本文共 2279 字,大约阅读时间需要 7 分钟。
《大数据和人工智能交流》头条号向广大初学者新增C 、Java 、Python 、Scala、javascript 等目前流行的计算机、大数据编程语言,希望大家以后关注本头条号更多的内容。
1、本文目的
(1)、熟悉SparkStream流处理的编程
(2)、了解SparkStream和kafka联合工作过程
2、环境准备
(1)、Linux操作系统
(2)、安装64位jdk8
(3)、Spark的Local模式或者其它分布式环境
(4)、kafka集群和Zookeeper集群(可以是内置的)
(6)、scala的IDE环境
3、有关Kafka的准备工作
首先确保kafka集群已经安装,相关环境变量已经配置,然后输入下列指令建立个topic:
kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic kafka_streaming

如上图所示建立了个kafka_streaming的主题。
4、建立Scala项目
准备Scala的IDE工具Eclipse,建立demo项目并加入Spark、SparkStreaming和Kafka的jar包。
5、消费kafka的数据
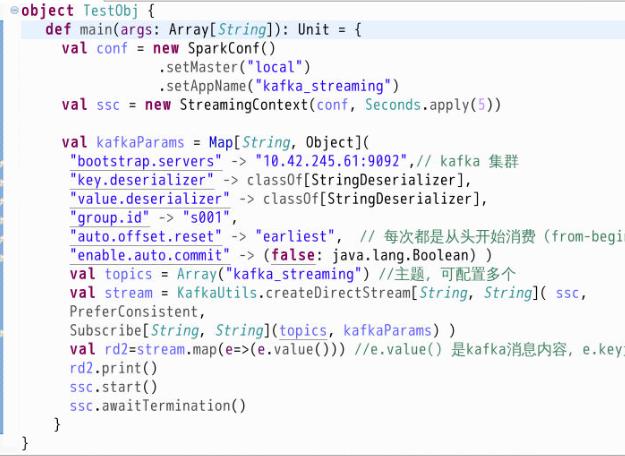
在demo项目的TestObj对象编写如下的代码:
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka010.KafkaUtils
import org.apache.spark.streaming.Seconds
import org.apache.spark.streaming.StreamingContext
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
object Spark_Stream004 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster("local")
.setAppName("kafka_streaming")
val ssc = new StreamingContext(conf, Seconds.apply(5))
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "10.42.245.61:9092",// kafka 集群
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "s001",
// 每次都是从头开始消费(from-beginning),可配置其他消费方式
"auto.offset.reset" -> "earliest",
"enable.auto.commit" -> (false: java.lang.Boolean) )
val topics = Array("kafka_streaming") //之前的主题
val stream = KafkaUtils.createDirectStream[String, String]( ssc,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams) )
val rd2=stream.map(e=>(e.value())) //e.value() 是kafka消息内容,e.key为空值
rd2.print()
ssc.start()
ssc.awaitTermination()
}
}
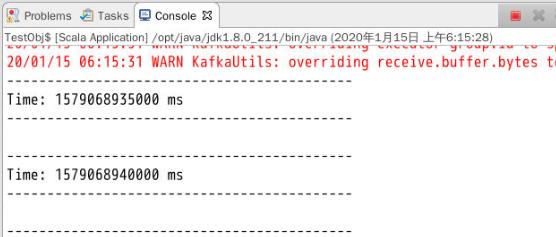
运行程序:
6、启动生产者进程
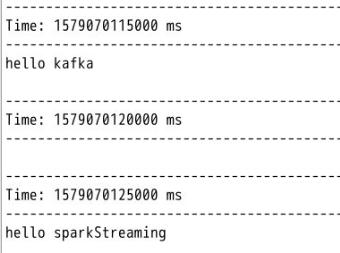
启动生产者进程,并向之前创建的名为"kafka_streaming"的topic中发送数据,命令如下:
kafka-console-producer.sh --broker-list localhost:9092 --topic kafka_streaming

这时候观察ScalaIDE的控制台"kafka_streaming"主题信息的消费情况:

《大数据和人工智能交流》的宗旨
1、将大数据和人工智能的专业数学:概率数理统计、线性代数、决策论、优化论、博弈论等数学模型变得通俗易懂。
2、将大数据和人工智能的专业涉及到的数据结构和算法:分类、聚类 、回归算法、概率等算法变得通俗易懂。
3、最新的高科技动态:数据采集方面的智能传感器技术;医疗大数据智能决策分析;物联网智慧城市等等。
根据初学者需要会有C语言、Java语言、Python语言、Scala函数式等目前主流计算机语言。
根据读者的需要有和人工智能相关的计算机科学与技术、电子技术、芯片技术等基础学科通俗易懂的文章。
转载地址:https://blog.csdn.net/weixin_39669265/article/details/110801843 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
