本文共 6880 字,大约阅读时间需要 22 分钟。
1. MapReduce计数器是什么
计数器是用来记录Job的执行进度和状态的,其作用类似于日志。我们可以在程序的某个位置插入计数器,记录数据或进度的变化情况。
2. MapReduce计数器能做什么
计数器为我们提供了一个窗口,用于观察Job运行期间的各种细节数据,对MapReduce的性能调优很有帮助,MapReduce性能优化的评估大部分都是基于这些计数器Counter的数值来表现的。
3. MapReduce都有哪些内置计数器
MapReduce中自带了许多默认的Counter计数器,要了解这些内置计数器,必须知道计数组名称(groupName)和计数器名称(counterName)。
(1)任务计数器
在任务技术过程中,它负责采集任务的主要信息,每个作业的所有任务的结果都会被聚集起来。下面以MapReduce人事物计数器为例:
groupName:org.apache.hadoop.mapreduce.TaskCounter
counterName:
1)MAP_INPUT_RECORDS
2)REDUICE_INPUT_RECORDS
3)CPU_MILLISECONDS
(2)作业计数器
作业计数器由JobTracker或者YARN维护维护,因此无需在网络间传输数据。这些计数器都是作业级别的通缉量,其值不会随着任务运行而改变。
groupName:org.apache.hadoop.mapreduce.JobCounter
counterName:
1)TOTAL_LAUNCHED_MAPS
2)TOTAL_LAUNCHED_REDUCES
4. 计数器该如何使用
(1)定义计数器
1)枚举声明计数器
Contex contex…
//自定义枚举变量
Counter counter = contex.getCounter(Enum eum)
2)自定义计数器
Contex contex…
//自己命名groupName和counterName
Counter counter = contex.getCounter(String groupName, String counterName)
(2)为计数器赋值
1) 初始化计数器
counter.setValue(long value);//设置初始值
2) 计数器自增
counter.increment(long incr);//增加计数
(3) 获取计数器的值
1) 获取枚举计数器的值
Job job…
job.waitForCompletion(true);
Counters counters = job.getCounters();
Counter counter = counters.findCounter(BAD_RECORDS);
//查找枚举计数器,假如Enum的变量为BAD_RECORDS
long value = counter.getValue();//获取计数值
2) 获取自定义计数器的值
Job job...
job.waitForCompletion(true);
Counters counters = job.getCounters();
Counter counter = counters.findCounter("ErrorCounter","toolong");
//假如groupName为ErrorCounter,counterName为toolong
long value = counter.getValue();//获取计数值
3)获取内置计数器的值
Job job...
job.waitForCompletion(true);
Counters counters = job.getCounters();
Counter counter = counters.findCounter("org.apache.hadoop.mapreduce.JobCounter","TOTAL_LAUNCHED_ REDUCES");
//假如groupName为org.apache.hadoop.mapreduce.JobCounter,counterName为TOTAL_LAUNCHED_REDUCES
long value=counter.getValue();//获取计数值
4)获取所有计数器的值
Counters counters = job.getCounters();
for (CounterGroup group : counters) {
for (Counter counter : group) {
System.out.println(counter.getDisplayName() + ": " + counter.getName() + ": "+ counter.getValue());
}
}
5. 自定义计数器
自定义计数器用的比较广泛,特别是统计无效数据条数的时候,我们就会用到计数器来记录错误日志的条数。下面我们自定义计数器,统计输入的无效数据。
数据集
假如一个文件,规范的格式是3个字段,“\t”作为分隔符,其中有2条异常数据,一条数据是只有2个字段,一条数据是有4个字段。其内容如下所示:
jim 1 28
kate 0 26
tom 1
kaka 1 22
lily 0 29 22
启动Hadoop集群,然后在HDFS中新建目录存放测试数据。
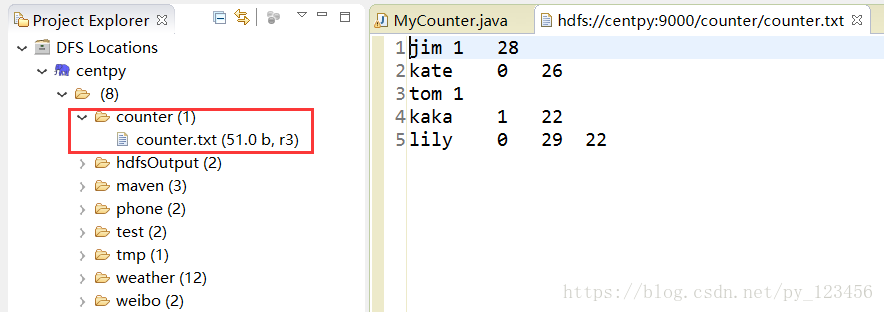
在Hadoop项目下新建MyCounter.java类
package com.hadoop.Counter;import java.io.IOException;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.conf.Configured;import org.apache.hadoop.fs.FileSystem;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import org.apache.hadoop.util.Tool;import org.apache.hadoop.util.ToolRunner;/** * @author Zimo * MapReduce计数器 */public class MyCounter extends Configured implements Tool { /** * @param args */ public static class MyCounterMap extends Mapper { //定义枚举对象 public static enum LOG_PROCESSOR_COUNTER { //枚举对象BAD_RECORDS_LONG来统计长数据,枚举对象BAD_RECORDS_SHORT来统计短数据 BAD_RECORDS_LONG, BAD_RECORDS_SHORT }; protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String arr_values[] = value.toString().split("/t"); if (arr_values.length > 3) { //动态自定义计数器 context.getCounter("ErrorCounter", "toolong").increment(1); //枚举声明计数器 context.getCounter(LOG_PROCESSOR_COUNTER.BAD_RECORDS_LONG).increment(1); } else if(arr_values.length < 3) { // 动态自定义计数器 context.getCounter("ErrorCounter", "tooshort").increment(1); // 枚举声明计数器 context.getCounter(LOG_PROCESSOR_COUNTER.BAD_RECORDS_SHORT).increment(1); } else { context.write(value, new Text("")); } } } public int run(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration conf = new Configuration(); Path myPath = new Path(args[1]); FileSystem hdfs = myPath.getFileSystem(conf); if (hdfs.isDirectory(myPath)) { hdfs.delete(myPath); } Job job = new Job(conf, "MyCounter"); job.setJarByClass(MyCounter.class); job.setMapperClass(MyCounterMap.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitForCompletion(true); return 0; } public static void main(String[] args) throws Exception { // TODO Auto-generated method stub String[] arg0 = { "hdfs://centpy:9000/counter/counter.txt", "hdfs://centpy:9000/counter/out" }; int ec = ToolRunner.run(new Configuration(), new MyCounter(), arg0); System.exit(ec); }} 运行程序之后,日志如下所示。
2018-05-08 16:43:45,146 INFO [org.apache.hadoop.mapreduce.Job] - Counters: 34 File System Counters FILE: Number of bytes read=314 FILE: Number of bytes written=368622 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=102 HDFS: Number of bytes written=0 HDFS: Number of read operations=15 HDFS: Number of large read operations=0 HDFS: Number of write operations=6 Map-Reduce Framework Map input records=5 Map output records=0 Map output bytes=0 Map output materialized bytes=6 Input split bytes=103 Combine input records=0 Combine output records=0 Reduce input groups=0 Reduce shuffle bytes=0 Reduce input records=0 Reduce output records=0 Spilled Records=0 Shuffled Maps =0 Failed Shuffles=0 Merged Map outputs=0 GC time elapsed (ms)=53 CPU time spent (ms)=0 Physical memory (bytes) snapshot=0 Virtual memory (bytes) snapshot=0 Total committed heap usage (bytes)=830472192 ErrorCounter tooshort=5 com.hadoop.Counter.MyCounter$MyCounterMap$LOG_PROCESSOR_COUNTER BAD_RECORDS_SHORT=5 File Input Format Counters Bytes Read=51 File Output Format Counters Bytes Written=0
从日志中可以看出,通过枚举声明和自定义计数器两种方式,统计出的不规范数据是一样的。
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!
版权声明:本文为博主原创文章,未经博主允许不得转载。
转载地址:https://blog.csdn.net/py_123456/article/details/80242204 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
