本文共 2386 字,大约阅读时间需要 7 分钟。
微信公众号:云计算通俗讲义
持续输出技术干货,欢迎关注!
通过本文你将了解:
- 布隆过滤器存在的背景
- 布隆过滤器概述
- 布隆过滤器实现原理
- 布隆过滤器参数计算
- 布隆过滤器优缺点
- 布隆过滤器应用场景
01 背景
假如需要过滤某些不安全网页,现有100亿个黑名单页面,每个网页的URL最多占用64字节。现要设计一种网页过滤系统,可以根据网页的URL判断该网页是否在黑名单上,要求该系统允许有万分之一以下的判断错误率,并且使用的额外空间不要超过30G。
可以采用如下几种方案:
1、将访问过的URL保存到数据库
每次需要过滤网页就需要启用一个数据库select查询,且当数据量变得非常庞大后,关系型数据库查询的效率会变得很低。
2、用HashSet将访问过的URL保存起来
那只需接近O(1)的代价就可以查到一个URL是否被访问过了。但是内存消耗太大。
3、URL经过MD5或SHA-1等单向哈希后再保存到HashSet或数据库
字符串经过MD5散列处理后的信息摘要长度只有128Bit,SHA-1处理后也只有160Bit,因此方法3比方法2节省了好几倍的内存。
4、BitMap方法
建立一个BitSet,将每个URL经过一个哈希函数映射到某一位。消耗内存是相对较少的,但缺点是单一哈希函数发生冲突的概率太高。
02 概述
Bloom Filter(布隆过滤器)是一种多哈希函数映射的快速查找算法。它是一种空间高效的概率型数据结构,通常应用在一些需要快速判断某个元素是否属于集合,但是并不严格要求100%正确的场合。
布隆过滤器的优势在于,利用很少的空间可以做到精确率较高。
哈希表与布隆过滤器:
哈希表也能用于判断元素是否在集合中,但是Bloom Filter只需要哈希表的1/8或1/4的空间复杂度就能完成同样的问题。Bloom Filter可以插入元素,但是不可以删除已有元素。集合中的元素越多,误报率越大,但是不会漏报。
03 原理
如果想判断一个元素是不是在一个集合中,一般想到的方法是暂存数据,然后查找判定是否存在集合中。这种方法在数据量比较小的情况下适用,但是几个中元素较多的时候,检索速度就会越来越慢。
可以利用Bitmap:只要检查对应点是不是1就可以知道集合中有没有这个数。Bloom filter可以看做是对bitmap的扩展。只是使用多个hash映射函数,从而减低hash发生冲突的概率。
算法如下:
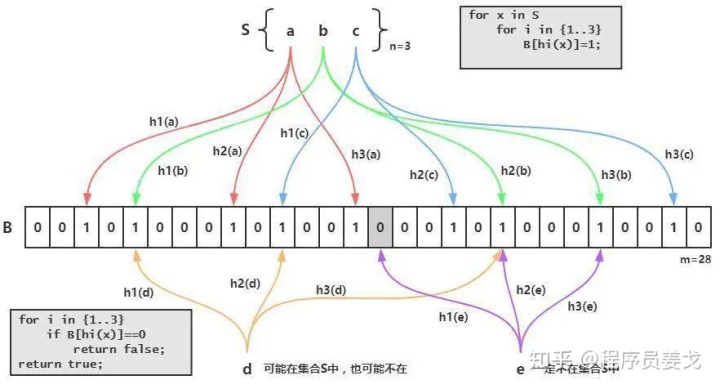
1、创建m(m=28)位的bitset,初始化为0,选中k(k=3)个不同的哈希函数;
2、第 i 个hash函数对字符串str哈希的结果记为 h(i,str),范围是(0,m-1);
3、将字符串记录到bitset的过程(即插入):对于一个字符串str,分别记录h(1,str),h(2,str)...,h(k,str),然后将bitset的h(1,str),h(2,str)...,h(k,str)位置1,也就是将一个a映射到bitset的k个二进制位;
4、检查字符串是否存在(即查找):对于字符串astr,分别计算h(1,str)、h(2,str),...,h(k,str),然后检查bitset的第h(1,str),h(2,str),...,h(k,str) 位是否为1:
若其中任何一位不为1则可以判定str一定没有被记录过;
若全部位都是1,则“认为”字符串str存在;
但是若一个字符串对应的Bit全为1,实际上是不能100%的肯定该字符串被Bloom Filter记录过的(因为有可能该字符串的所有位都刚好是被其他字符串所对应)这种将该字符串划分错的情况,称为false positive ;
5、删除字符串(删除):字符串加入了就被不能删除了,因为删除会影响到其他字符串。
Bloom Filter使用了k个哈希函数,每个字符串跟k个bit对应。从而降低了冲突的概率。
04 参数估算
4.1 最优哈希函数个数
哈希函数的选择对性能的影响应该是很大的,一个好的哈希函数要能近似等概率的将字符串映射到各个Bit。选择k个不同的哈希函数比较麻烦,一种简单的方法是选择一个哈希函数,然后送入k个不同的参数。
在样本数量为n时,那这里的k应该取多少呢?位数组m大小应该取多少呢?这里有个计算公式:
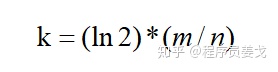
当满足这个条件时,错误率最小。
4.2 bitarray大小
布隆过滤器的bitarray大小如何确定?
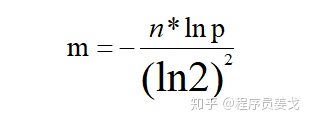
其中,大小为m,样本数量为n,失误率为p。
假设n=100亿,p=0.01%,根据上述公式,求得m=19.19n,向上取整(肯定是向上取整,不然剩下的一个元素没有地方放了)为20n。
4.3 真实误差率估计
根据前面公式:
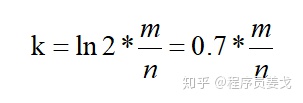
当bitarray大小m=20n时,哈希函数个数k=14,则利用公式:
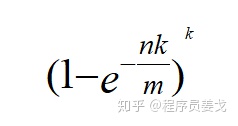
求得真实误差率为p=0.006%。
05 特点
5.1 优点
布隆过滤器相比较于传统数组、链表等数据结构,在空间和时间方面都有巨大的优势。
速度快,布隆过滤器插入/查询时间都是常数O(k)。
各个散列函数相互之间没有关系,方便由硬件并行实现。
布隆过滤器不需要存储元素本身,只是存储其存在与否的标志位,在某些对保密要求非常严格的场合有优势。
5.2 缺点
误算率是其中之一。随着存入的元素数量增加,误算率随之增加。
一般情况下不能从布隆过滤器中删除元素,如果需要删除,操作耗时且复杂。
06 应用场景
布隆过滤器的用处就是,能够在节省存储空间的情况下迅速判断一个元素是否在一个集合中。主要有如下三个使用场景:
1、网页爬虫对URL的去重,避免爬取相同的URL地址;
2、反垃圾邮件,从数十亿个垃圾邮件列表中判断某邮箱是否垃圾邮箱;
3、缓存击穿,将已存在的缓存放到布隆过滤器中,当黑客访问不存在的缓存时迅速返回避免缓存及DB挂掉。
转载地址:https://blog.csdn.net/weixin_40006779/article/details/110666791 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
