一、对于被频繁调用,更新频率较低的页面,可以采用HTML静态化技术
二、图片服务器分离
三、数据库集群和库表散列
mysql主从。m-m-s-s-s...(2个主,多个从。多个从使用负载均衡。主写入数据,从读取数据)
四、缓存。众多的缓存框架
五、负载均衡。nginx,lvs,F5
六、搜索用单独的服务器,搜索框架
七、使用MQ服务器
本文共 19053 字,大约阅读时间需要 63 分钟。
一、对于被频繁调用,更新频率较低的页面,可以采用HTML静态化技术
二、图片服务器分离
三、数据库集群和库表散列
mysql主从。m-m-s-s-s...(2个主,多个从。多个从使用负载均衡。主写入数据,从读取数据)
四、缓存。众多的缓存框架
五、负载均衡。nginx,lvs,F5
六、搜索用单独的服务器,搜索框架
七、使用MQ服务器
1.什么是集群
集群是一组协同工作的服务实体,用以提供比单一服务实体更具扩展性与可用性的服务平台。在客户端看来,一个集群就象是一个服务实体,但 事实上集群由一组服务实体组成。
2.集群的特性
与单一服务实体相比较,集群提供了以下两个关键特性:
1.可扩展性--集群的性能不限于单一的服务实体,新的服 务实体可以动态地加入到集群,从而增强集群的性能。
2. 高可用性--集群通过服务实体冗余使客户端免于轻易遇到out of service的警告。在集群中,同样的服务可以由多个服务实体提供。如果一个服务实体失败了,另一个服务实体会接管失败的服务实体。集群提供的从一个出 错的服务实体恢复到另一个服务实体的功能增强了应用的可用性。
为了具有可扩展性和高可用性特点,集群的必须具备以下两大能力:
(1) 负 载均衡--负载均衡能把任务比较均衡地分布到集群环境下的计算和网络资源。
(2) 错误恢复--由于某种原因,执行某个任务的资源出现故障,另一服 务实体中执行同一任务的资源接着完成任务。这种由于一个实体中的资源不能工作,另一个实体中的资源透明的继续完成任务的过程叫错误恢复。
负载均衡 和错误恢复都要求各服务实体中有执行同一任务的资源存在,而且对于同一任务的各个资源来说,执行任务所需的信息视图(信息上下文)必须是一样的。
3 集群的分类
集群主要分成三大类:高可用集群(High Availability Cluster/HA), 负载均衡集群(Load Balance Cluster),高性能计算集群(High Performance Computing Cluster/HPC)
(1) 高可用集群(High Availability Cluster/HA):一般是指当集群中有某个节点失效的情况下,其上的任务会自动转移到其他正常的节点上。还指可以将集群中的某节点进行离线维护再上线,该过程并不影响整个集群的运行。常见的就是2个节点做 成的HA集群,有很多通俗的不科学的名称,比如"双机热备", "双机互备", "双机",高可用集群解决的是保障用户的应用程序持续对外提供服 务的能力。
(2) 负载均衡集群(Load Balance Cluster):负载均衡集群运行时一般通过一个或者多个前端负载均衡器将工作负载分发到后端的一组服务器上,从而达到将工作负载分发。这样的计算机集群有时也被称为服务器群(Server Farm)。一般web服务器集群、数据库集群 和应用服务器集群都属于这种类型。这种集群可以在接到请求时,检查接受请求较少,不繁忙的服务器,并把请求转到这些服务器 上。从检查其他服务器状态这一点上 看,负载均衡和容错集群很接近,不同之处是数量上更多。
(3) 高性能计算集群(High Performance Computing Cluster/HPC):高性能计算集群采用将计算任务分配到集群的不同计算节点而提高计算能力,因而主要应用在科学计算领域。这类集群致力于提供单个计算机所不能提供的强大的计算能力
转自:http://www.oschina.net/news/17973/message-queue-shootout
我花了一周的时间评估比较了一下各种消息队列产品,非常的有趣。我做这个事的动机是因为一个客户有一个很高性能需求。他们的消息信息突破了1百万个并发。目前他们使用的是SQL server,并不理想,我建议他们使用消息队列服务器。
为了对一些相似的候选产品获得一个全面的但是粗浅的性能上的了解,我们它们放在一起做了个测试。我让每个消息产品各发送和接受1百万千条1K的消 息。测试准备的有些仓促,我并没有修改任何的配置,只是快速的看了一下它们的安装文档,安装好每种软件,然后就让它们做这些最简单的收发信息的操作。所以 这是一次真正的“开箱即装即用”的性能表现。我完全理解,这对那些初始配置十分保守的消息队列产品将会是个惩罚。
候选产品有:
把这四个MQ产品装上、跑起来是一个很有趣的工作。当你需要安装一个非Windows平台的产品时,下一定的功夫那是必须的。ActiveMQ需要 在目标机器上安装Java,RabbitMQ需要Erlang环境。安装这两个产品都没有遇到麻烦,但我想这是否给系统的维护增加了一层任务。如果这个中 的一个被选中,我需要让系统维护的人去理解和维护他们以前不熟悉的运行库。ActiveMQ,
RabbitMQ 和 MSMQ 都需要启动服务进程,这些都可以监控和配置,另外一个就有问题了。
ZeroMQ,它没有中间件架构,不需要任何服务进程和运行时。事实上,你的应用程序端点扮演了这个服务角色。这让部署起来非常简单,但担心的是, 你没有地方可以观察它是否有问题出现。就目前我知道的,ZeroMQ仅提供非持久性的队列。你可以在需要的地方实现自己的审计和数据恢复功能。老实说,我 甚至不确信是否该把它列在此次测试中,它的运行原理和其它几种差别太大了。
我就不瞎扯了,下面是测试结果。显示的是发送和接受的每秒钟的消息数。整个过程共产生1百万条1K的消息。测试的执行是在一个Windows Vista上进行的。

就像你看到的,ZeroMQ和其它的不是一个级别。它的性能惊人的高。公平的说,ZeroMQ跟其它几个比起来像头巨兽,尽管这样,结论很清楚:如果你希望一个应用程序发送消息越快越好,你选择ZeroMQ。当你不太在意偶然会丢失某些消息的情况下更有价值。
老实讲,我更希望使用Rabbit。但这种事情是应该做更多的测试,你最终会有一个最爱,我所听到的、读到的各种关于Rabbit的事情让我觉得它应该是最佳选择。但使用这个测试结果,我很难说服他们不去使用MSMQ。
如果你想自己跑一下这些测试,我的测试代码都放在了。我很感兴趣(但不是非常非常感兴趣)想知道如何优化这些测试,所以,如果你能做到一个更好的测试结果,请告诉我。谢谢。
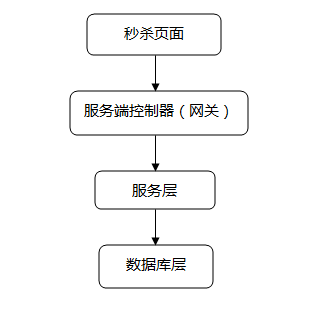
秒杀场景一般会在电商网站举行一些活动或者节假日在12306网站上抢票时遇到。对于电商网站中一些稀缺或者特价商品,电商网站一般会在约定时间点对其进行限量销售,因为这些商品的特殊性,会吸引大量用户前来抢购,并且会在约定的时间点同时在秒杀页面进行抢购。
限流: 鉴于只有少部分用户能够秒杀成功,所以要限制大部分流量,只允许少部分流量进入服务后端。
削峰:对于秒杀系统瞬时会有大量用户涌入,所以在抢购一开始会有很高的瞬间峰值。高峰值流量是压垮系统很重要的原因,所以如何把瞬间的高流量变成一段时间平稳的流量也是设计秒杀系统很重要的思路。实现削峰的常用的方法有利用缓存和消息中间件等技术。
异步处理:秒杀系统是一个高并发系统,采用异步处理模式可以极大地提高系统并发量,其实异步处理就是削峰的一种实现方式。
内存缓存:秒杀系统最大的瓶颈一般都是读写,由于数据库读写属于磁盘IO,性能很低,如果能够把部分数据或业务逻辑转移到内存缓存,效率会有极大地提升。
可拓展:当然如果我们想支持更多用户,更大的并发,最好就将系统设计成弹性可拓展的,如果流量来了,拓展机器就好了。像淘宝、京东等双十一活动时会增加大量机器应对交易高峰。
将请求拦截在系统上游,降低下游压力:秒杀系统特点是并发量极大,但实际秒杀成功的请求数量却很少,所以如果不在前端拦截很可能造成数据库读写锁冲突,甚至导致死锁,最终请求超时。
充分利用缓存:利用缓存可极大提高系统读写速度。
消息队列:消息队列可以削峰,将拦截大量并发请求,这也是一个异步处理过程,后台业务根据自己的处理能力,从消息队列中主动的拉取请求消息进行业务处理。
页面静态化:将活动页面上的所有可以静态的元素全部静态化,并尽量减少动态元素。通过CDN来抗峰值。
禁止重复提交:用户提交之后按钮置灰,禁止重复提交
用户限流:在某一时间段内只允许用户提交一次请求,比如可以采取IP限流
限制uid(UserID)访问频率:我们上面拦截了浏览器访问的请求,但针对某些恶意攻击或其它插件,在服务端控制层需要针对同一个访问uid,限制访问频率。
上面只拦截了一部分访问请求,当秒杀的用户量很大时,即使每个用户只有一个请求,到服务层的请求数量还是很大。比如我们有100W用户同时抢100台手机,服务层并发请求压力至少为100W。
采用消息队列缓存请求:既然服务层知道库存只有100台手机,那完全没有必要把100W个请求都传递到数据库啊,那么可以先把这些请求都写到消息队列缓存一下,数据库层订阅消息减库存,减库存成功的请求返回秒杀成功,失败的返回秒杀结束。
利用缓存应对读请求:对类似于12306等购票业务,是典型的读多写少业务,大部分请求是查询请求,所以可以利用缓存分担数据库压力。
数据库层是最脆弱的一层,一般在应用设计时在上游就需要把请求拦截掉,数据库层只承担“能力范围内”的访问请求。所以,上面通过在服务层引入队列和缓存,让最底层的数据库高枕无忧。
是一个分布式缓存系统,支持多种,我们可以利用Redis轻松实现一个强大的秒杀系统。
我们可以采用Redis 最简单的key-value数据结构,用一个原子类型的变量值(AtomicInteger)作为key,把用户id作为value,库存数量便是原子变量的最大值。对于每个用户的秒杀,我们使用 RPUSH key value插入秒杀请求, 当插入的秒杀请求数达到上限时,停止所有后续插入。
然后我们可以在台启动多个工作线程,使用 LPOP key 读取秒杀成功者的用户id,然后再操作数据库做最终的下订单减库存操作。
当然,上面Redis也可以替换成消息中间件如ActiveMQ、RabbitMQ等,也可以将缓存和消息中间件 组合起来,缓存系统负责接收记录用户请求,消息中间件负责将缓存中的请求同步到数据库。
随着互联网应用的广泛普及,海量数据的存储和访问成为了系统设计的瓶颈问题。对于一个大型的互联网应用,每天几十亿的PV无疑对数据库造成了相当高的负载。对于系统的稳定性和扩展性造成了极大的问题。通过数据切分来提高网站性能,横向扩展数据层已经成为架构研发人员首选的方式。
"Shard" 这个词英文的意思是"碎片",而作为数据库相关的技术用语,似乎最早见于大型多人在线角色扮演游戏中。"Sharding" 姑且称之为"分片"。Sharding 不是一个某个特定数据库软件附属的功能,而是在具体技术细节之上的抽象处理,是水平扩展(Scale Out,亦或横向扩展、向外扩展)的解决方案,其主要目的是为突破单节点数据库服务器的 I/O 能力限制,解决数据库扩展性问题。通过一系列的切分规则将数据水平分布到不同的DB或table中,在通过相应的DB路由或者table路由规则找到需要查询的具体的DB或者table,以进行Query操作。“sharding”通常是指“水平切分”,这也是本文讨论的重点。接下来举个简单的例子:我们针对一个Blog应用中的日志来说明,比如日志文章(article)表有如下字段:

面对这样的一个表,我们怎样切分呢?怎样将这样的数据分布到不同的数据库中的表中去呢?我们可以这样做,将user_id为1~10000的所有的文章信息放入DB1中的article表中,将user_id为10001~20000的所有文章信息放入DB2中的 article表中,以此类推,一直到DBn。这样一来,文章数据就很自然的被分到了各个数据库中,达到了数据切分的目的。
接下来要解决的问题就是怎样找到具体的数据库呢?其实问题也是简单明显的,既然分库的时候我们用到了区分字段user_id,那么很自然,数据库路由的过程当然还是少不了user_id的。就是我们知道了这个blog的user_id,就利用这个user_id,利用分库时候的规则,反过来定位具体的数据库。比如user_id是234,利用刚才的规则,就应该定位到DB1,假如user_id是12343,利用该才的规则,就应该定位到DB2。以此类推,利用分库的规则,反向的路由到具体的DB,这个过程我们称之为“DB路由”。
平常我们会自觉的按照范式来设计我们的数据库,考虑到数据切分的DB设计,将违背这个通常的规矩和约束。为了切分,我们不得不在数据库的表中出现冗余字段,用作区分字段或者叫做分库的标记字段。比如上面的article的例子中的user_id这样的字段(当然,刚才的例子并没有很好的体现出user_id的冗余性,因为user_id这个字段即使就是不分库,也是要出现的,算是我们捡了便宜吧)。当然冗余字段的出现并不只是在分库的场景下才出现的,在很多大型应用中,冗余也是必须的,这个涉及到高效DB的设计,本文不再赘述。
上面对什么是数据切分做了个概要的描述和解释,读者可能会疑问,为什么需要数据切分呢?像 Oracle这样成熟稳定的数据库,足以支撑海量数据的存储与查询了?为什么还需要数据切片呢?
的确,Oracle的DB确实很成熟很稳定,但是高昂的使用费用和高端的硬件支撑不是每一个公司能支付的起的。试想一下一年几千万的使用费用和动辄上千万元的小型机作为硬件支撑,这是一般公司能支付的起的吗?即使就是能支付的起,假如有更好的方案,有更廉价且水平扩展性能更好的方案,我们为什么不选择呢?
我们知道每台机器无论配置多么好它都有自身的物理上限,所以当我们应用已经能触及或远远超出单台机器的某个上限的时候,我们惟有寻找别的机器的帮助或者继续升级的我们的硬件,但常见的方案还是横向扩展,通过添加更多的机器来共同承担压力。我们还得考虑当我们的业务逻辑不断增长,我们的机器能不能通过线性增长就能满足需求?Sharding可以轻松的将计算,存储,I/O并行分发到多台机器上,这样可以充分利用多台机器各种处理能力,同时可以避免单点失败,提供系统的可用性,进行很好的错误隔离。
综合以上因素,数据切分是很有必要的。 我们用免费的MySQL和廉价的Server甚至是PC做集群,达到小型机+大型商业DB的效果,减少大量的资金投入,降低运营成本,何乐而不为呢?所以,我们选择Sharding,拥抱Sharding。
数据切分可以是物理上的,对数据通过一系列的切分规则将数据分布到不同的DB服务器上,通过路由规则路由访问特定的数据库,这样一来每次访问面对的就不是单台服务器了,而是N台服务器,这样就可以降低单台机器的负载压力。
数据切分也可以是数据库内的,对数据通过一系列的切分规则,将数据分布到一个数据库的不同表中,比如将article分为article_001,article_002等子表,若干个子表水平拼合有组成了逻辑上一个完整的article表,这样做的目的其实也是很简单的。举个例子说明,比如article表中现在有5000w条数据,此时我们需要在这个表中增加(insert)一条新的数据,insert完毕后,数据库会针对这张表重新建立索引,5000w行数据建立索引的系统开销还是不容忽视的。但是反过来,假如我们将这个表分成100 个table呢,从article_001一直到article_100,5000w行数据平均下来,每个子表里边就只有50万行数据,这时候我们向一张 只有50w行数据的table中insert数据后建立索引的时间就会呈数量级的下降,极大了提高了DB的运行时效率,提高了DB的并发量。当然分表的好处还不知这些,还有诸如写操作的锁操作等,都会带来很多显然的好处。
综上,分库降低了单点机器的负载;分表,提高了数据操作的效率,尤其是Write操作的效率。行文至此我们依然没有涉及到如何切分的问题。接下来,我们将对切分规则进行详尽的阐述和说明。
上文中提到,要想做到数据的水平切分,在每一个表中都要有相冗余字符作为切分依据和标记字段,通常的应用中我们选用user_id作为区分字段,基于此就有如下三种分库的方式和规则:(当然还可以有其他的方式)
(1) 号段分区
user_id为1~1000的对应DB1,1001~2000的对应DB2,以此类推;
优点:可部分迁移
缺点:数据分布不均
(2)hash取模分区
对user_id进行hash(或者如果user_id是数值型的话直接使用user_id 的值也可),然后用一个特定的数字,比如应用中需要将一个数据库切分成4个数据库的话,我们就用4这个数字对user_id的hash值进行取模运算,也就是user_id%4,这样的话每次运算就有四种可能:结果为1的时候对应DB1;结果为2的时候对应DB2;结果为3的时候对应DB3;结果为0的时候对应DB4。这样一来就非常均匀的将数据分配到4个DB中。
优点:数据分布均匀
缺点:数据迁移的时候麻烦,不能按照机器性能分摊数据
(3)在认证库中保存数据库配置
就是建立一个DB,这个DB单独保存user_id到DB的映射关系,每次访问数据库的时候都要先查询一次这个数据库,以得到具体的DB信息,然后才能进行我们需要的查询操作。
优点:灵活性强,一对一关系
缺点:每次查询之前都要多一次查询,性能大打折扣
以上就是通常的开发中我们选择的三种方式,有些复杂的项目中可能会混合使用这三种方式。 通过上面的描述,我们对分库的规则也有了简单的认识和了解。当然还会有更好更完善的分库方式,还需要我们不断的探索和发现。
分布式数据方案提供功能如下:
(1)提供分库规则和路由规则(RouteRule简称RR);
(2)引入集群(Group)的概念,保证数据的高可用性;
(3)引入负载均衡策略(LoadBalancePolicy简称LB);
(4)引入集群节点可用性探测机制,对单点机器的可用性进行定时的侦测,以保证LB策略的正确实施,以确保系统的高度稳定性;
(5)引入读/写分离,提高数据的查询速度;
仅仅是分库分表的数据层设计也是不够完善的,当我们采用了数据库切分方案,也就是说有N台机器组成了一个完整的DB 。如果有一台机器宕机的话,也仅仅是一个DB的N分之一的数据不能访问而已,这是我们能接受的,起码比切分之前的情况好很多了,总不至于整个DB都不能访问。
一般的应用中,这样的机器故障导致的数据无法访问是可以接受的,假设我们的系统是一个高并发的电子商务网站呢?单节点机器宕机带来的经济损失是非常严重的。也就是说,现在我们这样的方案还是存在问题的,容错性能是经不起考验的。当然了,问题总是有解决方案的。我们引入集群的概念,在此我称之为Group,也就是每一个分库的节点我们引入多台机器,每台机器保存的数据是一样的,一般情况下这多台机器分摊负载,当出现宕机情况,负载均衡器将分配负载给这台宕机的机器。这样一来,就解决了容错性的问题。

如上图所示,整个数据层有Group1,Group2,Group3三个集群组成,这三个集群就是数据水平切分的结果,当然这三个集群也就组成了一个包含完整数据的DB。每一个Group包括1个Master(当然Master也可以是多个)和 N个Slave,这些Master和Slave的数据是一致的。 比如Group1中的一个slave发生了宕机现象,那么还有两个slave是可以用的,这样的模型总是不会造成某部分数据不能访问的问题,除非整个 Group里的机器全部宕掉,但是考虑到这样的事情发生的概率非常小(除非是断电了,否则不易发生吧)。
在没有引入集群以前,我们的一次查询的过程大致如下:请求数据层,并传递必要的分库区分字段 (通常情况下是user_id)。数据层根据区分字段Route到具体的DB,在这个确定的DB内进行数据操作。
这是没有引入集群的情况,当时引入集群会 是什么样子的呢?我们的路由器上规则和策略其实只能路由到具体的Group,也就是只能路由到一个虚拟的Group,这个Group并不是某个特定的物理服务器。接下来需要做的工作就是找到具体的物理的DB服务器,以进行具体的数据操作。
基于这个环节的需求,我们引入了负载均衡器的概念 (LB),负载均衡器的职责就是定位到一台具体的DB服务器。具体的规则如下:负载均衡器会分析当前sql的读写特性,如果是写操作或者是要求实时性很强的操作的话,直接将查询负载分到Master,如果是读操作则通过负载均衡策略分配一个Slave。
我们的负载均衡器的主要研究方向也就是负载分发策略,通常情况下负载均衡包括随机负载均衡和加权负载均衡。随机负载均衡很好理解,就是从N个Slave中随机选取一个Slave。这样的随机负载均衡是不考虑机器性能的,它默认为每台机器的性能是一样的。假如真实的情况是这样的,这样做也是无可厚非的。假如实际情况并非如此呢?每个Slave的机器物理性能和配置不一样的情况,再使用随机的不考虑性能的负载均衡,是非常不科学的,这样一来会给机器性能差的机器带来不必要的高负载,甚至带来宕机的危险,同时高性能的数据库服务器也不能充分发挥其物理性能。基于此考虑从,我们引入了加权负载均衡,也就是在我们的系统内部通过一定的接口,可以给每台DB服务器分配一个权值,然后再运行时LB根据权值在集群中的比重,分配一定比例的负载给该DB服务器。当然这样的概念的引入,无疑增大了系统的复杂性和可维护性。有得必有失,我们也没有办法逃过的。
有了分库,有了集群,有了负载均衡器,是不是就万事大吉了呢? 事情远没有我们想象的那么简单。虽然有了这些东西,基本上能保证我们的数据层可以承受很大的压力,但是这样的设计并不能完全规避数据库宕机的危害。假如Group1中的slave2 宕机了,那么系统的LB并不能得知,这样的话其实是很危险的,因为LB不知道,它还会以为slave2为可用状态,所以还是会给slave2分配负载。这样一来,问题就出来了,客户端很自然的就会发生数据操作失败的错误或者异常。
这样是非常不友好的!怎样解决这样的问题呢? 我们引入集群节点的可用性探测机制 ,或者是可用性的数据推送机制。这两种机制有什么不同呢?首先说探测机制吧,顾名思义,探测即使,就是我的数据层客户端,不定时对集群中各个数据库进行可用性的尝试,实现原理就是尝试性链接,或者数据库端口的尝试性访问,都可以做到。
那数据推送机制又是什么呢?其实这个就要放在现实的应用场景中来讨论这个问题了,一般情况下应用的DB 数据库宕机的话我相信DBA肯定是知道的,这个时候DBA手动的将数据库的当前状态通过程序的方式推送到客户端,也就是分布式数据层的应用端,这个时候在更新一个本地的DB状态的列表。并告知LB,这个数据库节点不能使用,请不要给它分配负载。一个是主动的监听机制,一个是被动的被告知的机制。两者各有所长。但是都可以达到同样的效果。这样一来刚才假设的问题就不会发生了,即使就是发生了,那么发生的概率也会降到最低。
上面的文字中提到的Master和Slave ,我们并没有做太多深入的讲解。一个Group由1个Master和N个Slave组成。为什么这么做呢?其中Master负责写操作的负载,也就是说一切写的操作都在Master上进行,而读的操作则分摊到Slave上进行。这样一来的可以大大提高读取的效率。在一般的互联网应用中,经过一些数据调查得出结论,读/写的比例大概在 10:1左右 ,也就是说大量的数据操作是集中在读的操作,这也就是为什么我们会有多个Slave的原因。
但是为什么要分离读和写呢?熟悉DB的研发人员都知道,写操作涉及到锁的问题,不管是行锁还是表锁还是块锁,都是比较降低系统执行效率的事情。我们这样的分离是把写操作集中在一个节点上,而读操作其其他 的N个节点上进行,从另一个方面有效的提高了读的效率,保证了系统的高可用性。
转自:http://www.cnblogs.com/zhongxinWang/p/4262650.html
HAProxy提供高可用性、负载均衡以及基于TCP和HTTP应用的代理,支持虚拟主机,它是免费、快速并且可靠的一种解决方案。
HAProxy特别适用于那些负载特大的web站点,这些站点通常又需要会话保持或七层处理。
HAProxy运行在当前的硬件上,完全可以支持数以万计的并发连接。并且它的运行模式使得它可以很简单安全的整合进您当前的架构中, 同时可以保护你的web服务器不被暴露到网络上。
HAProxy实现了一种事件驱动, 单一进程模型,此模型支持非常大的并发连接数。多进程或多线程模型受内存限制 、系统调度器限制以及无处不在的锁限制,很少能处理数千并发连接。事件驱动模型因为在有更好的资源和时间管理的用户空间(User-Space) 实现所有这
些任务,所以没有这些问题。此模型的弊端是,在多核系统上,这些程序通常扩展性较差。这就是为什么他们必须进行优化以 使每个CPU时间片(Cycle)做更多的工作。
#下载wget http://fossies.org/linux/misc/haproxy-1.6.9.tar.gz#解压tar -zxvf haproxy-1.6.9.tar.gzcd haproxy-1.6.9#安装make TARGET=linux2628 ARCH=x86_64 PREFIX=/usr/local/haproxymake install PREFIX=/usr/local/haproxy#参数说明TARGET=linux26 #内核版本,使用uname -r查看内核,如:2.6.18-371.el5,此时该参数就为linux26;kernel 大于2.6.28的用:TARGET=linux2628ARCH=x86_64 #系统位数PREFIX=/usr/local/haprpxy #/usr/local/haprpxy为haprpxy安装路径
###########全局配置#########global log 127.0.0.1 local0 #[日志输出配置,所有日志都记录在本机,通过local0输出] log 127.0.0.1 local1 notice #定义haproxy 日志级别[error warringinfo debug] daemon #以后台形式运行harpoxy nbproc 1 #设置进程数量 maxconn 4096 #默认最大连接数,需考虑ulimit-n限制 #user haproxy #运行haproxy的用户 #group haproxy #运行haproxy的用户所在的组 #pidfile /var/run/haproxy.pid #haproxy 进程PID文件 #ulimit-n 819200 #ulimit 的数量限制 #chroot /usr/share/haproxy #chroot运行路径 #debug #haproxy 调试级别,建议只在开启单进程的时候调试 #quiet########默认配置############defaults log global mode http #默认的模式mode { tcp|http|health },tcp是4层,http是7层,health只会返回OK option httplog #日志类别,采用httplog option dontlognull #不记录健康检查日志信息 retries 2 #两次连接失败就认为是服务器不可用,也可以通过后面设置 #option forwardfor #如果后端服务器需要获得客户端真实ip需要配置的参数,可以从Http Header中获得客户端ip option httpclose #每次请求完毕后主动关闭http通道,haproxy不支持keep-alive,只能模拟这种模式的实现 #option redispatch #当serverId对应的服务器挂掉后,强制定向到其他健康的服务器,以后将不支持 option abortonclose #当服务器负载很高的时候,自动结束掉当前队列处理比较久的链接 maxconn 4096 #默认的最大连接数 timeout connect 5000ms #连接超时 timeout client 30000ms #客户端超时 timeout server 30000ms #服务器超时 #timeout check 2000 #心跳检测超时 #timeout http-keep-alive10s #默认持久连接超时时间 #timeout http-request 10s #默认http请求超时时间 #timeout queue 1m #默认队列超时时间 balance roundrobin #设置默认负载均衡方式,轮询方式 #balance source #设置默认负载均衡方式,类似于nginx的ip_hash #balnace leastconn #设置默认负载均衡方式,最小连接数########统计页面配置########listen stats bind 0.0.0.0:1080 #设置Frontend和Backend的组合体,监控组的名称,按需要自定义名称 mode http #http的7层模式 option httplog #采用http日志格式 #log 127.0.0.1 local0 err #错误日志记录 maxconn 10 #默认的最大连接数 stats refresh 30s #统计页面自动刷新时间 stats uri /stats #统计页面url stats realm XingCloud\ Haproxy #统计页面密码框上提示文本 stats auth admin:admin #设置监控页面的用户和密码:admin,可以设置多个用户名 stats auth Frank:Frank #设置监控页面的用户和密码:Frank stats hide-version #隐藏统计页面上HAProxy的版本信息 stats admin if TRUE #设置手工启动/禁用,后端服务器(haproxy-1.4.9以后版本)########设置haproxy 错误页面######errorfile 403 /home/haproxy/haproxy/errorfiles/403.http#errorfile 500 /home/haproxy/haproxy/errorfiles/500.http#errorfile 502 /home/haproxy/haproxy/errorfiles/502.http#errorfile 503 /home/haproxy/haproxy/errorfiles/503.http#errorfile 504 /home/haproxy/haproxy/errorfiles/504.http########frontend前端配置##############frontend main bind *:80 #这里建议使用bind *:80的方式,要不然做集群高可用的时候有问题,vip切换到其他机器就不能访问了。 acl web hdr(host) -i www.abc.com #acl后面是规则名称,-i为忽略大小写,后面跟的是要访问的域名,如果访问www.abc.com这个域名,就触发web规则,。 acl img hdr(host) -i img.abc.com #如果访问img.abc.com这个域名,就触发img规则。 use_backend webserver if web #如果上面定义的web规则被触发,即访问www.abc.com,就将请求分发到webserver这个作用域。 use_backend imgserver if img #如果上面定义的img规则被触发,即访问img.abc.com,就将请求分发到imgserver这个作用域。 default_backend dynamic #不满足则响应backend的默认页面########backend后端配置##############backend webserver #webserver作用域 mode http balance roundrobin #balance roundrobin 负载轮询,balance source 保存session值,支持static-rr,leastconn,first,uri等参数 option httpchk /index.html HTTP/1.0 #健康检查, 检测文件,如果分发到后台index.html访问不到就不再分发给它 server web1 10.16.0.9:8085 cookie 1 weight 5 check inter 2000 rise 2 fall 3 server web2 10.16.0.10:8085 cookie 2 weight 3 check inter 2000 rise 2 fall 3 #cookie 1表示serverid为1,check inter 1500 是检测心跳频率 #rise 2是2次正确认为服务器可用,fall 3是3次失败认为服务器不可用,weight代表权重backend imgserver mode http option httpchk /index.php balance roundrobin server img01 192.168.137.101:80 check inter 2000 fall 3 server img02 192.168.137.102:80 check inter 2000 fall 3backend dynamic balance roundrobin server test1 192.168.1.23:80 check maxconn 2000 server test2 192.168.1.24:80 check maxconn 2000listen tcptest bind 0.0.0.0:5222 mode tcp option tcplog #采用tcp日志格式 balance source #log 127.0.0.1 local0 debug server s1 192.168.100.204:7222 weight 1 server s2 192.168.100.208:7222 weight 1 一、roundrobin,表示简单的轮询,每个服务器根据权重轮流使用,在服务器的处理时间平均分配的情况下这是最流畅和公平的算法。该算法是动态的,对于实例启动慢的服务器权重会在运行中调整。二、static-rr,表示根据权重,建议关注;每个服务器根据权重轮流使用,类似roundrobin,但它是静态的,意味着运行时修改权限是无效的。另外,它对服务器的数量没有限制。三、leastconn,表示最少连接者先处理,建议关注;leastconn建议用于长会话服务,例如LDAP、SQL、TSE等,而不适合短会话协议。如HTTP.该算法是动态的,对于实例启动慢的服务器权重会在运行中调整。四、source,表示根据请求源IP,建议关注;对请求源IP地址进行哈希,用可用服务器的权重总数除以哈希值,根据结果进行分配。 只要服务器正常,同一个客户端IP地址总是访问同一个服务器。如果哈希的结果随可用服务器数量而变化,那么客户端会定向到不同的服务器; 该算法一般用于不能插入cookie的Tcp模式。它还可以用于广域网上为拒绝使用会话cookie的客户端提供最有效的粘连; 该算法默认是静态的,所以运行时修改服务器的权重是无效的,但是算法会根据“hash-type”的变化做调整。五、uri,表示根据请求的URI;表示根据请求的URI左端(问号之前)进行哈希,用可用服务器的权重总数除以哈希值,根据结果进行分配。 只要服务器正常,同一个URI地址总是访问同一个服务器。 一般用于代理缓存和反病毒代理,以最大限度的提高缓存的命中率。该算法只能用于HTTP后端; 该算法一般用于后端是缓存服务器; 该算法默认是静态的,所以运行时修改服务器的权重是无效的,但是算法会根据“hash-type”的变化做调整。六、url_param,表示根据请求的URl参数'balance url_param' requires an URL parameter name 在HTTP GET请求的查询串中查找中指定的URL参数,基本上可以锁定使用特制的URL到特定的负载均衡器节点的要求; 该算法一般用于将同一个用户的信息发送到同一个后端服务器; 该算法默认是静态的,所以运行时修改服务器的权重是无效的,但是算法会根据“hash-type”的变化做调整。七、hdr(name),表示根据HTTP请求头来锁定每一次HTTP请求; 在每个HTTP请求中查找HTTP头,HTTP头 将被看作在每个HTTP请求,并针对特定的节点; 如果缺少头或者头没有任何值,则用roundrobin代替; 该算法默认是静态的,所以运行时修改服务器的权重是无效的,但是算法会根据“hash-type”的变化做调整。八、rdp-cookie(name),表示根据据cookie(name)来锁定并哈希每一次TCP请求。 为每个进来的TCP请求查询并哈希RDP cookie ; 该机制用于退化的持久模式,可以使同一个用户或者同一个会话ID总是发送给同一台服务器。 如果没有cookie,则使用roundrobin算法代替; 该算法默认是静态的,所以运行时修改服务器的权重是无效的,但是算法会根据“hash-type”的变化做调整。#其实这些算法各有各的用法,我们平时应用得比较多的应该是roundrobin、source和lestconn。haproxy负载均衡算法
########ACL策略定义#########################1、#如果请求的域名满足正则表达式返回true -i是忽略大小写acl denali_policy hdr_reg(host) -i ^(www.inbank.com|image.inbank.com)$2、#如果请求域名满足www.inbank.com 返回 true -i是忽略大小写acl tm_policy hdr_dom(host) -i www.inbank.com3、#在请求url中包含sip_apiname=,则此控制策略返回true,否则为falseacl invalid_req url_sub -i sip_apiname=#定义一个名为invalid_req的策略4、#在请求url中存在timetask作为部分地址路径,则此控制策略返回true,否则返回falseacl timetask_req url_dir -i timetask5、#当请求的header中Content-length等于0时返回 trueacl missing_cl hdr_cnt(Content-length) eq 0#########acl策略匹配相应###################1、#当请求中header中Content-length等于0 阻止请求返回403block if missing_cl2、#block表示阻止请求,返回403错误,当前表示如果不满足策略invalid_req,或者满足策略timetask_req,则阻止请求。block if !invalid_req || timetask_req3、#当满足denali_policy的策略时使用denali_server的backenduse_backend denali_server if denali_policy4、#当满足tm_policy的策略时使用tm_server的backenduse_backend tm_server if tm_policy5、#reqisetbe关键字定义,根据定义的关键字选择backendreqisetbe ^Host:\ img dynamicreqisetbe ^[^\ ]*\ /(img|css)/ dynamicreqisetbe ^[^\ ]*\ /admin/stats stats6、#以上都不满足的时候使用默认mms_server的backenddefault_backend mmshaproxy acl定义
1.创建记录日志文件 mkdir /var/log/haproxy chmod a+w /var/log/haproxy 2.编辑/etc/rsyslog.conf a) 开启514 UDP监听 # Provides UDP syslog reception $ModLoad imudp $UDPServerRun 514 b) 指定日志存放地点: local0.* /var/log/haproxy/haproxy.log 3.haproxy.conf 配置: global # 配置local2事件 log 127.0.0.1 local0 info 4.重启 rsyslog服务 systemctl restart rsyslog
/usr/local/haproxy/sbin/haproxy -f /usr/local/haproxy/haproxy.cfg
http://192.168.1.22:1080/stats#说明:#1080即haproxy配置文件中监听端口s#tats 即haproxy配置文件中的监听名称 监控页面详细说明

转载地址:https://blog.csdn.net/happydecai/article/details/80366986 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!