【代码阅读】YOLOv3 Loss构建详解
图1 YOLOv3 ssp 网络框架
发布日期:2021-09-16 07:31:57
浏览次数:2
分类:技术文章
本文共 1419 字,大约阅读时间需要 4 分钟。
目录
Yolov3
YOLOv3 是YOLO系列目前最新的网络结构,YOLO系列可以说是打破了以FasterRCNN为例的two-stage框架的一统天下的局面。已经有很多博文介绍了,github上也有很多开源代码,这里我推荐一个和。
但对于一个神经网络来说,另一个重要的部分是Loss的构建。大多数文章关注于网络框架的搭建,忽略了Loss构建,使得读完之后虽然知道了网络的输出,但不知道这些输出到底对应着什么,从而很难理解网络具体的含义。本文就详细阐述YOLOV3的Loss的构建网络框架
要讲Loss,就不得不讲网络的输出,这里我们略讲一下。具体可以参考
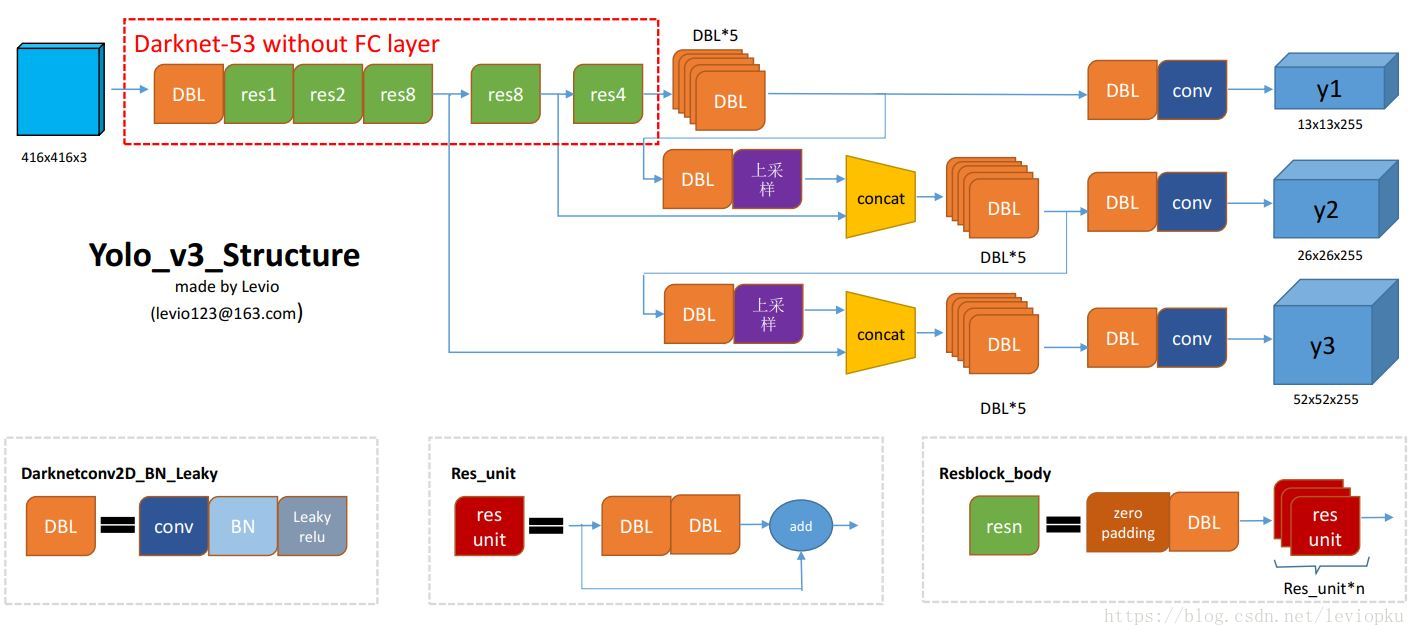
可以看到,YOLOv3的输出是有3个:y1,y2,y3。分别对应不同的分辨率的feature map。
Loss构建
首先理解一下网络的输出。以y1为例,y1的输出为13*13*255,表示整张图被分为13*13个格子,每个格子预测3个框,每个框的预测信息包括:80个类别+1个框的置信度+2个框的位置偏差+2个框的size偏差。输出可以理解为是13*13*(3*(80+1+2+2))。具体可见
接下来就归入正题,来看Loss构建过程。
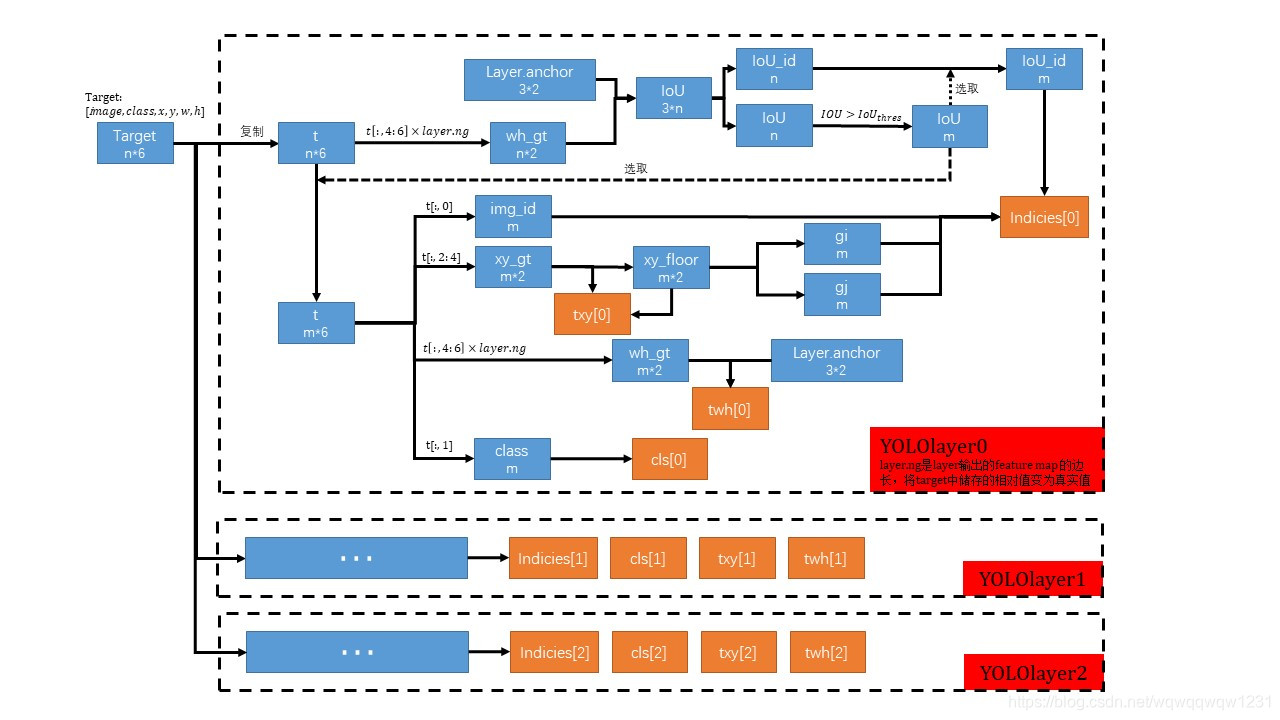
1、选取box(n个)长宽的真值wh_gt
2、通过与anchor比较,计算IoU,抛去IoU小于一定阈值的框(说明这些框不适用该尺寸的feature map进行预测),留下IoU大于阈值的框(m个)。以下操作均对留下的框(m个)进行操作(虚线代表的“选取”过程,选取留下的框)
3、提取框位置的真值,并与取整之后的值比较,这个取整后的值对应着feature map中的位置,计算位置偏差的真值(txy)。
4、提取框尺寸的真值,并与对应的anchor的尺寸比较,计算尺寸偏差的真值(twh) 5、记录框的类别真值(cls) 6、记录留下的框对应anchor的id和对应图片的id, 位置取整后的值,这个取整后的值代表着是用13*13中的哪个格子进行预测。(indicies)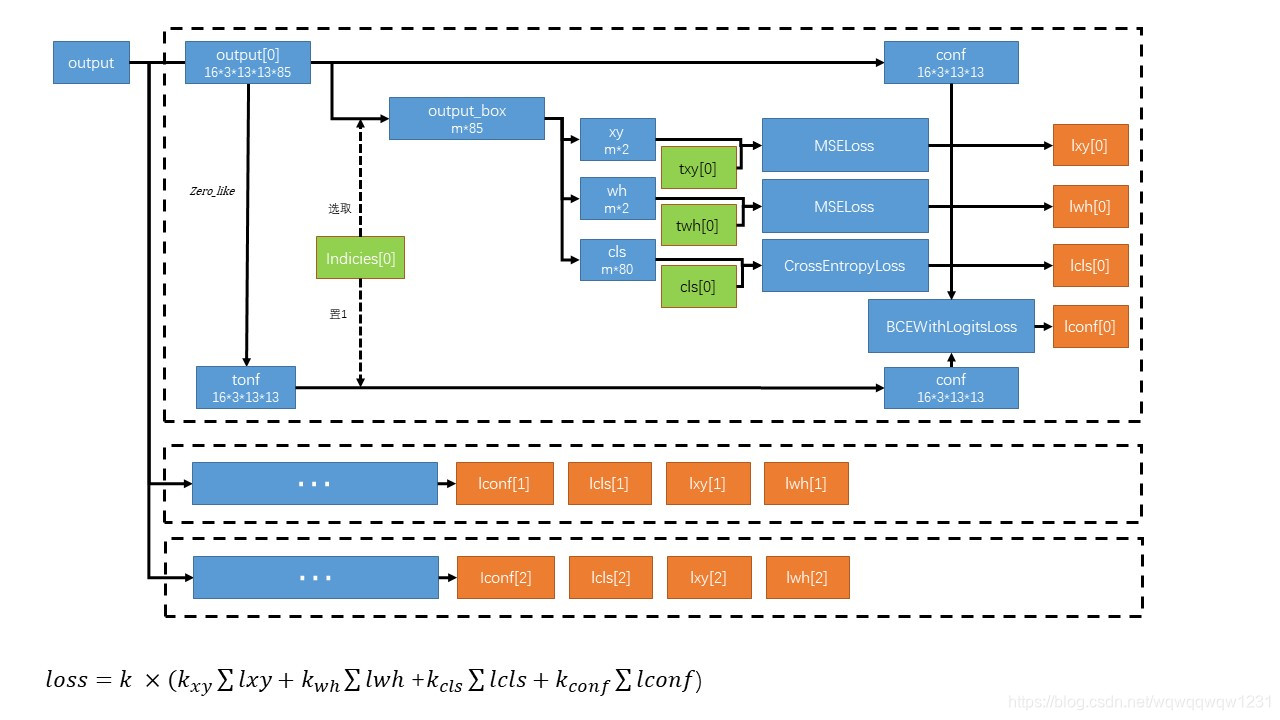
如果有没有写清楚的地方,欢迎留言。我会进行修改!
转载地址:https://blog.csdn.net/wqwqqwqw1231/article/details/90667046 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
网站不错 人气很旺了 加油
[***.192.178.218]2024年04月16日 04时51分35秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
配置MySQL主从复制
2019-04-27
CI框架如何删除地址栏的 index.php
2019-04-27
expires与etag控制页面缓存的优先级
2019-04-27
取消掉Transfer-Encoding:chunked
2019-04-27
HTTP协议中的Tranfer-Encoding:chunked编码解析
2019-04-27
JavaScript面向对象编程
2019-04-27
在Javascript中使用面向对象的编程
2019-04-27
由浅入深剖析.htaccess
2019-04-27
php函数serialize()与unserialize()
2019-04-27
PHP Webservice的发布与调用
2019-04-27
php反射类 ReflectionClass
2019-04-27
php扩展xdebug基本使用
2019-04-27
为 PHP 应用提速、提速、再提速
2019-04-27
Linux下gedit显示行号
2019-04-27
《Advanced PHP Programming》读书笔记
2019-04-27
让我们谈谈RAID
2019-04-27
jQuery日期选择器插件date-input
2019-04-27
PHP使用curl_multi_add_handle并行处理
2019-04-27
NP问题
2019-04-27
AT&T与Intel汇编语言的比较
2019-04-27
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 307976313 位访客
访问时间: 2024-04-26 05:20:23
访问IP: 3.139.104.214
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版