并没有一个特征图特别适合预测某个物体,该物体的IoU分布就会比较平均, m g m_g mg会小,使得 t g t_g tg也小,使得多个特征图上都会有正样本。
实验
超参数
ATSS中还有两个超参数,一个是每个物体每层特征图上要有几个候选样本k,一个是anchor的大小。作者发现这两个参数都很鲁棒。
Comparison
作者用了更复杂的backbone,用了DCN,用了multi-scale test等trick,将效果刷到了极致
Discussion
到现在,anchor based和anchor free还有一个问题没解决,那就是anchor可以有多个尺寸和长宽比的框。作者做了实验发现,如果用了ATSS,多种anchor还不如用1种。至此,一开始提的问题就都解决了。
转载地址:https://blog.csdn.net/wqwqqwqw1231/article/details/117966662 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
