Flume聚合的原理与实现
发布日期:2021-09-27 12:34:39
浏览次数:2
分类:技术文章
本文共 1351 字,大约阅读时间需要 4 分钟。
原理
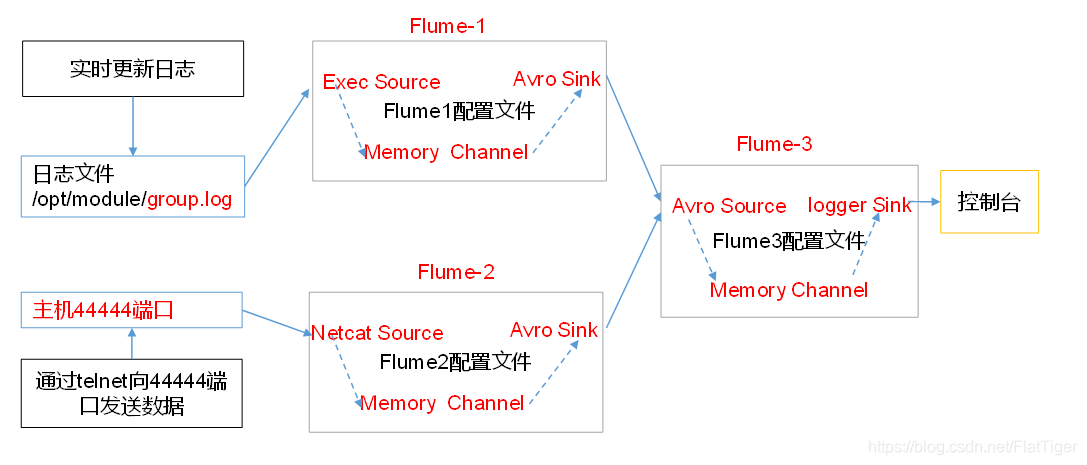
案例
hadoop01上的Flume-1监控文件/opt/module/group.log,
hadoop02上的Flume-2监控某一个端口的数据流, Flume-1与Flume-2将数据发送给hadoop03上的Flume-3,Flume-3将最终数据打印到控制台。 实现
# agent1# 定义sources、channels、sinksa1.sources = r1a1.channels = c1a1.sinks = k1# 配置sourcea1.sources.r1.type = TAILDIR# 日志索引记录a1.sources.r1.positionFile = /opt/module/flume/inode/taildir_position.json# 文件组a1.sources.r1.filegroups = f1a1.sources.r1.filegroups.f1 = /opt/module/group.log# 配置channela1.channels.c1.type = memory# 配置sinka1.sinks.k1.type = avroa1.sinks.k1.hostname = hadoop03a1.sinks.k1.port = 6666# 配置source、channel、sink关系a1.sources.r1.channels = c1a1.sinks.k1.channel = c1
# agent2# 定义sources、channels、sinksa1.sources = r1a1.channels = c1a1.sinks = k1# 配置sourcea1.sources.r1.type = netcata1.sources.r1.bind = hadoop02a1.sources.r1.port = 44444# channela1.channels.c1.type = memory# sinka1.sinks.k1.type = avroa1.sinks.k1.hostname = hadoop03a1.sinks.k1.port = 6666# 配置关系a1.sources.r1.channels = c1a1.sinks.k1.channel = c1
# agent3# 定义sources、channels、sinksa1.sources = r1a1.channels = c1a1.sinks = k1# 配置sourcea1.sources.r1.type = avroa1.sources.r1.bind = hadoop03a1.sources.r1.port = 6666# channela1.channels.c1.type = memory# sinka1.sinks.k1.type = logger# 配置关系a1.sources.r1.channels = c1a1.sinks.k1.channel = c1
先启动数据接收端,再启动数据发送端。
转载地址:https://blog.csdn.net/FlatTiger/article/details/114022601 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
留言是一种美德,欢迎回访!
[***.207.175.100]2024年04月21日 11时18分03秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
Linux必学的网络操作命令
2019-04-27
ASP.NET格式化日期
2019-04-27
按esc键退出的一个函数
2019-04-27
列表框操作函数集合
2019-04-27
在IE客户端调用windows系统资源
2019-04-27
document.all与WEB标准
2019-04-27
用IE重起计算机或者关机
2019-04-27
如何使得按确定和取消按纽转到两个不同的页面!
2019-04-27
DataGrid 的 全选/取消全选 控制(CheckBox)
2019-04-27
虚拟主机上用Asp.net实现Urlrewrite
2019-04-27
ASP.NET 应用中大文件上传研究
2019-04-27
如何最大限度提高.NET的性能
2019-04-27
短信收发类无错版JustinIO.cs
2019-04-27
短信编码类无错版PDUdecoding.cs
2019-04-27
CDMA模块上网设置的过程
2019-04-27
WISMO模块GPRS上网设置的过程
2019-04-27
简要AT命令介绍
2019-04-27
短信收发类无错版SerialStream.cs
2019-04-27
短信猫GSM Modem
2019-04-27
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 307835808 位访客
访问时间: 2024-04-25 15:22:51
访问IP: 18.188.152.162
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版