机器学习——使用ID3算法从原理到实际举例理解决策树

发布日期:2021-06-22 22:48:22
浏览次数:3
分类:技术文章
本文共 15169 字,大约阅读时间需要 50 分钟。
文章目录
一、什么是决策树
- 基本概念 决策树是一种树形结构,其组成包括结点(node)和有向边(directed edge)。而结点有两种类型,分别是内部结点(internal node)和叶结点(leaf node)。其中每个内部结点表示一个属性(特征),每个叶节点表示一个类别。由此看来,决策树是一种常用的分类的机器学习方法。
- 实际举例说明 相亲对象分类系统的一个简单决策树构建,其中长方形和椭圆形都是结点。长方形的结点属于内部结点,椭圆形的结点属于叶结点,从结点引出的左右箭头就是有向边。也可以解释为有无房子和有无上进心作为特征,值得考虑,备胎,Say Goodbye作为划分的类别。从下面图中可以得到结论是当相亲对象有房子划分为可以考虑,没有房子但有上进心划分为备胎,既没有房子也没有上进心的划分为Say Goodbye。
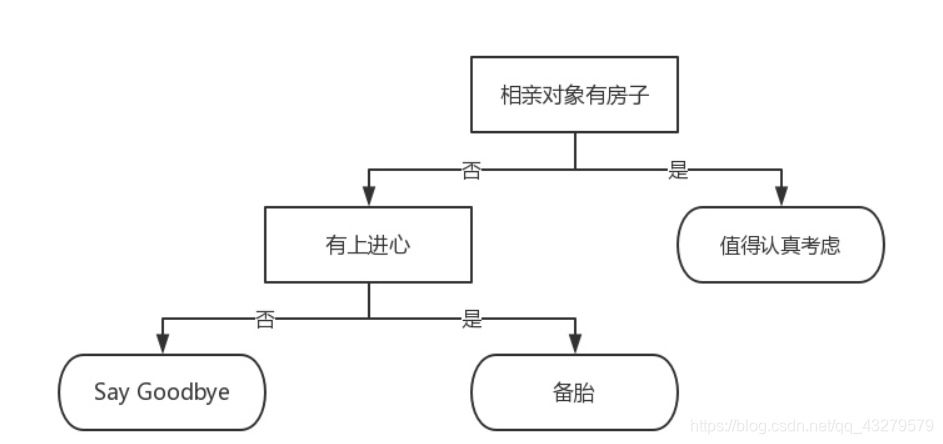 通过上面的实际举例,可以简单的了解到决策树的基本构成。然而,实际分类中,一般存在多个特征量,所以,可以构建多种树(内部结点代表不同),如何得到最优的那个树便成了一个思考的问题。
通过上面的实际举例,可以简单的了解到决策树的基本构成。然而,实际分类中,一般存在多个特征量,所以,可以构建多种树(内部结点代表不同),如何得到最优的那个树便成了一个思考的问题。
二、介绍建立决策树的算法
- ID3算法 使用信息增益进行特征选择 ①某个分类的信息 l ( x i ) = − l o g 2 P ( x i ) {l(x_i)=-log_2P(x_i)} l(xi)=−log2P(xi) (其中 p ( x i ) {p(x_i)} p(xi)是选择该分类的概率) ②熵 在信息论与概率统计中,熵是表示随机变量不确定性的度量。熵定义为信息的期望值,所以熵的计算方法 H = − ∑ i = 1 n P ( x i ) l o g 2 P ( x i ) {H=- \displaystyle\sum_{i=1}^nP(x_i)log_2P(x_i)} H=−i=1∑nP(xi)log2P(xi) (其中n是分类的数目) ③经验熵 熵中的概率由数据估计(特别是最大似然估计)得到 在|D|样本容量(样本个数)下,设有K个类Ck, = 1,2,3,…,K,|Ck|为属于类Ck的样本个数,得到其表达式如下 H ( D ) = − ∑ k = 1 K ∣ C k ∣ ∣ D ∣ l o g 2 ∣ C k ∣ ∣ D ∣ {H(D)=- \displaystyle\sum_{k=1}^K\frac{|C_k|}{|D|}log_2\frac{|C_k|}{|D|}} H(D)=−k=1∑K∣D∣∣Ck∣log2∣D∣∣Ck∣ ④条件熵 在已知随机变量X的条件下随机变量Y的不确定性,随机变量X给定的条件下随机变量Y的条件熵H(Y|X),定义为X给定条件下Y的条件概率分布的熵对X的数学期望 H ( Y ∣ X ) = ∑ i = 1 n p i H ( Y ∣ X = x i ) {H(Y|X)= \displaystyle\sum_{i=1}^np_iH(Y|X=x_i)} H(Y∣X)=i=1∑npiH(Y∣X=xi) ⑤信息增益 集合D的经验熵H(D)与特征A给定条件下D的经验条件熵H(D|A)之差 g ( D , A ) = H ( D ) − H ( D ∣ A ) {g(D,A)=H(D)-H(D|A)} g(D,A)=H(D)−H(D∣A)
说明:特征所对应的信息增益值最大,该特征就为最优特征,也就是说信息增益越大,越应该放在决策树的上层 - C4.5 使用信息增益率进行特征选择
- CART 使用基尼指数进行特征选择
一个属性的
信息增益/基尼指数越大,表明该属性对于样本的熵减少的能力更强,同时使数据由不确定性变为确定性的能力更强。本文章重点说明ID3算法。
三、决策树的一般流程
- 收集数据 可以使用任何方法。
- 准备数据 树构造算法只适用于标称型数据,因此数值型数据必须离散化。
- 分析数据 可以使用任何方法,构造树完成之后,我们应该检查图形是否符合预期。
- 训练算法 构造树的数据结构。
- 测试算法 使用经验树计算错误率。
- 使用算法 此步骤可以适用于任何监督学习算法,而使用决策树可以更好地理解数据 的内在含义。
四、实际举例构建决策树
贷款申请样本数据表
使用ID3算法的原理实现构建决策树
- 特征选择 ①数据集进行属性标注 年龄:0代表青年,1代表中年,2代表老年; 有工作:0代表否,1代表是; 有自己的房子:0代表否,1代表是; 信贷情况:0代表一般,1代表好,2代表非常好; 类别(是否给贷款):no代表否,yes代表是 代码
from math import logdef createDataSet():dataSet = [[0, 0, 0, 0, 'no'], #数据集 [0, 0, 0, 1, 'no'], [0, 1, 0, 1, 'yes'], [0, 1, 1, 0, 'yes'], [0, 0, 0, 0, 'no'], [1, 0, 0, 0, 'no'], [1, 0, 0, 1, 'no'], [1, 1, 1, 1, 'yes'], [1, 0, 1, 2, 'yes'], [1, 0, 1, 2, 'yes'], [2, 0, 1, 2, 'yes'], [2, 0, 1, 1, 'yes'], [2, 1, 0, 1, 'yes'], [2, 1, 0, 2, 'yes'], [2, 0, 0, 0, 'no']]labels = ['年龄', '有工作', '有自己的房子', '信贷情况'] #特征标签labels1=['放贷','不放贷']return dataSet, labels,labels1 #返回数据集和特征标签和分类标签
②计算经验熵H(D) 数学计算方式 H ( D ) = − 9 15 l o g 2 9 15 − 6 15 l o g 2 6 15 = 0.971 {H(D)=-\frac{9}{15}log_2\frac{9}{15}-\frac{6}{15}log_2\frac{6}{15}=0.971} H(D)=−159log2159−156log2156=0.971 代码计算方式def calcShannonEnt(dataSet):numEntires = len(dataSet) #返回数据集的行数labelCounts = { } #保存每个标签(Label)出现次数的字典for featVec in dataSet: #对每组特征向量进行统计 currentLabel = featVec[-1] #提取标签(Label)信息 if currentLabel not in labelCounts.keys(): #如果标签(Label)没有放入统计次数的字典,添加进去 labelCounts[currentLabel] = 0 labelCounts[currentLabel] += 1 #Label计数shannonEnt = 0.0 #经验熵(香农熵)for key in labelCounts: #计算香农熵 prob = float(labelCounts[key]) / numEntires #选择该标签(Label)的概率 shannonEnt -= prob * log(prob, 2) #利用公式计算return shannonEnt #返回经验熵(香农熵)if __name__ == '__main__':dataSet, features = createDataSet()print(dataSet)print(calcShannonEnt(dataSet)) ③计算信息增益 数学计算 年龄的信息增益(其中 D 1 , D 2 , D 3 {D_1,D_2,D_3} D1,D2,D3表示青年,中年,老年) g ( D , A 1 ) = H ( D ) − [ 5 15 H ( D 1 ) + ] 5 15 H ( D 2 ) + 5 15 H ( D 3 ) ] = 0.971 − [ 5 15 ( − 2 5 l o g 2 2 5 − 3 5 l o g 2 3 5 ) + 5 15 ( − 3 5 l o g 2 3 5 − 2 5 l o g 2 2 5 ) + 5 15 ( − 4 5 l o g 2 4 5 − 1 5 l o g 2 1 5 ) ] = 0.971 − 0.888 = 0.083 {\begin{aligned} g(D,A_1)&=H(D)-[\frac{5}{15}H(D_1)+]\frac{5}{15}H(D_2)+\frac{5}{15}H(D_3)] \\&=0.971-[\frac{5}{15}(-\frac{2}{5}log_2\frac{2}{5}-\frac{3}{5}log_2\frac{3}{5})+\frac{5}{15}(-\frac{3}{5}log_2\frac{3}{5}-\frac{2}{5}log_2\frac{2}{5})+\frac{5}{15}(-\frac{4}{5}log_2\frac{4}{5}-\frac{1}{5}log_2\frac{1}{5})] \\&=0.971-0.888=0.083 \end{aligned} } g(D,A1)=H(D)−[155H(D1)+]155H(D2)+155H(D3)]=0.971−[155(−52log252−53log253)+155(−53log253−52log252)+155(−54log254−51log251)]=0.971−0.888=0.083 同理可以计算其他三种特征的信息增益如下 有无工作的信息增益 g ( D , A 2 ) = H ( D ) − [ 5 15 H ( D 1 ) + ] 10 15 H ( D 2 ) ] = 0.971 − [ 5 15 × 0 + 10 15 ( − 4 10 l o g 2 4 10 − 6 10 l o g 2 6 10 ) ] = 0.971 − 0.647 = 0.324 {\begin{aligned} g(D,A_2)&=H(D)-[\frac{5}{15}H(D_1)+]\frac{10}{15}H(D_2)] \\&=0.971-[\frac{5}{15}\times0+\frac{10}{15}(-\frac{4}{10}log_2\frac{4}{10}-\frac{6}{10}log_2\frac{6}{10})] \\&=0.971-0.647=0.324 \end{aligned}} g(D,A2)=H(D)−[155H(D1)+]1510H(D2)]=0.971−[155×0+1510(−104log2104−106log2106)]=0.971−0.647=0.324 有无房子的信息增益 g ( D , A 3 ) = H ( D ) − [ 6 15 H ( D 1 ) + ] 9 15 H ( D 2 ) ] = 0.971 − [ 6 15 × 0 + 9 15 ( − 3 9 l o g 2 3 9 − 6 9 l o g 2 6 9 ) ] = 0.971 − 0.551 = 0.420 {\begin{aligned} g(D,A_3)&=H(D)-[\frac{6}{15}H(D_1)+]\frac{9}{15}H(D_2)] \\&=0.971-[\frac{6}{15}\times0+\frac{9}{15}(-\frac{3}{9}log_2\frac{3}{9}-\frac{6}{9}log_2\frac{6}{9})] \\&=0.971-0.551=0.420 \end{aligned}} g(D,A3)=H(D)−[156H(D1)+]159H(D2)]=0.971−[156×0+159(−93log293−96log296)]=0.971−0.551=0.420 信贷情况的信息增益 g ( D , A 4 ) = 0.971 − 0.608 = 0.363 {g(D,A_4)=0.971-0.608=0.363} g(D,A4)=0.971−0.608=0.363 代码计算
③计算信息增益 数学计算 年龄的信息增益(其中 D 1 , D 2 , D 3 {D_1,D_2,D_3} D1,D2,D3表示青年,中年,老年) g ( D , A 1 ) = H ( D ) − [ 5 15 H ( D 1 ) + ] 5 15 H ( D 2 ) + 5 15 H ( D 3 ) ] = 0.971 − [ 5 15 ( − 2 5 l o g 2 2 5 − 3 5 l o g 2 3 5 ) + 5 15 ( − 3 5 l o g 2 3 5 − 2 5 l o g 2 2 5 ) + 5 15 ( − 4 5 l o g 2 4 5 − 1 5 l o g 2 1 5 ) ] = 0.971 − 0.888 = 0.083 {\begin{aligned} g(D,A_1)&=H(D)-[\frac{5}{15}H(D_1)+]\frac{5}{15}H(D_2)+\frac{5}{15}H(D_3)] \\&=0.971-[\frac{5}{15}(-\frac{2}{5}log_2\frac{2}{5}-\frac{3}{5}log_2\frac{3}{5})+\frac{5}{15}(-\frac{3}{5}log_2\frac{3}{5}-\frac{2}{5}log_2\frac{2}{5})+\frac{5}{15}(-\frac{4}{5}log_2\frac{4}{5}-\frac{1}{5}log_2\frac{1}{5})] \\&=0.971-0.888=0.083 \end{aligned} } g(D,A1)=H(D)−[155H(D1)+]155H(D2)+155H(D3)]=0.971−[155(−52log252−53log253)+155(−53log253−52log252)+155(−54log254−51log251)]=0.971−0.888=0.083 同理可以计算其他三种特征的信息增益如下 有无工作的信息增益 g ( D , A 2 ) = H ( D ) − [ 5 15 H ( D 1 ) + ] 10 15 H ( D 2 ) ] = 0.971 − [ 5 15 × 0 + 10 15 ( − 4 10 l o g 2 4 10 − 6 10 l o g 2 6 10 ) ] = 0.971 − 0.647 = 0.324 {\begin{aligned} g(D,A_2)&=H(D)-[\frac{5}{15}H(D_1)+]\frac{10}{15}H(D_2)] \\&=0.971-[\frac{5}{15}\times0+\frac{10}{15}(-\frac{4}{10}log_2\frac{4}{10}-\frac{6}{10}log_2\frac{6}{10})] \\&=0.971-0.647=0.324 \end{aligned}} g(D,A2)=H(D)−[155H(D1)+]1510H(D2)]=0.971−[155×0+1510(−104log2104−106log2106)]=0.971−0.647=0.324 有无房子的信息增益 g ( D , A 3 ) = H ( D ) − [ 6 15 H ( D 1 ) + ] 9 15 H ( D 2 ) ] = 0.971 − [ 6 15 × 0 + 9 15 ( − 3 9 l o g 2 3 9 − 6 9 l o g 2 6 9 ) ] = 0.971 − 0.551 = 0.420 {\begin{aligned} g(D,A_3)&=H(D)-[\frac{6}{15}H(D_1)+]\frac{9}{15}H(D_2)] \\&=0.971-[\frac{6}{15}\times0+\frac{9}{15}(-\frac{3}{9}log_2\frac{3}{9}-\frac{6}{9}log_2\frac{6}{9})] \\&=0.971-0.551=0.420 \end{aligned}} g(D,A3)=H(D)−[156H(D1)+]159H(D2)]=0.971−[156×0+159(−93log293−96log296)]=0.971−0.551=0.420 信贷情况的信息增益 g ( D , A 4 ) = 0.971 − 0.608 = 0.363 {g(D,A_4)=0.971-0.608=0.363} g(D,A4)=0.971−0.608=0.363 代码计算"""函数说明:按照给定特征划分数据集Parameters: dataSet - 待划分的数据集 axis - 划分数据集的特征 value - 需要返回的特征的值"""def splitDataSet(dataSet, axis, value): retDataSet = [] #创建返回的数据集列表 for featVec in dataSet: #遍历数据集 if featVec[axis] == value: reducedFeatVec = featVec[:axis] #去掉axis特征 reducedFeatVec.extend(featVec[axis+1:]) #将符合条件的添加到返回的数据集 retDataSet.append(reducedFeatVec) return retDataSet #返回划分后的数据集"""函数说明:选择最优特征 Parameters: dataSet - 数据集Returns: bestFeature - 信息增益最大的(最优)特征的索引值"""def chooseBestFeatureToSplit(dataSet): numFeatures = len(dataSet[0]) - 1 #特征数量 baseEntropy = calcShannonEnt(dataSet) #计算数据集的香农熵 bestInfoGain = 0.0 #信息增益 bestFeature = -1 #最优特征的索引值 for i in range(numFeatures): #遍历所有特征 #获取dataSet的第i个所有特征 featList = [example[i] for example in dataSet] uniqueVals = set(featList) #创建set集合{},元素不可重复 newEntropy = 0.0 #经验条件熵 for value in uniqueVals: #计算信息增益 subDataSet = splitDataSet(dataSet, i, value) #subDataSet划分后的子集 prob = len(subDataSet) / float(len(dataSet)) #计算子集的概率 newEntropy += prob * calcShannonEnt(subDataSet) #根据公式计算经验条件熵 infoGain = baseEntropy - newEntropy #信息增益 print("第%d个特征的增益为%.3f" % (i, infoGain)) #打印每个特征的信息增益 if (infoGain > bestInfoGain): #计算信息增益 bestInfoGain = infoGain #更新信息增益,找到最大的信息增益 bestFeature = i #记录信息增益最大的特征的索引值 return bestFeature #返回信息增益最大的特征的索引值if __name__ == '__main__': dataSet, features = createDataSet() print("最优特征索引值:" + str(chooseBestFeatureToSplit(dataSet)))
通过上面数学计算或者代码计算结果,可以看出特征A3(有自己的房子)的信息增益值最大,所以选择A3作为最优特征(根节点)根据根节点,将训练集D划分为两个子集D1(A3取值为"是")和D2(A3取值为"否")。从数据集中可以发现D1只有同一类的样本点,所以它成为一个叶结点,结点的类标记为“是”(同意放贷),对应另外一个叶节点的确定方式是在D2数据样本中,选出信息增益最大的作为此叶节点,也可以理解为在D2数据集中,从除有无房子以外的特征选出一个新的特征,作为叶节点。实际此过程就是一个递归的过程。 - 决策树的生成
"""函数说明:统计classList中出现此处最多的元素(类标签)Parameters: classList - 类标签列表Returns: sortedClassCount[0][0] - 出现此处最多的元素(类标签)"""def majorityCnt(classList): classCount = { } for vote in classList: #统计classList中每个元素出现的次数 if vote not in classCount.keys():classCount[vote] = 0 classCount[vote] += 1 sortedClassCount = sorted(classCount.items(), key = operator.itemgetter(1), reverse = True) #根据字典的值降序排序 return sortedClassCount[0][0] #返回classList中出现次数最多的元素"""函数说明:创建决策树Parameters: dataSet - 训练数据集 labels - 分类属性标签 featLabels - 存储选择的最优特征标签Returns: myTree - 决策树"""def createTree(dataSet, labels, featLabels): classList = [example[-1] for example in dataSet] #取分类标签(是否放贷:yes or no) if classList.count(classList[0]) == len(classList): #如果类别完全相同则停止继续划分 return classList[0] if len(dataSet[0]) == 1 or len(labels) == 0: #遍历完所有特征时返回出现次数最多的类标签 return majorityCnt(classList) bestFeat = chooseBestFeatureToSplit(dataSet) #选择最优特征 bestFeatLabel = labels[bestFeat] #最优特征的标签 featLabels.append(bestFeatLabel) myTree = { bestFeatLabel:{ }} #根据最优特征的标签生成树 del(labels[bestFeat]) #删除已经使用特征标签 featValues = [example[bestFeat] for example in dataSet] #得到训练集中所有最优特征的属性值 uniqueVals = set(featValues) #去掉重复的属性值 for value in uniqueVals: #遍历特征,创建决策树。 subLabels = labels[:] myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), subLabels, featLabels) return myTreeif __name__ == '__main__': dataSet, labels,labels1 = createDataSet() featLabels = [] myTree = createTree(dataSet, labels, featLabels) print(myTree)
- 决策树的可视化
"""函数说明:获取决策树叶子结点的数目 Parameters: myTree - 决策树Returns: numLeafs - 决策树的叶子结点的数目"""def getNumLeafs(myTree): numLeafs = 0 #初始化叶子 firstStr = next(iter(myTree)) #python3中myTree.keys()返回的是dict_keys,不在是list,所以不能使用myTree.keys()[0]的方法获取结点属性,可以使用list(myTree.keys())[0] secondDict = myTree[firstStr] #获取下一组字典 for key in secondDict.keys(): if type(secondDict[key]).__name__=='dict': #测试该结点是否为字典,如果不是字典,代表此结点为叶子结点 numLeafs += getNumLeafs(secondDict[key]) else: numLeafs +=1 return numLeafs"""函数说明:获取决策树的层数Parameters: myTree - 决策树Returns: maxDepth - 决策树的层数"""def getTreeDepth(myTree): maxDepth = 0 #初始化决策树深度 firstStr = next(iter(myTree)) #python3中myTree.keys()返回的是dict_keys,不在是list,所以不能使用myTree.keys()[0]的方法获取结点属性,可以使用list(myTree.keys())[0] secondDict = myTree[firstStr] #获取下一个字典 for key in secondDict.keys(): if type(secondDict[key]).__name__=='dict': #测试该结点是否为字典,如果不是字典,代表此结点为叶子结点 thisDepth = 1 + getTreeDepth(secondDict[key]) else: thisDepth = 1 if thisDepth > maxDepth: maxDepth = thisDepth #更新层数 return maxDepth """函数说明:绘制结点Parameters: nodeTxt - 结点名 centerPt - 文本位置 parentPt - 标注的箭头位置 nodeType - 结点格式"""def plotNode(nodeTxt, centerPt, parentPt, nodeType): arrow_args = dict(arrowstyle="<-") #定义箭头格式 font = FontProperties(fname=r"c:\windows\fonts\simsun.ttc", size=14) #设置中文字体 createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction', #绘制结点 xytext=centerPt, textcoords='axes fraction', va="center", ha="center", bbox=nodeType, arrowprops=arrow_args, FontProperties=font) """函数说明:标注有向边属性值Parameters: cntrPt、parentPt - 用于计算标注位置 txtString - 标注的内容"""def plotMidText(cntrPt, parentPt, txtString): xMid = (parentPt[0]-cntrPt[0])/2.0 + cntrPt[0] #计算标注位置 yMid = (parentPt[1]-cntrPt[1])/2.0 + cntrPt[1] createPlot.ax1.text(xMid, yMid, txtString, va="center", ha="center", rotation=30) """函数说明:绘制决策树Parameters: myTree - 决策树(字典) parentPt - 标注的内容 nodeTxt - 结点名"""def plotTree(myTree, parentPt, nodeTxt): decisionNode = dict(boxstyle="sawtooth", fc="0.8") #设置结点格式 leafNode = dict(boxstyle="round4", fc="0.8") #设置叶结点格式 numLeafs = getNumLeafs(myTree) #获取决策树叶结点数目,决定了树的宽度 depth = getTreeDepth(myTree) #获取决策树层数 firstStr = next(iter(myTree)) #下个字典 cntrPt = (plotTree.xOff + (1.0 + float(numLeafs))/2.0/plotTree.totalW, plotTree.yOff) #中心位置 plotMidText(cntrPt, parentPt, nodeTxt) #标注有向边属性值 plotNode(firstStr, cntrPt, parentPt, decisionNode) #绘制结点 secondDict = myTree[firstStr] #下一个字典,也就是继续绘制子结点 plotTree.yOff = plotTree.yOff - 1.0/plotTree.totalD #y偏移 for key in secondDict.keys(): if type(secondDict[key]).__name__=='dict': #测试该结点是否为字典,如果不是字典,代表此结点为叶子结点 plotTree(secondDict[key],cntrPt,str(key)) #不是叶结点,递归调用继续绘制 else: #如果是叶结点,绘制叶结点,并标注有向边属性值 plotTree.xOff = plotTree.xOff + 1.0/plotTree.totalW plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode) plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key)) plotTree.yOff = plotTree.yOff + 1.0/plotTree.totalD """函数说明:创建绘制面板Parameters: inTree - 决策树(字典)"""def createPlot(inTree): fig = plt.figure(1, facecolor='white') #创建fig fig.clf() #清空fig axprops = dict(xticks=[], yticks=[]) createPlot.ax1 = plt.subplot(111, frameon=False, **axprops) #去掉x、y轴 plotTree.totalW = float(getNumLeafs(inTree)) #获取决策树叶结点数目 plotTree.totalD = float(getTreeDepth(inTree)) #获取决策树层数 plotTree.xOff = -0.5/plotTree.totalW; plotTree.yOff = 1.0; #x偏移 plotTree(inTree, (0.5,1.0), '') #绘制决策树 plt.show() #显示绘制结果 if __name__ == '__main__': dataSet, labels = createDataSet() featLabels = [] myTree = createTree(dataSet, labels, featLabels) print(myTree) createPlot(myTree)
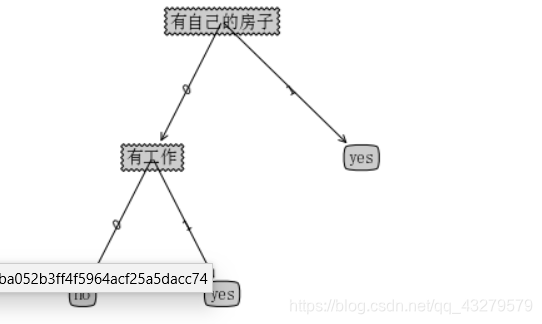 整个构建决策树的过程,重点理解如何进行信息增益的求。除此之外,需要理解递归的过程。
整个构建决策树的过程,重点理解如何进行信息增益的求。除此之外,需要理解递归的过程。
参考链接
转载地址:https://blog.csdn.net/qq_43279579/article/details/116660225 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
网站不错 人气很旺了 加油
[***.192.178.218]2024年04月08日 16时20分38秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
树莓派上创建个人用户
2019-04-27
树莓派CPU超频配置
2019-04-27
树莓派终端背景色调节
2019-04-27
树莓派U盘挂载位置
2019-04-27
对比Ubuntu与Win10的资源占用
2019-04-27
树莓派硬件启动失败log记录查看方法
2019-04-27
树莓派使用心得
2019-04-27
树莓派实现无显示器远程登录
2019-04-27
Samba服务实现树莓派与Windows之间的文件共享
2019-04-27
wiringpi安装编译问题解决
2019-04-27
Windows上创建Emacs配置文件
2019-04-27
编写并运行第一个Lisp程序
2019-04-27
VS code中godoc命令不可用问题解决
2019-04-27
Emacs-103-使用spacemacs自带配置显示行号
2019-04-27
021_Excel的条件格式
2019-04-27
022_Excel空白值批量填充默认值
2019-04-27
023_emacs git-gutter+报错解决
2019-04-27
024_spacemacs支持org-pomodoro的声音提示
2019-04-27
025_everything搜索使用体验
2019-04-27
026_好用的windows小工具clover
2019-04-27
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 307457949 位访客
访问时间: 2024-04-24 09:37:26
访问IP: 18.223.32.230
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版