本文共 3147 字,大约阅读时间需要 10 分钟。
H-mine算法
一种比较新的频繁项集挖掘算法——H-mine算法。
背景
之前的博客已经提到FP-growth将挖掘长频繁模式的问题转换为递归地搜索较短模式,然后连接后缀。该算法使用最不频繁的项作为后缀,提供了较好的选择性,使用该算法大大的降低了搜索开销。但是当数据量非常大时,构造基于内存的FP树是非常困难的。
传统频繁模式挖掘算法主要存在两个问题:一是算法需要的内存大小是不可预测的并且当数据集规模增大时,需要的内存也会随之剧增;二是在很多情况下算法效率是非常低或无法处理的,如密集型数据集、海量数据集。
主要思想
H-mine 算法一定程度上解决了上面提到的问题。H-mine是一种基于内存、高效的频繁模式挖掘算法,使用新的数据结构H-Struct,可以更快的遍历数据。理论上,H-mine 有多项式的空间复杂度,要比使用候选产生发现频繁项集和频繁模式增长方法更加节约空间。H-mine 通过对数据进行分区,每次只挖掘一个分区,最后将结果整合,极大的节约了内存并能处理更大规模数据集。实验证明H-mine 算法有极好的可扩展性并且在任何情况下综合性能都优于Apriori 算法和FP-growth 算法。
方法描述
同样地,为了更好地理解该算法,通过一个实例来说明H-mine算法的挖掘过程。
下表1的前面两列是示例事务数据库TDB。假设最小支持度计数为min_sup=2。
表1 示例事务数据库TDB
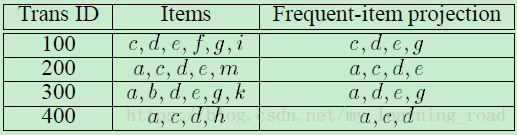
与Apriori算法相同,首先扫描TDB一遍,找到并输出频繁1项集{a:3,c:3,d:4,e:3,g:2},这里a:3表示项a的支持度计数为3。用freq(X)表示项集X(每个X对应每一个事务数据库)中的一组频繁项,也就是X的频繁项投影。每个事务的频繁项投影如表1第3列所示,比如TID=100的事务,它原来的项为c,d,e,f,g,i,但是f和i均不为频繁项,所以TID=100的事务的频繁项投影为c,d,e,g。其他的以此类推。
根据字母顺序将频繁项排列(称为F-list):a-c-d-e-g,那么最后想要得到的完整的频繁模式被分成5个子集:
- 那些包含项a的;
- 那些包含项c但是不包含项a的;
- 那些包含项d但是不包含项a也不包含项c的;
- 那些包含项e但是不包含项a、项c和项d的;
- 那些仅仅包含项g的。
根据上述的频繁项投影可以得到H-struct,如图1所示:所有在频繁项投影中的项都根据F-list排序。例如T100的频繁项投影被列为cdeg,每一个频繁项的item-id和hyper-link(指针)都被存储在H-struct中。
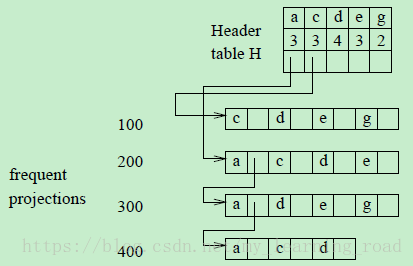
图1 H-struct
Header table H中有3个域:item-id,支持度计数和一个hyper-link(指针)。然后所有第一个项相同的事务会被指针链起来形成一个队列,而这个队列的头就是header table H中的结点。比如,在Header table H中的项a是a-队列的头结点,它链接了事务200、300和400的频繁线投影,因为这三个投影的第一个频繁项均为a;类似地,事务100被链接到c-队列,d-,e-和g-队列是空的,因为没有频繁项投影以这些项开头。
很明显,在建立H-struct时第二遍遍历了事务数据库TDB,但是后续的挖掘任务可以只在H-struct上进行,不再需要原始数据库,上面提到的5种频繁模式的子集可以被一一挖掘出来,挖掘过程如下:
(1)为了在频繁项投影中挖掘到所有包含a的项,需要建立一个a-projected database,记为TDB|a,而我们知道TDB|a中的频繁项投影早已经链接到a-队列上了。为了挖掘TDB|a,需要建立一个a-header table Ha,如图2所示。在Ha中,除了a本身之外,每个频繁项结点都有和H相同的3个域:item-id,支持度计数和一个hyper-link(指针)。Ha中的支持度计数记录的是在TDB|a中相对应的项的支持度计数。例如,在TDB|a中项c出现了2次,则Ha的结点c的支持度计数为2。
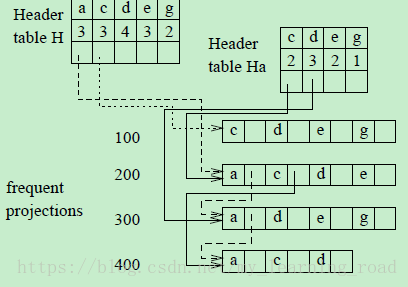
图2 Header table和ac-queue.
通过遍历一次a-queue,在TDB|a中至少出现2次的项被找到,即{c:2,d:3,e:2},注意因为在这里g:1不是频繁的,所以将会不会再考虑它。因此输出的频繁模式是{ac:2,ad:3,ae:2}。
(2)相似地,继续挖掘所有包含ac的项,先通过检查Ha中的c-队列建立一个ac-projected database,ac-projected建立了一个ac-header table Hac,如图3所示。
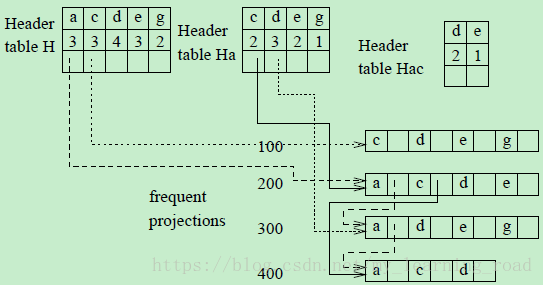
图3 Header table Hac
因为在ac-projected database中只有d是频繁项,所以只有acd:2被输出,而且这条路径已经完成了。
(3)递归回溯的寻找包含a和d不包含c的模式。因为以d开始的队列在head table Ha中也就是ad-队列,链接了所有包含a和d的项的频繁项投影(当然要排除掉c的投影),可以通过在ad-队列中插入ac-队列中有项d的频繁项投影来得到完整的ad-projected database。ac-队列中的每一个频繁项投影都根据F-list顺序被添加到投影中的下一个频繁项的队列中。因为ac-队列中所有的频繁项投影都包含项d,所以它们都会被插入到ad-队列中,如图4所示。
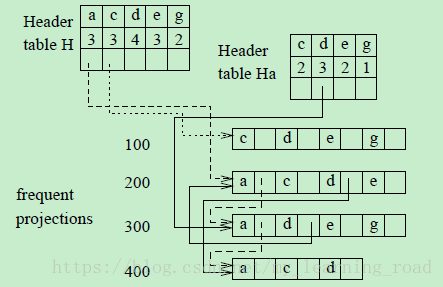
图4 Header table Ha和ad-队列
可以看到,经过调整,ad-队列集合了包含a和d的完整的频繁项投影集。因此,包含a和d的频繁模式可以被递归地挖掘出来。(注意,虽然c仍然出现在ad-projected database中,但是不会在任何递归投影数据库中把它视为目前的频繁项,因为它已经在aq-队列中了。)显然,这次挖掘得到了一个频繁模式ade:2。其实,在第三阶段header table Had也可以用Hac,因为对于Hac的搜索在前一轮已经完成了。所以在第三阶段只需要一个header table即可。
(4)对于搜索ae-projected database,因为e没有包括任何指针,所以没有任何模式产生。
所有包含a的频繁模式找到之后,a-projected database也就是a-queue在接下来的挖掘就不再需要了。
接下来要挖掘所有包含c但是不包含a的频繁模式和其他的频繁模式的子集。对于挖掘所有包含c但是不包含a的频繁模式,因为c-队列需要包含除了既包含a又包含c的所有的包含c的频繁项投影,需要将a-队列中的所有投影插入到适当的队列中。
再遍历一次a-队列,队列中的每个频繁项投影都被追加到F-list中a的下一个投影的队列中,如图5所示。例如,频繁项投影acde被插入到c-队列中,adeg被插入到d队列中。
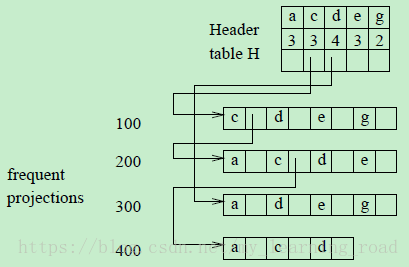
图5 挖掘a-projected database之后对hyper-links的调整
通过递归地挖掘c-projected database (在每个级别上共享头表),可以找到包含项目c但没有a的频繁模式集。注意,项a不会出现在c-projected databse中,因为之前已经找到了“a”的所有频繁模式。其他的频繁模式按照如上面同样的方法挖掘即可,在此不再赘述。很容易看出,上面的挖掘过程发现了完整的频繁模式,而且没有重复。
H-mine 算法流程(如图6所示)
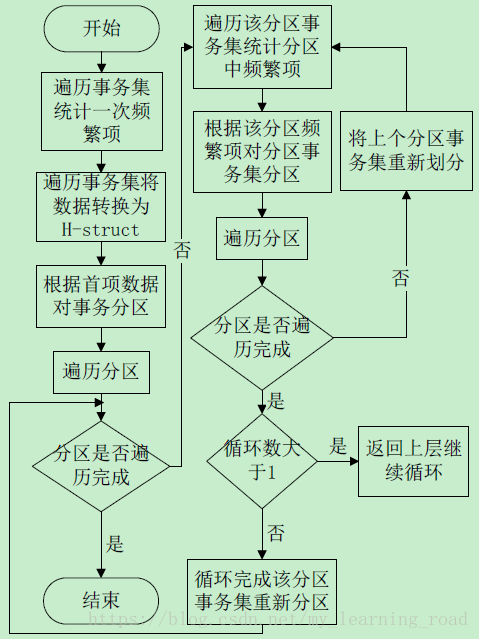
图6 H-mine 算法流程
参考资料:
《H-Mine: Hyper-Structure Mining of Frequent Patterns in Large Databases》
《基于MapReduce 的H-mine 算法》
转载地址:https://xinzhe.blog.csdn.net/article/details/86632802 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
