知识点讲解五:处理js异步加载问题

发布日期:2021-07-01 04:21:35
浏览次数:23
分类:技术文章
本文共 1283 字,大约阅读时间需要 4 分钟。
文章目录
前言
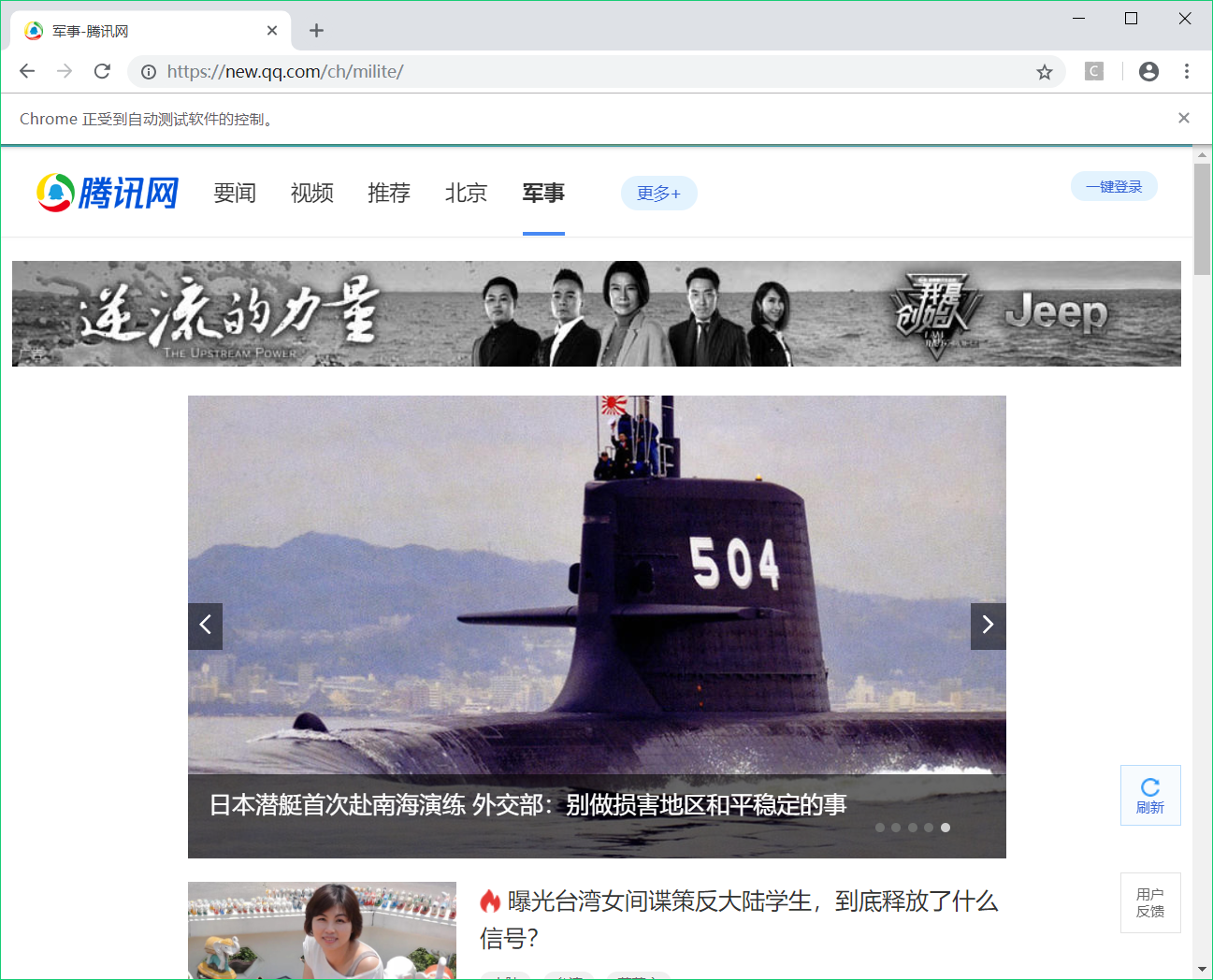
在新闻网站中大多采用的是异步加载模式,新闻条目会随滚动条的滚动而逐渐加载。当爬虫访问这类网站时得到的HTML数据仅仅是我们看到的页面数据,只有当我们向下滚动时,网页的源代码才会同步更新。例如:,处理这类JS异步加载的问题,这里用selenium来解决。
环境
- Python 3.6.5
- 需要安装的包:selenium
- 编译器:sublime text 3
代码思路
导入需要用到的Python包
import selenium,timefrom selenium import webdriver
用打开浏览器
driver = webdriver.Chrome(executable_path='chromedriver.exe')
输入我们需要爬取的网站
driver.get("https://new.qq.com/ch/milite/") 如果程序执行错误,浏览器没有打开,那么应该是没有装 Chrome 浏览器或者 Chrome 驱动没有配置在环境变量里。下载驱动,然后将驱动文件路径配置在环境变量即可。
将网页的滚动条拉到底部,触发JS加载新数据
jsCode = "var q=document.documentElement.scrollTop=100000"driver.execute_script(jsCode)
休息3秒,从JS异步加载的完成到新闻页面的更新需要一些时间
time.sleep(3)
进行标签定位,定位到class="item-pics"的标签
div = driver.find_elements_by_class_name("item-pics")for each in div: each = each.find_element_by_tag_name("a") 打印爬取到的内容
print(each.text)
原代码
#这是一个军事新闻数据采集脚本import selenium,timefrom selenium import webdriverif __name__ == '__main__': driver = webdriver.Chrome(executable_path='chromedriver.exe') driver.get("https://new.qq.com/ch/milite/") for each in range(1,10): jsCode = "var q=document.documentElement.scrollTop=100000" driver.execute_script(jsCode) time.sleep(3) print(each) time.sleep(3) div = driver.find_elements_by_class_name("item-pics") for each in div: each = each.find_element_by_tag_name("a") print(each.text) 转载地址:https://mtyjkh.blog.csdn.net/article/details/82749724 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
哈哈,博客排版真的漂亮呢~
[***.90.31.176]2024年04月19日 05时28分09秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
如何在junit中使用SpringFramework的Ioc容器
2019-04-26
一个案例教你理解Spring面向切面编程(Spring Aop)
2019-04-26
手把手教你整合SSM框架
2019-04-26
自己造个简单数据校验的注解@Value和@Mail
2019-04-26
Poj百练 4148:生理周期 (分类:枚举)
2019-04-26
Java如何读写注册表
2019-04-26
java如何利用模板文件生成word文档
2019-04-26
java读写xlsx格式的MS Excel文件
2019-04-26
vue的一些基础知识点
2019-04-26
webpack错误记录(不定期更新)
2019-04-26
Poj百练 2692:假币问题 (分类:模拟)
2019-04-26
SpringBoot实现一个文件上传服务
2019-04-26
前后分但文件上传与多文件上传,前端实现
2019-04-26
Poj百练 2711:合唱队形 (分类:动态规划)
2019-04-26
SpringBoot自定义banner
2019-04-26
JWT(JSON Web Token)认证小结
2019-04-26
Poj百练 2746:约瑟夫问题 (分类:模拟)
2019-04-26
git知识点梳理
2019-04-26
git中tag标签的用法
2019-04-26
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 306400413 位访客
访问时间: 2024-04-20 08:06:33
访问IP: 3.15.225.173
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版