本文共 1342 字,大约阅读时间需要 4 分钟。
你是如何实现Flume数据传输的监控的?如何发现问题?
使用第三方框架Ganglia实时监控Flume。如果发现尝试提交的次数远远大于最后提交成功的次数,那说明flume性能不够。
可以配置flume-env.sh,提高自身的内存,一般来说设置为4-6G。如果还不理想,可以增加flume服务器,一般选择比较低的配置即可(16G运行内存,8T磁盘)。Flume的Source,Sink,Channel的作用?你们Source是什么类型?
作用
(1)Source组件是专门用来收集数据的,可以处理各种类型、各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy
(2)Channel组件对采集到的数据进行缓存,可以存放在Memory或File中。 (3)Sink组件是用于把数据发送到目的地的组件,目的地包括Hdfs、Logger、avro、thrift、ipc、file、Hbase、solr、自定义。我公司采用的Source类型为:
(1)监控后台日志:TailDir Source,支持断点续传、多目录。Flume1.6以前需要自己自定义Source记录每次读取文件位置,实现断点续传。
(2)监控后台产生日志的端口:netcatFlume的Channel Selectors
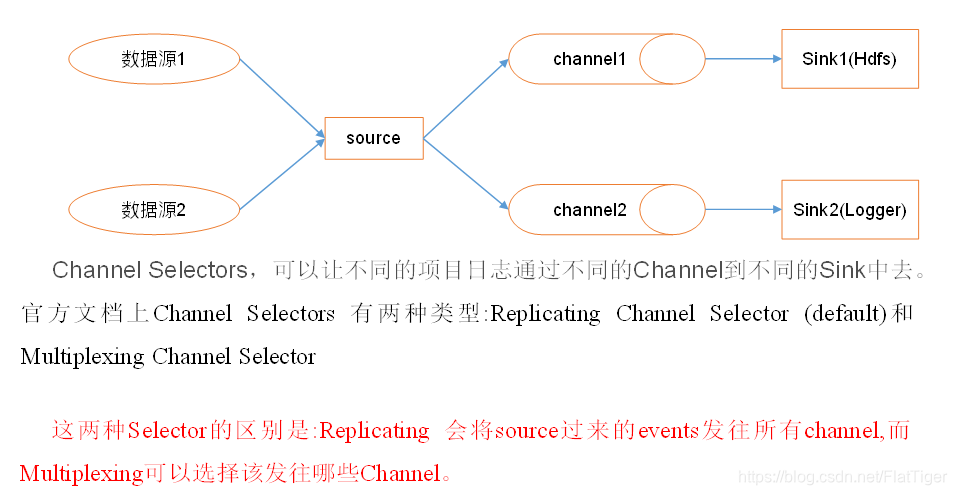
Flume的事务机制
Flume的事务机制(类似数据库的事务机制):Flume使用两个独立的事务分别负责从Soucrce到Channel,以及从Channel到Sink的事件传递。比如spooling directory source 为文件的每一行创建一个事件,一旦事务中所有的事件全部传递到Channel且提交成功,那么Soucrce就将该文件标记为完成。同理,事务以类似的方式处理从Channel到Sink的传递过程,如果因为某种原因使得事件无法记录,那么事务将会回滚。且所有的事件都会保持到Channel中,等待重新传递。
Flume采集数据会丢失吗?
根据Flume的架构原理,Flume是不可能丢失数据的,其内部有完善的事务机制,Source到Channel是事务性的,Channel到Sink是事务性的,因此这两个环节不会出现数据的丢失,唯一可能丢失数据的情况是Channel采用memoryChannel,agent宕机导致数据丢失,或者Channel存储数据已满,导致Source不再写入,未写入的数据丢失。
Flume不会丢失数据,但是有可能造成数据的重复,例如数据已经成功由Sink发出,但是没有接收到响应,Sink会再次发送数据,此时可能会导致数据的重复。Flume的优化手段
- File Channel:能多目录就多目录,要求存储在不同磁盘,提高吞吐量。
- 通过配置控制小文件。 a1.sinks.k2.hdfs.rollInterval = 3600 a1.sinks.k2.hdfs.rollSize = 134217728 a1.sinks.k2.hdfs.rollCount = 0
- 提高自身内存,或者增加flume服务器。
转载地址:https://blog.csdn.net/FlatTiger/article/details/114086501 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
