本文共 7870 字,大约阅读时间需要 26 分钟。
目录
课程链接
课程主页:http://cs231n.stanford.edu/syllabus.html, 包括笔记、ppt和代码
2017课程:https://study.163.com/course/courseMain.htm?courseId=1004697005 2016课程:https://study.163.com/course/courseMain.htm?courseId=1004697005 code:http://cs231n.github.io/图像分类 Image Classification
图像分类问题的挑战来自于以下几个方面:
- 视角变化
- 尺度变化
- 变形
- 遮挡
- 光照变化
- 识别物体与背景类似
- 同一类中物体之间差异很大

NN & KNN
介绍了Nearest Neighbor Algorithm和K-Nearest Neighbor Algorithm。K起到平滑作用,K越大,越能抑制离群点。这两种方法不用训练,但在推断过程慢。适合低维数据,不适合用于图像分类。
Validation Set是用来调整超参数的。Linear Classification
主要由Score Function 和 Loss Function 构成。
Score Function
通过线性变换得到图片是某类的score:
 对于CIFAR-10来说,有10个类别,每张图片为3x32x32=3027的大小,所以W的维度为10x3027,可以将W认为是10个Linear Classifier,每一行是一个独立的Classifier。 强调了数据处理的重要性,对于图片,一般要进行0均值。
对于CIFAR-10来说,有10个类别,每张图片为3x32x32=3027的大小,所以W的维度为10x3027,可以将W认为是10个Linear Classifier,每一行是一个独立的Classifier。 强调了数据处理的重要性,对于图片,一般要进行0均值。 Loss Function
Multiclass Support Vector Machine Loss:又被称为 Hinge Loss。惩罚函数与那些 score > (真值的类的score-阈值) 的类有关

Regulation 正则化
一方面原因是W是可以缩放,另一方面考虑模型的泛化性能,加入正则化项。常用的有L1和L2,L1会使权重稀疏,L2会出现max margin property(目前还没有搞太清楚)。 正则化的另一种解释是,光滑权重,使得分类器尽可能考虑更多输入数据的信息。以下图为例
Softmax Classifier
也属于线性分类器,无非是Loss函数使用Softmax函数。 Softmax Loss与Hinge Loss区别在于,Softmax对于所有错误的类进行惩罚,无论其分数多低。
Softmax Loss与Hinge Loss区别在于,Softmax对于所有错误的类进行惩罚,无论其分数多低。 线性分类器可视化链接:http://vision.stanford.edu/teaching/cs231n-demos/linear-classify/
Optimization
SGD:Stochastic Gradient DescentBack Propagation
在BP中,乘法操作会有交换梯度的感觉。例如 f(x,y)=xy, ▽f = [y, x]。当x>>y时,x方向的梯度<<y方向的梯度,这意味着较小值对应较大的梯度,而较大值对应较小的梯度。在神经网络中,x代表权重,y代表输入的数据。当y增大100倍时,x的梯度也会增大100倍,这样就需要减小学习步长。这就是要数据进行预处理的一个原因。 Vector, Matrix, and Tensor Derivatives:http://cs231n.stanford.edu/vecDerivs.pdf
Vector, Matrix, and Tensor Derivatives:http://cs231n.stanford.edu/vecDerivs.pdf Tips:在做乘法的BP中,可以用维度来快速确定左右乘和转置
 Backpropagation for a Linear Layer的证明:http://cs231n.stanford.edu/handouts/linear-backprop.pdf
Backpropagation for a Linear Layer的证明:http://cs231n.stanford.edu/handouts/linear-backprop.pdf 神经网络
卷积
激活函数
Sigmoid
(-)存在大量的饱和区,梯度几乎为0。 (-)不是0中心,输出全部为正值。对于多层的 f = wx+b,经过激活,x全部为正值,所以网络中w的梯度要么全为正或者全为负。用batch的训练可以缓解这个问题。tanh
(-)仍然存在大量饱和区 (+)0中心ReLU
(+)结构简单,容易加速 (-) 非0中心 (-) 存在死节点:Unfortunately, ReLU units can be fragile during training and can “die”. For example, a large gradient flowing through a ReLU neuron could cause the weights to update in such a way that the neuron will never activate on any datapoint again. If this happens, then the gradient flowing through the unit will forever be zero from that point on. That is, the ReLU units can irreversibly die during training since they can get knocked off the data manifold. For example, you may find that as much as 40% of your network can be “dead” (i.e. neurons that never activate across the entire training dataset) if the learning rate is set too high. With a proper setting of the learning rate this is less frequently an issue.Leak ReLU
(+)解决dying ReLU的问题Exponential Linear Units (ELU)
(+)近似零均值权重初始化
权重的初始化在Batch Normalization提出之前是一个比较头疼的问题。BN出现之后,这个问题得到很大的缓解,这里直接列出可以采用的初始化方式。
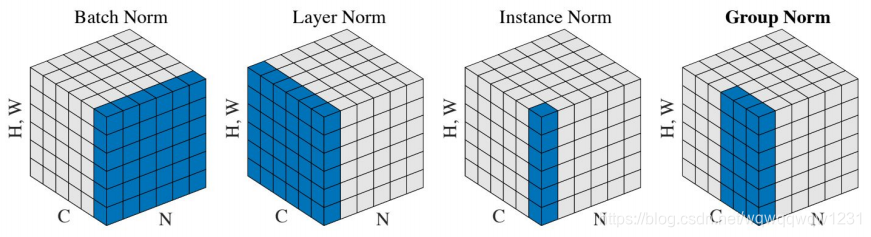
 还有其他Normalization的方式
还有其他Normalization的方式 - Layer Normalization:Ba, Kiros, and Hinton, “Layer Normalization”, arXiv 2016
- Instance Normalization:Ulyanov et al, Improved Texture Networks: Maximizing Quality and Diversity in Feed-forward Stylization and Texture Synthesis, CVPR 2017
- Group Normalization:Wu and He, “Group Normalization”, ECCV 2018
正则化
L2
更偏向于惩罚带有尖峰的权重,更喜欢平坦的权重,有光滑权重的效果。L1
会使得权重稀疏化,在优化过程中,很多权重会趋向于0In comparison, final weight vectors from L2 regularization are usually diffuse, small numbers. In practice, if you are not concerned with explicit feature selection, L2 regularization can be expected to give superior performance over L1.
Dropout
It is most common to use a single, global L2 regularization strength that is cross-validated. It is also common to combine this with dropout applied after all layers. The value of p=0.5 is a reasonable default, but this can be tuned on validation data.
Loss
分类问题
- Softmax Loss
- Hinge Loss
回归问题
- L1 Loss
- L2 Loss
相比于分类Loss,回归Loss更为脆弱,不好优化。

训练前的检查
(1)首先将正则化置零,然后看第一次Loss,判断正确与否
(2)加入正则化,并增加其权重,Loss应该上升 (3)在一个小数据集上,确保模型能够过拟合,以此确保模型表达能力足够
训练中需要关注的点
除了看Loss曲线判断步长是否合适,还需要看tain和val的最终结果。
 还需要注意weights的更新值,大小应该在weight的0.001倍
还需要注意weights的更新值,大小应该在weight的0.001倍 
优化方法
SGD:SGD的Momentum和Nesterov Momentum在Pytorch中都被包含在SGD中,作为输入变量来控制选用哪种优化方法
- Vanilla update
- Momentum update
- Nesterov Momentum:It enjoys stronger theoretical converge guarantees for convex functions and in practice it also consistenly works slightly better than standard momentum.
Second order methods:不常用
- Newton’s Method
- L-BFGS
Per-parameter adaptive learning rate methods:weight中不同的变量learning rate不同,虽然这些方法也会引入新的超参数,但这些超参数在一定程度内是比较鲁棒的,所以这种有些话方法还是有效的解决设置learning rate的问题。
Many of these methods may still require other hyperparameter settings, but the argument is that they are well-behaved for a broader range of hyperparameter values than the raw learning rate.- Adagrad:A downside of Adagrad is that in case of Deep Learning, the monotonic learning rate usually proves too aggressive and stops learning too early.
- RMSprop:在Adagrad基础上加了decay,一般选取[0.9, 0.99, 0.999]
- Adam:像是RMSprop+momentum,参数推荐eps = 1e-8, beta1 = 0.9, beta2 = 0.999
超参数优化
主要优化的超参数:
- the initial learning rate
- learning rate decay schedule (such as the decay constant)
- regularization strength (L2 penalty, dropout strength)
优化要注意的点
- Prefer one validation fold to cross-validation,在one validation fold上做优化即可
- Hyperparameter ranges:要在对数上做优化,例如:learning_rate = 10 ** uniform(-6, 1);警惕最优点在搜索边界,因为这样可能最优值超出了搜索范围;搜索由粗到细,粗搜索进行1个epoch就可以,因为有些参数根本没有办法进行学习,细搜索5个epoch;
CNN 结构
具体结构不在赘述。感觉常用的有VGG16和ResNet
- AlexNet
- VGGNet,
- GoogLeNet,
- ResNet
Detection & Segmentation
CV中研究比较多的四类任务
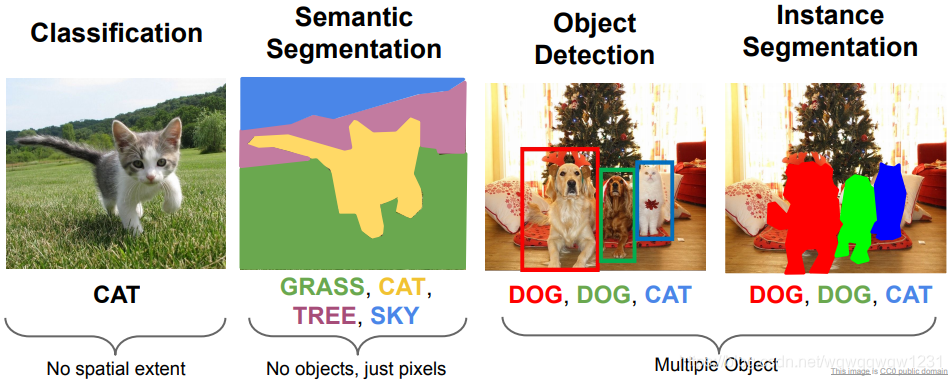
Semantic Segmentation
任务目标:标记每个像素点的label。
最原始的想法,用sliding window,每个sliding window预测其中心位置的label,但问题在于这需要太多次前向运算,速度慢。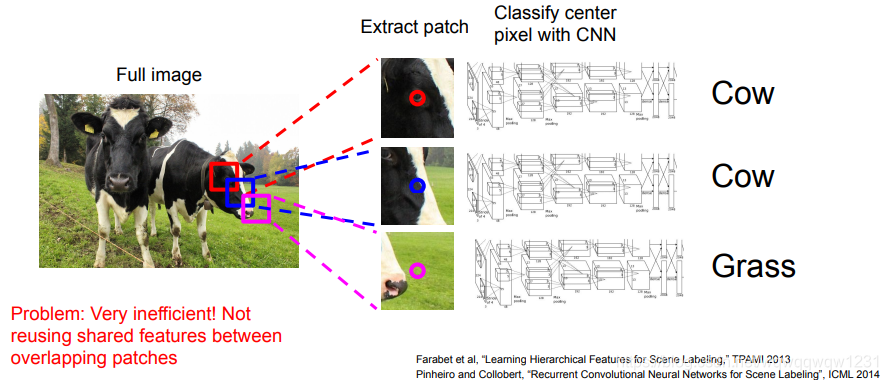 将前向计算统一,使用共同的特征,feature map大小与图像大小相同。问题在于,随着特征尺寸的增大,内存开销太大。
将前向计算统一,使用共同的特征,feature map大小与图像大小相同。问题在于,随着特征尺寸的增大,内存开销太大。 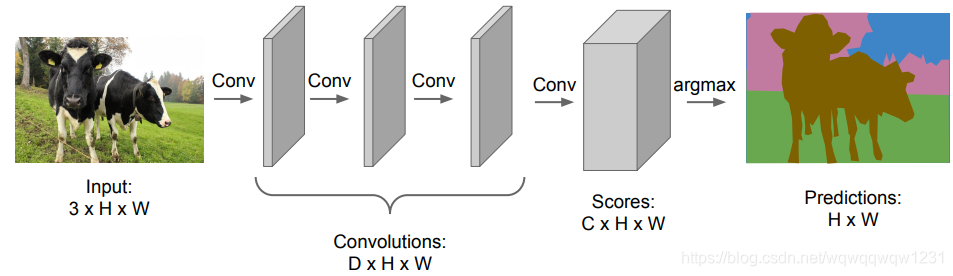 FCN:随着特征尺寸的增大,减小feature map的尺寸,然后在上采样。
FCN:随着特征尺寸的增大,减小feature map的尺寸,然后在上采样。 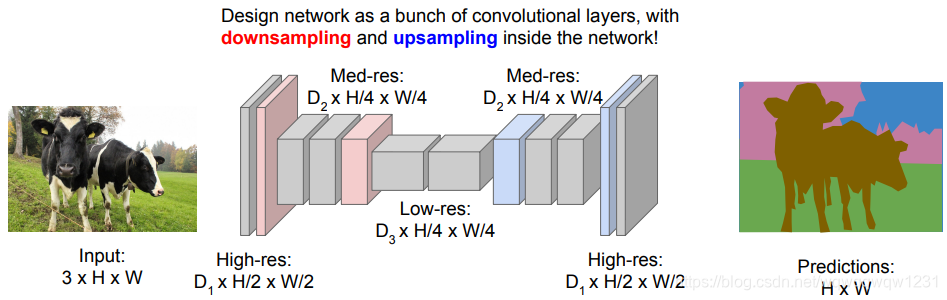 其中就要用到上采样的操作,分别为Unpooling 和 transpose convolution。Unpooling是pooling的反操作,不带用权重,不参与训练,transpose convolution为使用模板的投票操作,带有权重,参与训练。在实际应用中,unpooling后可以跟几层convolution层计算特征。
其中就要用到上采样的操作,分别为Unpooling 和 transpose convolution。Unpooling是pooling的反操作,不带用权重,不参与训练,transpose convolution为使用模板的投票操作,带有权重,参与训练。在实际应用中,unpooling后可以跟几层convolution层计算特征。 Object Detection
Object Detection的问题分为两类Classification+Localization和Multiple Objects Detection。不同点在于前者是知道图片只需要定位一个物体,后者是不知道图片中有多少个物体,也不知道它们所属的类。
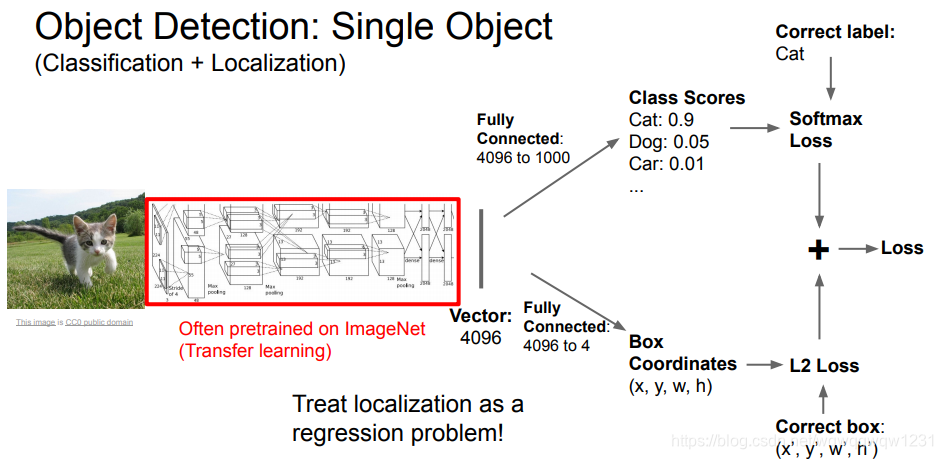
Classification+Localization中额Classification已经在前文叙述了,剩下的Localization看做是一个回归问题。那么思路与Classification一样,得到高层次特征之后,用全连接层做回归即可。
 Multiple Objects Detection由于不知道要分类和回归多少个box,所以上述想法就无效了。将Multiple Objects Detection看作为Classification的问题,给图片中的框进行分类。这就需要首先得到一些框(Region Proposal),然后对框进行分类和调整其边界。根据Region Proposal使用的方法的改进,产生了R-CNN,Fast R-CNN,Faster R-CNN系列
Multiple Objects Detection由于不知道要分类和回归多少个box,所以上述想法就无效了。将Multiple Objects Detection看作为Classification的问题,给图片中的框进行分类。这就需要首先得到一些框(Region Proposal),然后对框进行分类和调整其边界。根据Region Proposal使用的方法的改进,产生了R-CNN,Fast R-CNN,Faster R-CNN系列 Multiple Objects Detection的另外一种思想是,将图片分为一些栅格,每个栅格预测一定数量的框。其网络只有一步,被称为One Stage模型,我认为这种网络结构与Classification+Localization的网络结构很类似,所以感觉像是对每个栅格都做Classification+Localization,从而完成Multiple Object Detection任务。
Instance Segmentation
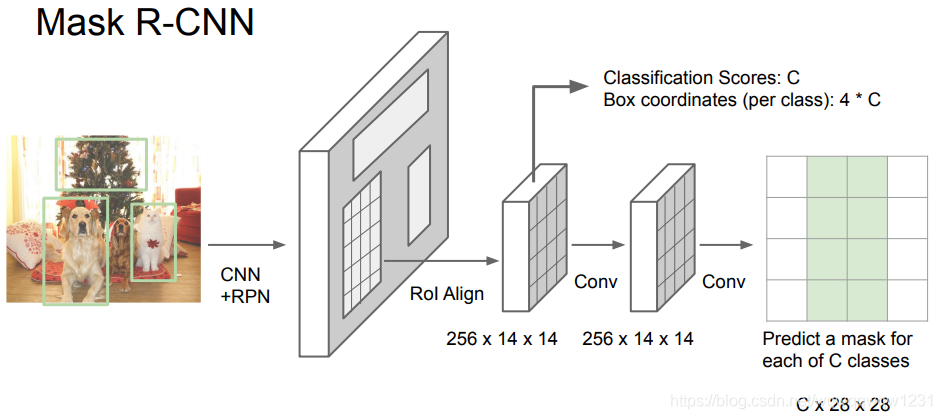
Mask R-CNN,在Faster RCNN的基础上进行改进,RoI Pooling之后加入了预测Mask的分支,类似于Segementation的网络结构。使得在做Object Detection的同时,得到了Object的Mask,从而完成Instance Segmentation。

Visualizing and Understanding
Guided Backpropagation
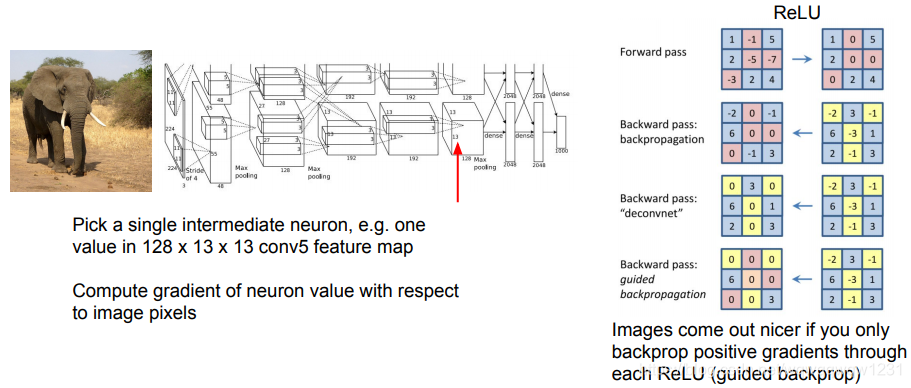 从想要观察的layer的梯度设为1,回传梯度,在通过ReLU时,只回传绝对正值,保证回传的神经元构成的前向计算对观察的layer所产生的影响均为正。结果如下:
从想要观察的layer的梯度设为1,回传梯度,在通过ReLU时,只回传绝对正值,保证回传的神经元构成的前向计算对观察的layer所产生的影响均为正。结果如下: 
Gradient Ascent
对于想要观察的某曾layer,将其梯度设为1,回传梯度,在最后一层计算关于图像的梯度,优化图像。意味这最终能得到能引起layer最强反应的图像。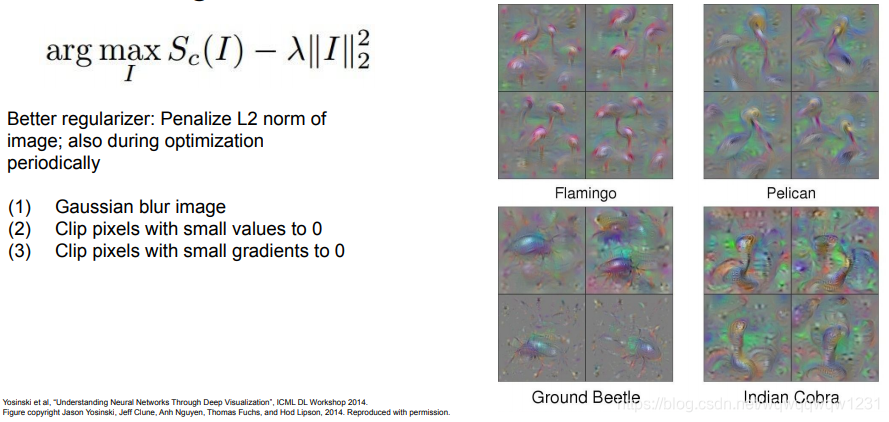 其应用有生成对抗图片,改变照片风格等等。
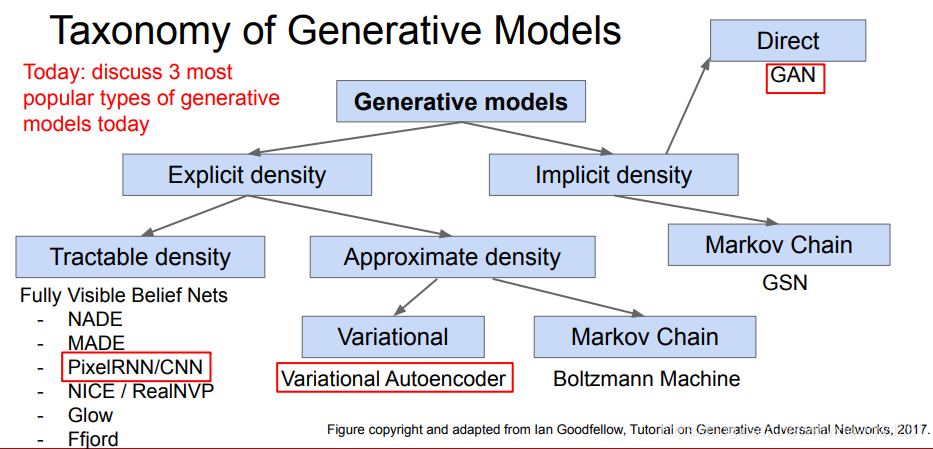
其应用有生成对抗图片,改变照片风格等等。 Generative Models
目标:Given training data, generate new samples from same distribution
这块我也不是很了解,只是写个大概结构吧。总体来说,就是把神经网络认为是一个函数拟合器,遇到不方便求解的函数时,使用神经网络进行拟合。
这需要显示或者隐式地获取图片x的分布,然后从分布中采样新的图片。
PixelRNN and PixelCNN
优化目标如下
 PixelCNN示意图如下
PixelCNN示意图如下 
Variational Autoencoders (VAE)
认为图片的分布x是由一些潜变量决定了。

背景知识:Autoencoder
 VAE:神经网络的输出不是feature,而是潜变量的统计特征,均值和方差。
VAE:神经网络的输出不是feature,而是潜变量的统计特征,均值和方差。 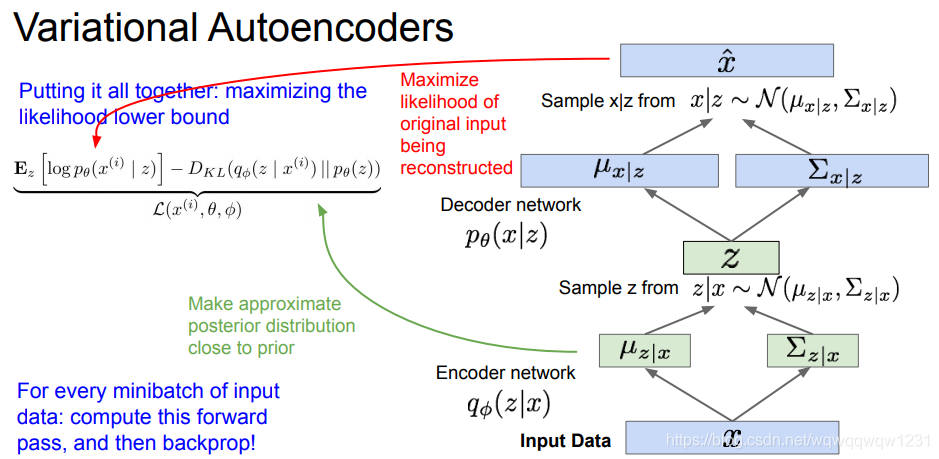 结果:潜变量具备一定的可解释性
结果:潜变量具备一定的可解释性 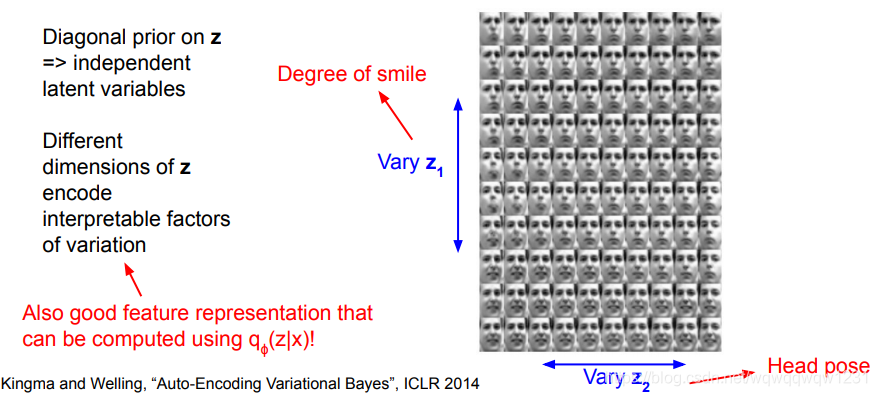
Generative Adversarial Networks (GAN)
隐式的获得图片的分布,使用生成网络和判别网络,进行博弈式地训练。
目标如下:
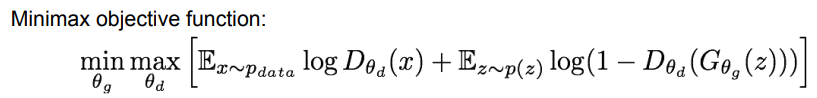 max是与判别器有关,第一项中x采样自真实图片,希望判别器对此类图片给分更高,第二项是通过生成器生成的图片,希望判别器对此类图片给分尽可能第。 min是与生成器有关,其参数只在第二项中出现,是希望判别器对生成的图片给的分数尽可能高,因为生成器是意图骗过判别器。
max是与判别器有关,第一项中x采样自真实图片,希望判别器对此类图片给分更高,第二项是通过生成器生成的图片,希望判别器对此类图片给分尽可能第。 min是与生成器有关,其参数只在第二项中出现,是希望判别器对生成的图片给的分数尽可能高,因为生成器是意图骗过判别器。 结果:结果具有很强的可解释性
下图是对两个随机的z的进行插值,然后生成的图片,可以看到风格是渐变的。 对于不同的风格还可以进行加减得到
对于不同的风格还可以进行加减得到 
收获
本课程从线性分类器讲起,从线性分类器观点给了神经网络的解释,如果使用ReLU作为激活函数,可以认为神经网络就是很多个线性分类器的组合
其中有几个lecture讲了很实用的训练技巧,非常值得学习 在Object Detection的问题中,我感觉到了神经网络模组化的概念,例如在Mask R-CNN中加入人体姿态识别的 在Generative Adversarial Networks,将神经网络看做一个函数拟合器,拟合难以求解的函数,这一点在其他很多问题中是非常值得一试的转载地址:https://blog.csdn.net/wqwqqwqw1231/article/details/97144342 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
