本文共 2513 字,大约阅读时间需要 8 分钟。
文章目录
一、具体实现步骤
第1步:数据预处理
导入库
import pandas as pdimport numpy as np
导入数据集
dataset = pd.read_csv('50_Startups.csv')X = dataset.iloc[ : , :-1].valuesY = dataset.iloc[ : , 4 ].values 将类别数据数字化
from sklearn.preprocessing import LabelEncoder, OneHotEncoderlabelencoder = LabelEncoder()X[: , 3] = labelencoder.fit_transform(X[ : , 3])#表示对第4个特征进进行OneHot编码onehotencoder = OneHotEncoder(categorical_features = [3])X = onehotencoder.fit_transform(X).toarray()
躲避虚拟变量陷阱
X = X[: , 1:]
拆分数据集为训练集和测试集
from sklearn.model_selection import train_test_splitX_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=0)
第2步: 在训练集上训练多元线性回归模型
from sklearn.linear_model import LinearRegressionregressor = LinearRegression()regressor.fit(X_train, Y_train)
第3步:在测试集上预测结果
y_pred = regressor.predict(X_test)
二、知识点详解
1. 关于多元线性回归
简单线性回归:影响Y的因素唯一,只有一个。
多元线性回归:影响Y的因数不唯一,有多个。与一元线性回归一样,多元线性回归自然是一个回归问题。
一元线性回归方程:Y=aX+b。
多元线性回归是:Y=aX1+bX2+cX3+…+nXn。相当于我们高中学的一元一次方程,变成了n元一次方程。因为y还是那个y。只是自变量增加了。
2. 关于OneHotEncoder()编码
在实际的机器学习的应用任务中,特征有时候并不总是连续值,有可能是一些分类值,如性别可分为“male”和“female”。在机器学习任务中,对于这样的特征,通常我们需要对其进行特征数字化,如下面的例子:
有如下三个特征属性:
- 性别:[“male”,“female”]
- 地区:[“Europe”,“US”,“Asia”]
- 浏览器:[“Firefox”,“Chrome”,“Safari”,“Internet Explorer”]
通过LabelEncoder将其数字化:
- 性别:[0,1]
- 地区:[0,1,2]
- 浏览器:[0,1,2,3]
再用OneHotEncoder进行编码:
from sklearn.preprocessing import OneHotEncoderenc = OneHotEncoder()enc.fit([[0, 0, 3], [1, 1, 0], [0, 2, 1], [1, 0, 2]])"""如果不加 toarray() 的话,输出的是稀疏的存储格式,即索引加值的形式,也可以通过参数指定 sparse = False 来达到同样的效果"""ans = enc.transform([[0, 1, 3]]).toarray() print(ans) # 输出 [[ 1. 0. 0. 1. 0. 0. 0. 0. 1.]]
解释:对于输入数组,这依旧是把每一行当作一个样本,每一列当作一个特征。
- 我们先来看第一个特征,即第一列 [0,1,0,1],也就是说它有两个取值 0 或者 1,那么 one-hot 就会使用两位来表示这个特征,[1,0] 表示 0, [0,1] 表示 1,在上例输出结果中的前两位 [1,0…] 也就是表示该特征为 0。
- 第二个特征,第二列 [0,1,2,0],它有三种值,那么 one-hot 就会使用三位来表示这个特征,[1,0,0] 表示 0, [0,1,0] 表示 1,[0,0,1] 表示 2,在上例输出结果中的第三位到第六位 […0,1,0,0…] 也就是表示该特征为 1。
- 第二个特征,第三列 [3,0,1,2],它有四种值,那么 one-hot 就会使用四位来表示这个特征,[1,0,0,0] 表示 0, [0,1,0,0] 表示 1,[0,0,1,0] 表示 2,[0,0,0,1] 表示 3,在上例输出结果中的最后四位 […0,0,0,1] 也就是表示该特征为 3
可以简单理解为“male”“US”“Safari”经过LabelEncoder与OneHotEncoder的编码就变成了:[[1. 0. 0. 1. 0. 0. 0. 0. 1.]]
更多OneHot编码知识可前往:
3. 关于toarray()
toarray():将列表转化为数组
Python原生没有数组的概念,这点不同于Java之类的面向对象语言。Python中原生的列表使用起来很像数组,但是两者有本质的区别
列表与数组的最本质的区别:列表中的所有元素的内存地址可以不是连续的,而数组是连续的。
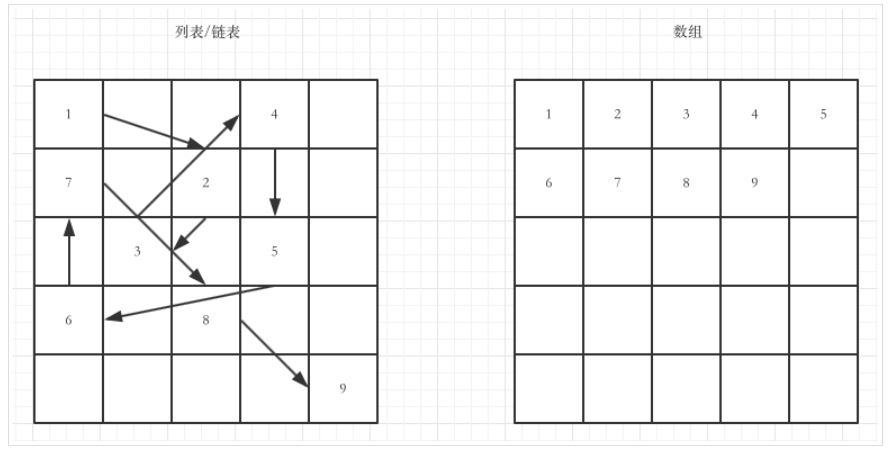
更详细的解释:
4. 虚拟变量陷阱
虚拟变量陷阱是指两个以上(包括两个)变量之间高度相关的情形。简而言之,就是存在一个能被其他变量预测出的变量,举一个存在重复类别(变量)的直观例子:假使我们舍弃男性类别,那么该类别也可以通过女性类别来定义(女性值为0时,表示男性,为1时,表示女性),反之亦然。
虚拟变量陷阱这里就简单了解,后面再深入讨论。
转载地址:https://mtyjkh.blog.csdn.net/article/details/82775192 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
