本文共 10049 字,大约阅读时间需要 33 分钟。
1. 配置Maven环境
首先检查Windows是否配置了maven,进入cmd命令行,输入mvn -version命令,如果出现下图所示的 情形则表示满意配置maven。
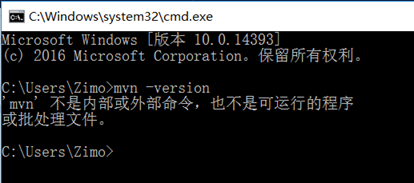
从浏览器进入maven官网,下载maven压缩包:。下载完后将其解压的一个自定义目录,然后配置环境变量。
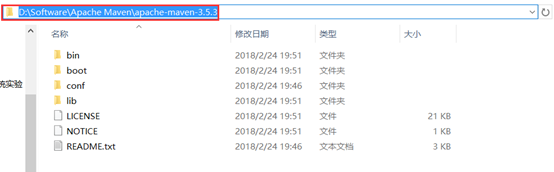
进入环境变量配置页面,新建一个MAVEN_HOME变量,变量值为刚才解压的路径(进入能看到bin文件夹的路径)。
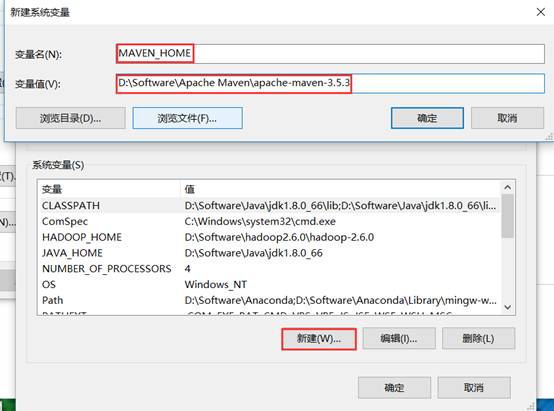
然后,在Path变量下添加MAVEN_HOME变量。
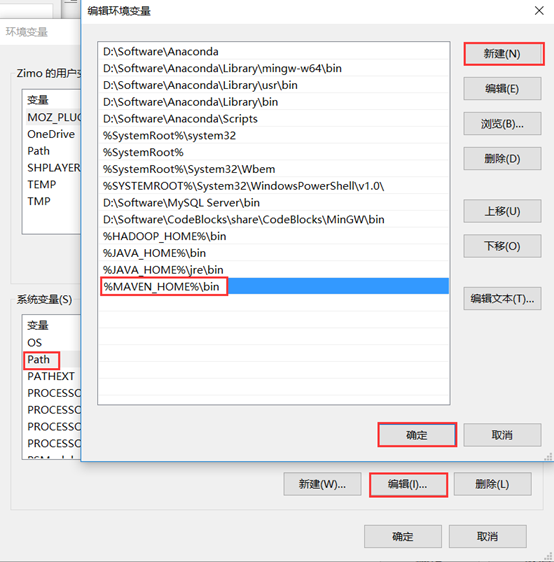
注意:老版本Windows直接在变量后面加上分号,然后加上%MAVEN_HOME%\bin。
回到命令行,再输入mvn -version,如果出现下图所示的情形则表明配置成功。

2. 在Eclipse中配置Maven
进入Eclipse,然后Window->Preferences->Maven,首先关联Maven安装路径待eclipse.
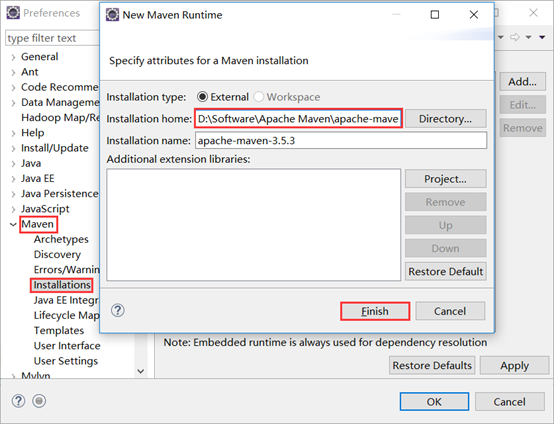
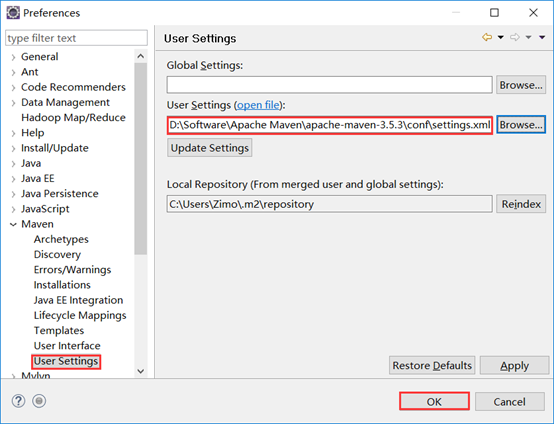
然后配置settings.xml文件,下面的本地库保存路径可以自定义(一般默认就好)。
3. 使用Maven管理多个MapReduce项目
首先新建一个maven项目。
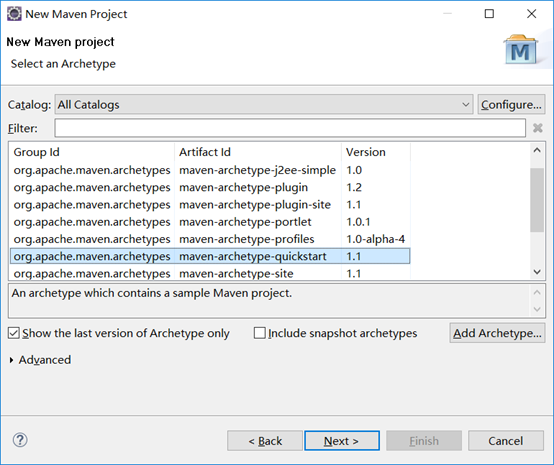
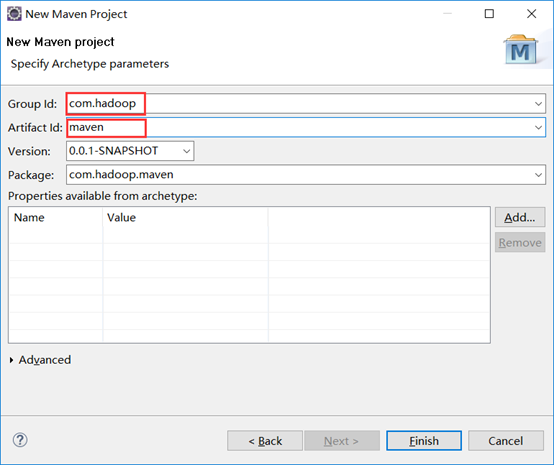
*(该图和我最后的名称不同,因为修改过,不过不影响,按照你自己的来即可)
然后新建一个WordCount.java类,代码可以从官网下载:
此时,WordCount.java类肯定是一片红,有很多报错,这是因为我们目前还没有引入所需要的jar文件。接下来是通过Maven框架引入所依赖的jar文件,这和之前我们直接导入然后Build Path的方法不同。我们现在使用Maven框架来进行管理,我们只需要在pom.xml文件中写入以下内容就可以实现jar文件的自动下载和管理。配置完后保存文件,然后Maven会自动下载好所需要的jar文件,报错也都会给解决掉。
pom.xml4.0.0 //下面两行改为自己新建项目时的Idcom.hadoop maven 1.0-SNAPSHOT jar maven http://maven.apache.org UTF-8 2.6.0 junit junit 3.8.1 test jdk.tools jdk.tools 1.8 //改成自己对于的JDK版本号system ${JAVA_HOME}/lib/tools.jar org.apache.hadoop hadoop-common ${hadoop.version} org.apache.hadoop hadoop-hdfs ${hadoop.version} org.apache.hadoop hadoop-client ${hadoop.version} org.apache.maven.plugins maven-shade-plugin 2.4.1 package shade com.hadoop.mavenPro.MyDriver //根据自己的项目路径修改false //该句很关键,必须配置为false
接下来是调试Maven项目中的MapReduce程序。
在右键WordCount类选择:Run as->Run Configuration。
搜索主类:
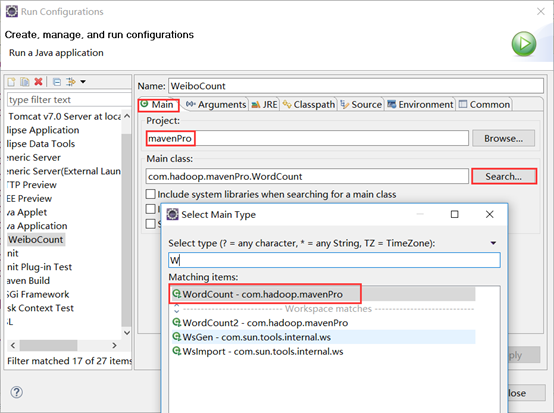
注意:如果搜不到对应类,请将Search上面的Project选择为自己所新建的项目。
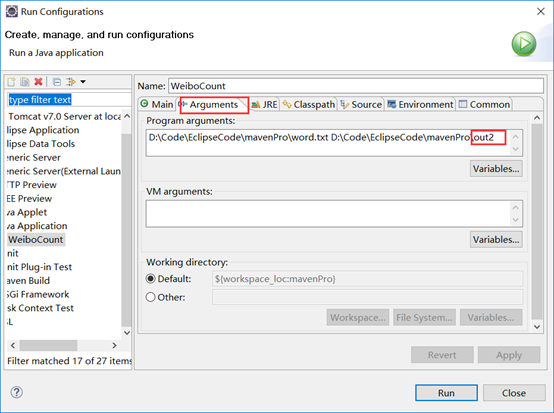
设置输入输出路径
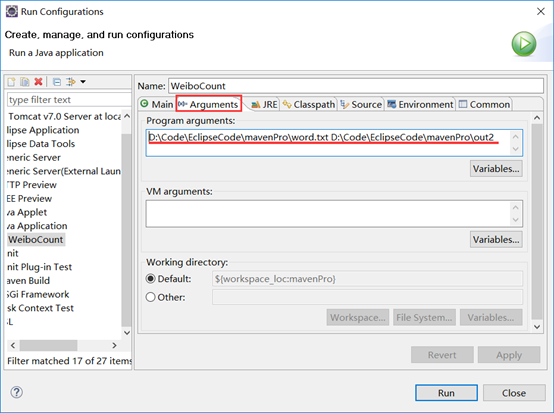
然后点击运行。
运行结果如下:
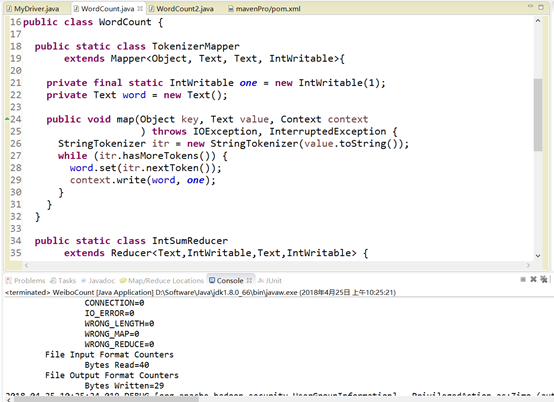
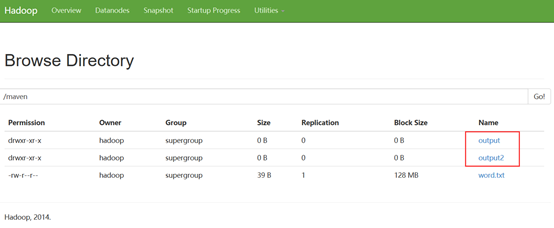
输出目录如下


那么,Maven如何管理多个MapReduce程序呢?
我们再新建一个MapReduce程序,于是我又新建了一个2.0版本的WordCount类WordCount2.java。然后配置方法同上,只是输出路径要修改一下。
运行结果如下
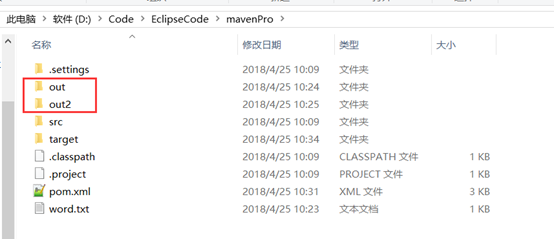
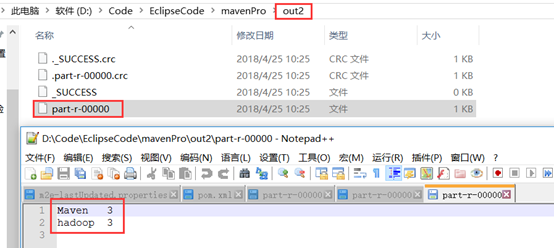
根据以上的本地调试证明两个MapReduce程序都没有问题,以下就是多个MapReduce程序的管理。
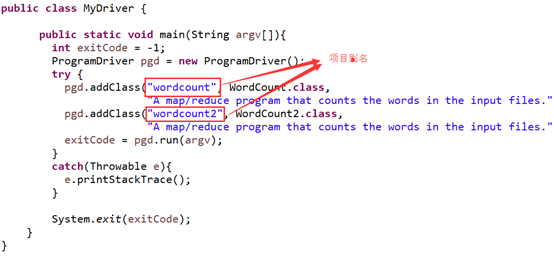
Maven是通过ProgramDriver类来进行管理的。首先我们先新建一个MyDriver类,代码如下:
MyDriver.javapackage com.hadoop.mavenPro;import org.apache.hadoop.util.ProgramDriver;/** * @author Zimo * */public class MyDriver { public static void main(String argv[]){ int exitCode = -1; ProgramDriver pgd = new ProgramDriver(); try { pgd.addClass("wordcount", WordCount.class, //设置项目别名 "A map/reduce program that counts the words in the input files."); //添加项目描述 pgd.addClass("wordcount2", WordCount2.class, "A map/reduce program that counts the words in the input files."); exitCode = pgd.run(argv); } catch(Throwable e){ e.printStackTrace(); } System.exit(exitCode); }} 通过cmd命令行打包项目:进入项目路径->clean->package。
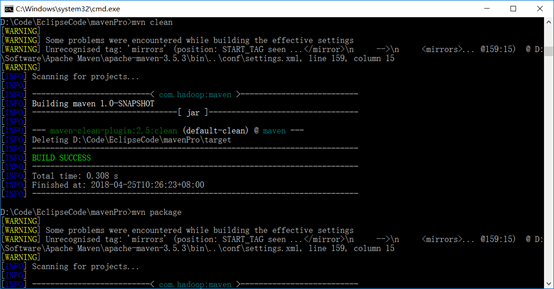

然后回到Eclipse,右键项目刷新一下,target目录下也出现了相应的jar包了,可以直接上传到Hadoop集群运行。
然后登陆到Hadoop集群并启动。
[hadoop@centpy ~]$ cd $HADOOP_HOME //进入Hadoop路径[hadoop@centpy hadoop-2.6.0]$ pwd/usr/hadoop/hadoop-2.6.0 [hadoop@centpy hadoop-2.6.0]$ sbin/start-all.sh //启动集群This script is Deprecated. Instead use start-dfs.sh and start-yarn.shStarting namenodes on [centpy]centpy: starting namenode, logging to /usr/hadoop/hadoop-2.6.0/logs/hadoop-hadoop-namenode-centpy.outcentpy: starting datanode, logging to /usr/hadoop/hadoop-2.6.0/logs/hadoop-hadoop-datanode-centpy.outStarting secondary namenodes [0.0.0.0]0.0.0.0: starting secondarynamenode, logging to /usr/hadoop/hadoop-2.6.0/logs/hadoop-hadoop-secondarynamenode-centpy.outstarting yarn daemonsstarting resourcemanager, logging to /usr/hadoop/hadoop-2.6.0/logs/yarn-hadoop-resourcemanager-centpy.outcentpy: starting nodemanager, logging to /usr/hadoop/hadoop-2.6.0/logs/yarn-hadoop-nodemanager-centpy.out[hadoop@centpy hadoop-2.6.0]$ jps2113 NameNode2643 NodeManager2212 DataNode2794 Jps2542 ResourceManager2399 SecondaryNameNode
新建一个文件夹用于该项目文件的存放。
[hadoop@centpy hadoop-2.6.0]$ hadoop fs -mkdir /maven[hadoop@centpy hadoop-2.6.0]$ hadoop fs -ls /Found 7 itemsdrwxr-xr-x - hadoop hadoop 0 2018-04-14 14:20 /hdfsOutputdrwxr-xr-x - hadoop supergroup 0 2018-04-25 09:37 /mavendrwxrwxrwx - hadoop supergroup 0 2018-04-13 22:10 /phonedrwxr-xr-x - hadoop hadoop 0 2018-04-14 14:43 /testdrwx------ - hadoop hadoop 0 2018-04-13 22:10 /tmpdrwxr-xr-x - hadoop hadoop 0 2018-04-14 14:34 /weatherdrwxr-xr-x - hadoop hadoop 0 2018-04-14 15:04 /weibo
上传一个输入文件到/maven。
上传项目jar包
[hadoop@centpy hadoop-2.6.0]$ rz //上传之前打包的jar文件 [hadoop@centpy hadoop-2.6.0]$ lsbin lib libhadoop.so.1.0.0 LICENSE.txt sbin word.txtdata libexec libhadooputils.a logs shareetc libhadoop.a libhdfs.a maven-1.0-SNAPSHOT.jar Temperature.jarinclude libhadooppipes.a libhdfs.so NOTICE.txt WeiboCount.jarjar libhadoop.so libhdfs.so.0.0.0 README.txt WordCount.jar
运行项目
[hadoop@centpy hadoop-2.6.0]$ hadoop jar maven-1.0-SNAPSHOT.jar wordcount /maven/word.txt /maven/output //运行程序 //由于pom.xml中配置了主类,出现可以直接找到Driver类,所以不用再像以前一样写全包路径,直接写Driver类中的项目别名就行了!18/04/25 10:35:02 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:803218/04/25 10:35:03 WARN mapreduce.JobSubmitter: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.18/04/25 10:35:14 INFO input.FileInputFormat: Total input paths to process : 118/04/25 10:35:14 INFO mapreduce.JobSubmitter: number of splits:118/04/25 10:35:15 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1524619938432_000118/04/25 10:35:15 INFO impl.YarnClientImpl: Submitted application application_1524619938432_000118/04/25 10:35:15 INFO mapreduce.Job: The url to track the job: http://centpy:8088/proxy/application_1524619938432_0001/18/04/25 10:35:15 INFO mapreduce.Job: Running job: job_1524619938432_000118/04/25 10:35:41 INFO mapreduce.Job: Job job_1524619938432_0001 running in uber mode : false18/04/25 10:35:41 INFO mapreduce.Job: map 0% reduce 0%18/04/25 10:35:52 INFO mapreduce.Job: map 100% reduce 0%18/04/25 10:36:04 INFO mapreduce.Job: map 100% reduce 100%18/04/25 10:36:05 INFO mapreduce.Job: Job job_1524619938432_0001 completed successfully18/04/25 10:36:05 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=31 FILE: Number of bytes written=211407 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=137 HDFS: Number of bytes written=17 HDFS: Number of read operations=6 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=1 Launched reduce tasks=1 Data-local map tasks=1 Total time spent by all maps in occupied slots (ms)=8939 Total time spent by all reduces in occupied slots (ms)=6521 Total time spent by all map tasks (ms)=8939 Total time spent by all reduce tasks (ms)=6521 Total vcore-seconds taken by all map tasks=8939 Total vcore-seconds taken by all reduce tasks=6521 Total megabyte-seconds taken by all map tasks=9153536 Total megabyte-seconds taken by all reduce tasks=6677504 Map-Reduce Framework Map input records=3 Map output records=6 Map output bytes=63 Map output materialized bytes=31 Input split bytes=98 Combine input records=6 Combine output records=2 Reduce input groups=2 Reduce shuffle bytes=31 Reduce input records=2 Reduce output records=2 Spilled Records=4 Shuffled Maps =1 Failed Shuffles=0 Merged Map outputs=1 GC time elapsed (ms)=283 CPU time spent (ms)=3120 Physical memory (bytes) snapshot=302731264 Virtual memory (bytes) snapshot=4132818944 Total committed heap usage (bytes)=161746944 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=39 File Output Format Counters Bytes Written=17
输出结果可以从浏览器进入文件系统查看。
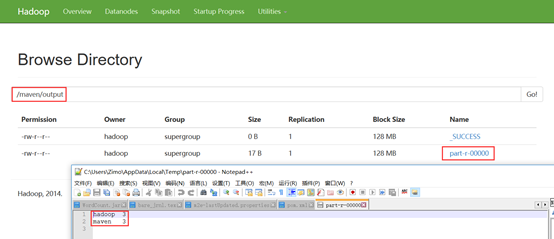
同样,运行我们的2.0版本的WordCount程序只需要将运行命令中的wordcount修改为wordcount2即可。
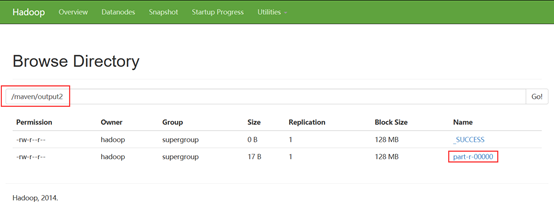
运行后文件系统中也出现了结果目录
到此,通过Maven框架管理多个MapReduce项目的步骤就到此结束了,大家可以多建几个MapReduce项目进行进一步测试。
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!
版权声明:本文为博主原创文章,未经博主允许不得转载。
转载地址:https://blog.csdn.net/py_123456/article/details/80077012 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
