Flume复制和多路复用原理与实现
 下面的实现写的都是控制台测试,重新定义source源和sink源即可实现监听指定文件和写出到指定位置。
下面的实现写的都是控制台测试,重新定义source源和sink源即可实现监听指定文件和写出到指定位置。
发布日期:2021-09-27 12:34:38
浏览次数:2
分类:技术文章
本文共 3206 字,大约阅读时间需要 10 分钟。
原理
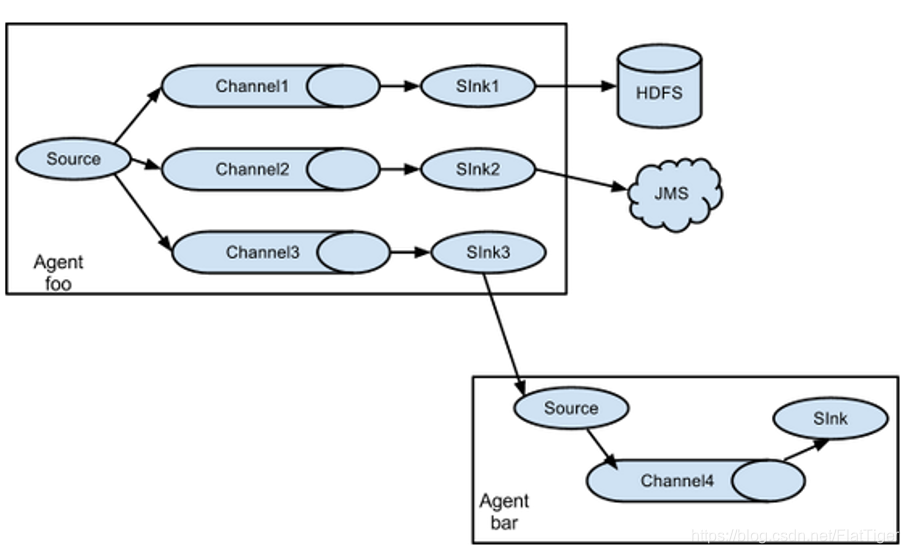
复制:利用Channel Selector将相同的数据发送到不同Channel中,不同Channel中的数据分发到不同的Sink,不同的Sink再将数据发送到指定位置。
多路复用:利用拦截器和Channel Selector将不同的数据发送到不同的Channel中,不同Channel中的数据分发到不同的Sink,不同的Sink再将数据发送到指定位置。案例
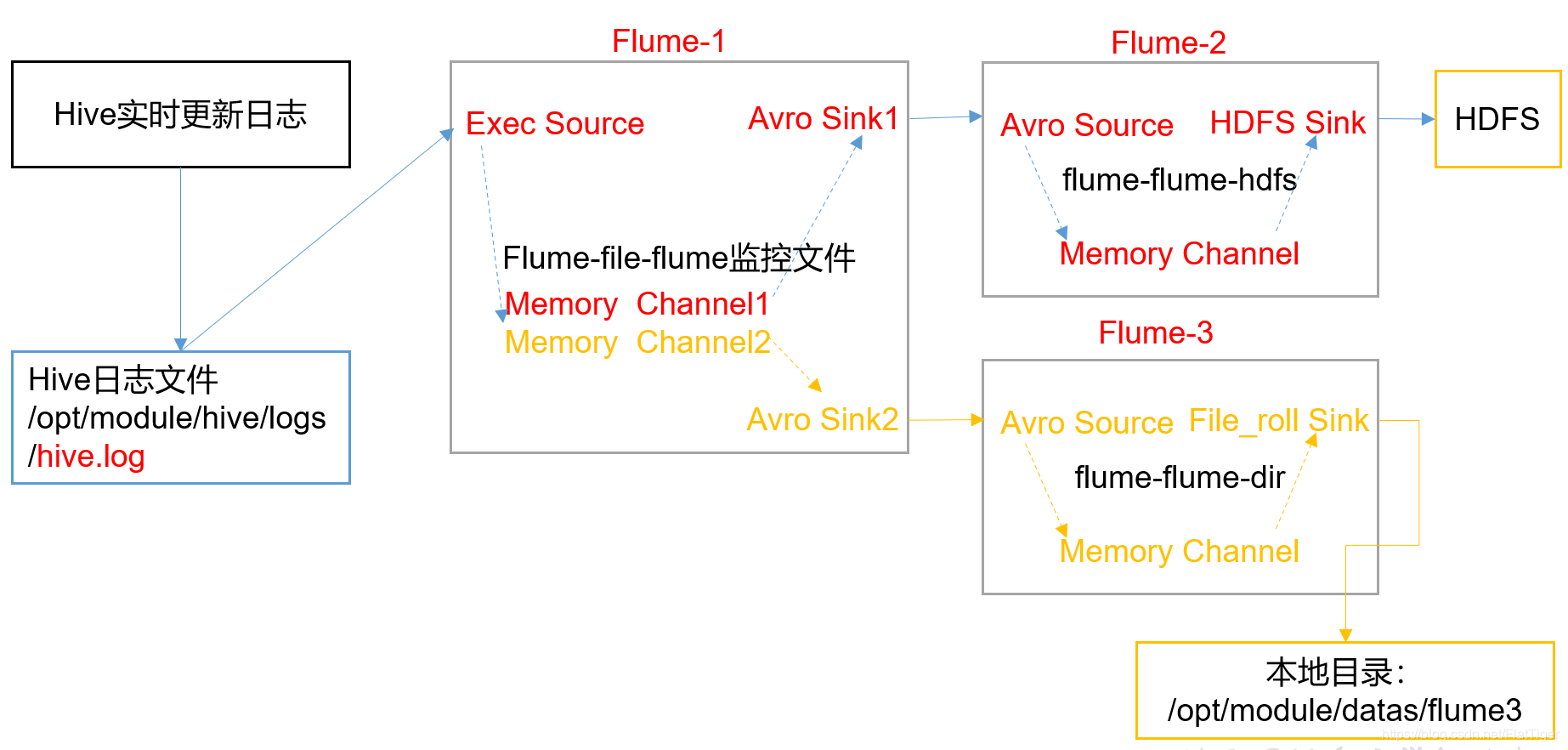
使用Flume-1监控文件变动,Flume-1将变动内容传递给Flume-2,Flume-2负责存储到HDFS。同时Flume-1将变动内容传递给Flume-3,Flume-3负责输出到Local FileSystem。
下面的实现写的都是控制台测试,重新定义source源和sink源即可实现监听指定文件和写出到指定位置。 复制实现
# agent1配置文件放在hadoop01# 定义sources、channels、sinksa1.sources = r1a1.channels = c1 c2a1.sinks = k1 k2# 配置source# a1.sources.r1.type = exec# a1.sources.r1.command = tail -F /opt/module/hive/logs# netcat端口测试a1.sources.r1.type = netcata1.sources.r1.bind = hadoop01a1.sources.r1.port = 11111# 配置Channel Selector,默认为replicating 复制a1.sources.r1.selector.type = replicating# 配置channela1.channels.c1.type = memorya1.channels.c2.type = memory# 配置sink k1 数据发送到hadoop02的22222端口a1.sinks.k1.type = avroa1.sinks.k1.hostname = hadoop02a1.sinks.k1.port = 22222# 配置sink k2 数据发送到hadoop03的33333端口a1.sinks.k2.type = avroa1.sinks.k2.hostname = hadoop03a1.sinks.k2.port = 33333# 配置source、sink、channel关系a1.sources.r1.channels = c1 c2a1.sinks.k1.channel = c1a1.sinks.k2.channel = c2
# agent2配置文件放在hadoop02# 定义sources、channels、sinksa1.sources = r1a1.channels = c1a1.sinks = k1# 配置source 从指定地址的端口接收数据a1.sources.r1.type = avroa1.sources.r1.bind = hadoop02a1.sources.r1.port = 22222# 配置channela1.channels.c1.type = memory# 配置sink a1.sinks.k1.type = logger# 测试logger打印到控制台,如果需要保存到指定位置,修改sink的类型即可# 配置source、sink、channel关系a1.sources.r1.channels = c1a1.sinks.k1.channel = c1
# agent3 配置文件放在hadoop03# 定义sources、channels、sinksa1.sources = r1a1.channels = c1a1.sinks = k1# 配置source 从指定地址的端口接收数据a1.sources.r1.type = avroa1.sources.r1.bind = hadoop03a1.sources.r1.port = 33333# 配置channela1.channels.c1.type = memory# 配置sink a1.sinks.k1.type = logger# 测试logger打印到控制台,如果需要保存到指定位置,修改sink的类型即可# 配置source、sink、channel关系a1.sources.r1.channels = c1a1.sinks.k1.channel = c1
启动不同节点的agent实例时,先启动接收端的agent,再启动发送端的agent。
多路复用实现
需要配置拦截器和Chennal Selector使用
# agent1# 定义sources、channels、sinksa1.sources = r1a1.channels = c1 c2a1.sinks = k1 k2# 配置source# a1.sources.r1.type = exec# a1.sources.r1.command = tail -F /opt/module/hive/logs# netcat端口测试a1.sources.r1.type = netcata1.sources.r1.bind = hadoop01a1.sources.r1.port = 11111# 配置Channel Selector multiplexing复用a1.sources.r1.selector.type = multiplexing# state是event headers中的keya1.sources.r1.selector.header = state# CZ是event headers中的key对应的value,如果是CZ就发往c1a1.sources.r1.selector.mapping.CZ = c1# US是event headers中的key对应的value,如果是US就发往c2a1.sources.r1.selector.mapping.US = c2# 配置拦截器a1.sources.r1.interceptors = i1# static拦截器可以给event headers添加自定义的key和valuea1.sources.r1.interceptors.i1.type = static# 指定能通过的key和value类型a1.sources.r1.interceptors.i1.key = state# 只有headers信息中,key=state,value=CZ的才会被发送a1.sources.r1.interceptors.i1.value = CZ# 配置channela1.channels.c1.type = memorya1.channels.c2.type = memory# 配置sink k1 数据发送到hadoop02的22222端口a1.sinks.k1.type = avroa1.sinks.k1.hostname = hadoop02a1.sinks.k1.port = 22222# 配置sink k2 数据发送到hadoop03的33333端口a1.sinks.k2.type = avroa1.sinks.k2.hostname = hadoop03a1.sinks.k2.port = 33333# 配置source、sink、channel关系a1.sources.r1.channels = c1 c2a1.sinks.k1.channel = c1a1.sinks.k2.channel = c2
agent2和agent3的实例同上面的配置文件。
转载地址:https://blog.csdn.net/FlatTiger/article/details/114009471 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
表示我来过!
[***.240.166.169]2024年04月09日 05时41分36秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
【Leetcode刷题篇】leetcode70 爬楼梯
2019-04-26
【Leetcode刷题篇】leetcode739 每日温度
2019-04-26
【Leetcode刷题篇】leetcode121买卖股票的最佳时机
2019-04-26
【面试篇】Java多线程并发-Java关键字volatile详解
2019-04-26
【面试篇】Java的代理模式-静态代理和动态代理详解
2019-04-26
【面试篇】 Java对象拷贝(对象克隆 对象复制)
2019-04-26
【Leetcode刷题篇】leetcode64 最小路径和
2019-04-26
【Leetcode刷题篇】leetcode79 单词搜索
2019-04-26
【Leetcode刷题篇】leetcode300 最长上升子序列
2021-06-29
【Leetcode刷题篇】leetcode394 字符串解码
2021-06-29
【Leetcode刷题篇】leetcode152 乘积最大数组
2021-06-29
【Leetcode刷题篇】leetcode56 合并区间
2019-04-26
【Leetcode刷题篇】leetcode210 课程表II
2019-04-26
【Leetcode刷题篇】leetcode207 课程表
2019-04-26
【Leetcode刷题篇】leetcode322 零钱兑换
2019-04-26
【Leetcode刷题篇】leetcode437 路径总和III
2019-04-26
【Leetcode刷题篇】leetcode416 分割等和子集
2019-04-26
【Leetcode刷题篇】leetcode31 下一个排列
2019-04-26
【Leetcode刷题篇】leetcode621 任务调度器
2019-04-26
【Leetcode刷题篇/面试篇】通俗易懂详解动态规划-背包问题详解
2019-04-26
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 306306726 位访客
访问时间: 2024-04-19 23:27:12
访问IP: 3.15.3.154
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版