本文共 3519 字,大约阅读时间需要 11 分钟。
文章目录
range view是仅针对物理旋转式扫描的激光雷达的特殊view,例如velodyne64线,128线都是。具体,旋转式扫描的激光雷达都是在水平方向进行旋转,竖直方向为固定个数的激光传感器,传感器的个数是和激光雷达线数是一样的。这样的扫描方式,使得该类型的激光雷达扫描出来的坐标系实际是一个柱坐标系,在水平和竖直方向都是有固定角分辨率的。用水平和竖直方向的角度信息,可以准确的检索到点云中的每一个点。所以整个点云可以用水平和竖直方向的角度来稠密表示,从而形成range view的表示方法。
range view在3D语义分割上用的比较成熟,例如RangeNet,但在3D目标检测上面,和主流的在BEV下左检测的网络,效果差距比较大。今年,新出来几篇在使用range view上做检测的文章。
先说结论:直接在range view上使用Conv2D提取特征有限,无法满足3D Object Detection。
BEV or Range View
| BEV | Range View | |
|---|---|---|
| 是否需要栅格化 | 需要 | 不需要 |
BEV:
- 优点:物体尺寸变化不大,物体之间没有遮挡,相对位置关系为3维空间
- 缺点:需要进行栅格化,信息稀疏
Range view:
- 优点:不需要栅格化,信息稠密
- 缺点:物体近大远小,物体之间遮挡
RangeDet: In Defense of Range View for LiDAR-based 3D Object Detection
出自图森
文中认为,range view效果不行的因素有三个:
- range view中物体尺寸变化大
- range view中的卷积是在2D pixel coord,而物体检测要在3D space,这两者之间有差距
- range view中提取的特征更紧密,但如何有效利用这种特征,其他range view的方法并没有考虑
针对上述三个因素,本文提出了相对应的3个改进
Range Conditioned Pyramid In
近大远小的问题,更通用的一种问题就是物体scale大小不同,在主流的2D目标检测网络上,使用的FPN的结构,对scale大小不同的物体做分治策略的检测。那这种分治的策略,将不同物体放置在不同层级的特征图上的方法是根据IoU的。本文提出,按照range来放置,将0-80m的距离分为[0, 15), [15, 30), [30, 80]三个区间,每个区间中的物体用一个特征图来检测。
Meta-Kernel Convolution
作者认为,传统的2D conv中的卷积核的权重是在整feature map上共享的,这样不好。我认为这种理解就是,近处3x3的卷积核覆盖的范围和远处3x3的卷积核覆盖的范围完全不同,使用同样的权重,不太妥当。所以本文提出,将卷积核的权重变得可变起来。
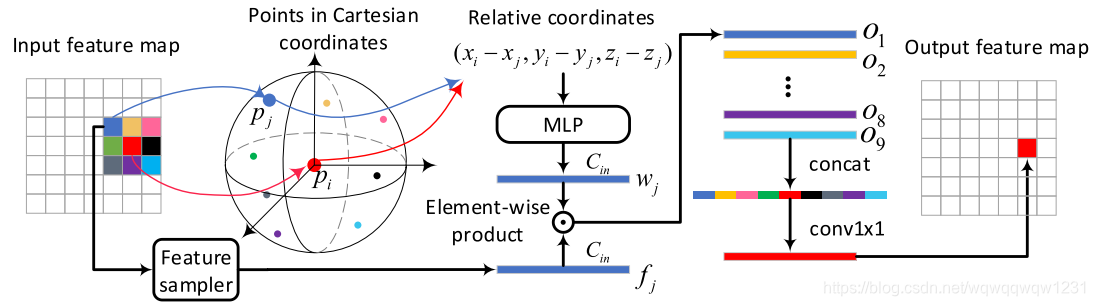
- 根据特征图位置,找到其邻域,其实就是3x3的邻域,并找到其中的点 p j p_j pj
- 根据 p i p_i pi和 p j p_j pj的位置关系,使用MLP计算权重 w j w_j wj
- 权重 w j w_j wj和 p j p_j pj的特征做点乘,得到 O j O_j Oj
- 对3x3的邻域内(包括自己)的9个点均做上述操作,可以得到9个特征。原本的conv2d是采用相加的形式,这里采用concat然后送入MLP中,得到 p i p_i pi卷积后的特征。
读者可以具体对比一下RS-CNN中的RS-Conv,这不就是一模一样的嘛。无非就是邻域的选取有不一样。
Weighted Non-Maximum Suppression
每个pixel都会预测一个box,而一个真实物体可以被很多pixel预测,那么这么多box,用NMS不太好,会浪费这种稠密的信息,不如就用加权平均的方式。
我的理解是,因为BEV中物体偏小,不占几个像素,而range view中物体就还挺大,所以可以用这种方法。
Data Augmentation in Range View Data
range view中不好做data augmentation,尤其是copy&paste这种数据增广,还有点难的。
Experiment
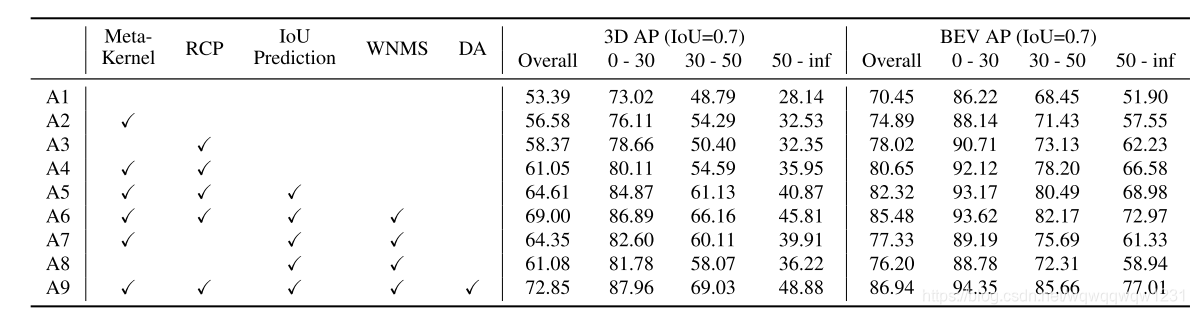
- Meta-Kernel带来的提升,可能说明conv2d不适合在range view上提取几何特征
- RCP带来的提升如此之大,让我觉得A1到底有没有用FPN啊,这个文章中我也没找到A1的具体定义
其他结论,可以看看文中具体所述
To the Point: Efficient 3D Object Detection in the Range Image with Graph Convolution Kernels
waymo团队做的,2021CVPR
思路与上一篇很类似,只不过是提出了多个kernel。这里就不全部介绍kernel了,只是讲个大概思路
Kernels
原文中写道:
“Therefore, it cannot reason about the underlying geometric pattern of the neighborhood. Next, we will present four kernels that can leverage this geometric pattern.”Range-quantized (RQ) 2D convolution kernel
kenel的定义如下:
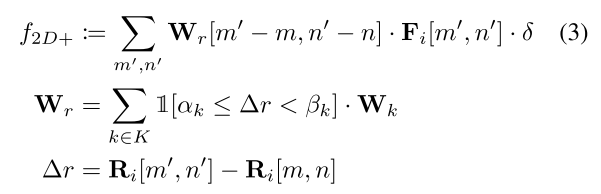 其中,[m,n]是卷积核中心的位置,[m’,n’]是[m,n]领域内的其他位置。
其中,[m,n]是卷积核中心的位置,[m’,n’]是[m,n]领域内的其他位置。 权重Wr的取值是根据邻域内深度差来决定的,中心思想就是深度差不同,要用不同的卷积核。原来的每个Conv2D变成了一组权重,每次都根据深度差进行选择。
PoitnNet kernel
定义如下:
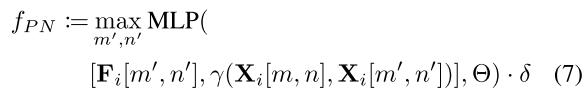 其中, γ \gamma γ是用来计算[m,n]和[m’,n’]具体3D位置的函数,具体如下:
其中, γ \gamma γ是用来计算[m,n]和[m’,n’]具体3D位置的函数,具体如下: 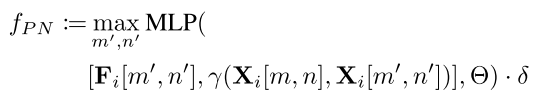
EdgeConv kernel
具体定义如下:
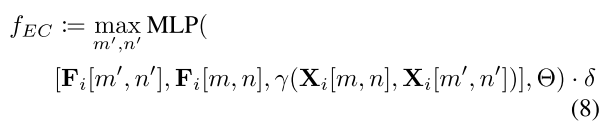 可以看到,EdgeConv kernel也是point-based的一种,很熟悉
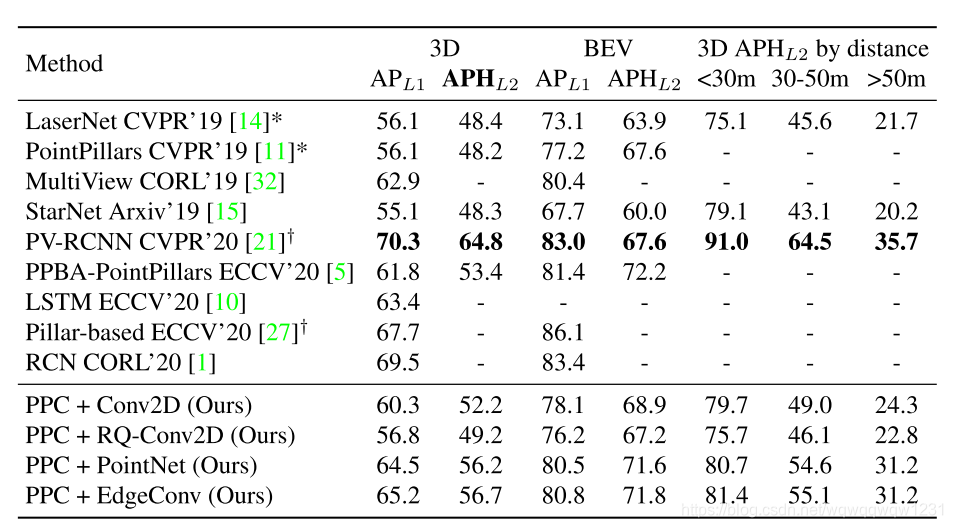
可以看到,EdgeConv kernel也是point-based的一种,很熟悉 Experiment
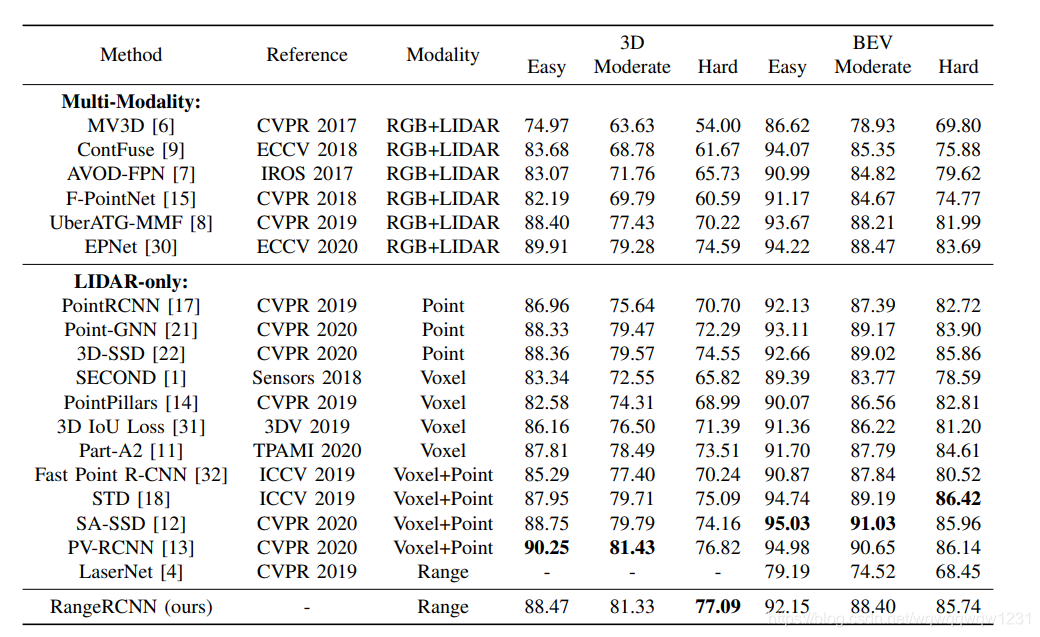
RangeRCNN: Towards Fast and Accurate 3D Object Detection with Range Image Representation
海康出品
Network
网络结构图如下: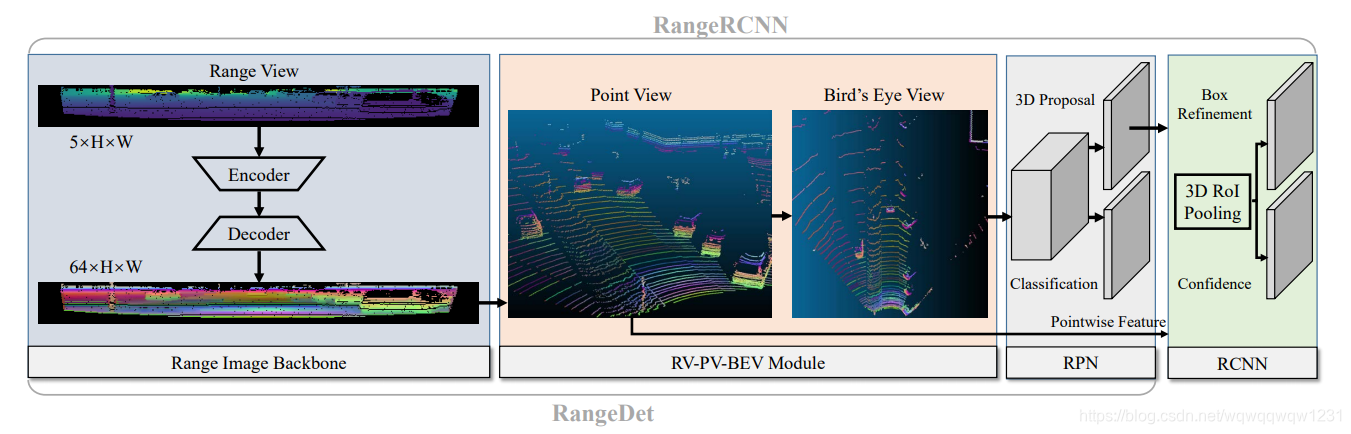
Experiment
结论
1、从RangeDet和To the Point两篇论文来看:在range view中直接做3D目标检测,需要在kernel级别来从xyz维度上提取特征,仅使用Conv2D在depth上提取特征不够充分。
2、从RangeRCNN来看:结论不明显
- 因为在BEV上也做了特征提取,用了3个Conv block,不清楚到底这3个block起到多少的作用,可以做个ablation study,将BEV上的卷积去掉,直接使用pooling之后的特征做检测,看看效果。
- 最终用来做检测的feature map中grid的大小为0.32m*0.32m,特征图的分辨率大,并且没有给出在小目标pedestrian上的结果,并不能说明range view上提取特征不损失信息的好处(因为我理解是voxel在pedestrian的损失是要大于car的,To the Point中的实验部分说明了这个问题)。
转载地址:https://blog.csdn.net/wqwqqwqw1231/article/details/118438560 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
