本文共 2182 字,大约阅读时间需要 7 分钟。
文章目录
一、简单线性回归(即一元线性回归)
线性回归属于监督学习,因此方法和监督学习应该是一样的,先给定一个训练集,根据这个训练集学习出一个线性函数,然后测试这个函数训练的好不好(即此函数是否足够拟合训练集数据),挑选出最好的函数(cost function最小)即可。
注意: 1.因为是线性回归,所以学习到的函数为线性函数,即直线函数; 2.因为是单变量,因此只有一个x;线性回归模型:
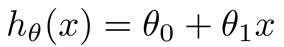
二、代价函数
看过了简单线性回归,我们肯定有一个疑问,怎么样能够看出线性函数拟合的好不好呢?
我们需要使用到Cost Function(代价函数),代价函数越小,说明线性回归地越好(和训练集拟合地越好),当然最小就是0,即完全拟合;
虽然我们现在还不知道Cost Function内部到底是什么样的,但是我们的目标是:给定输入向量x,输出向量y,theta向量,输出Cost值;

数学表达式:
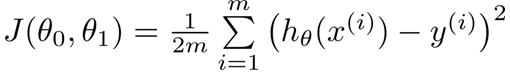
代码实现:
# 计算代价函数def computerCost(X,y,theta): m = len(y) J = 0 J = (np.transpose(X*theta-y))*(X*theta-y)/(2*m) #计算代价J return J
肯能对代价函数还是比较懵逼,那就看看具体的东西。
实例说明
比如给定数据集(1,1)、(2,2)、(3,3)则x = [1;2;3],y = [1;2;3] (此处的语法为Octave语言的语法,表示3*1的矩阵)
-
如果我们预测theta0 = 0,theta1 = 1,则h(x) = x,则cost function:
J(0,1) = 1/(2*3) * [(h(1)-1)2+(h(2)-2)2+(h(3)-3)^2] = 0; -
如果我们预测theta0 = 0,theta1 = 0.5,则h(x) = 0.5x,则cost function:
J(0,0.5) = 1/(2*3) * [(h(1)-1)2+(h(2)-2)2+(h(3)-3)^2] = 0.58;
theta0,theta1分别代表数学表达式中的 θ 0 \theta_{0} θ0和 θ 1 \theta_{1} θ1
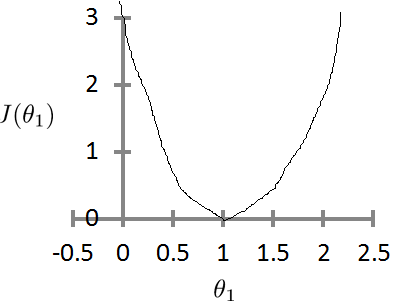
如果theta0 一直为 0, 则theta1与J的函数为:
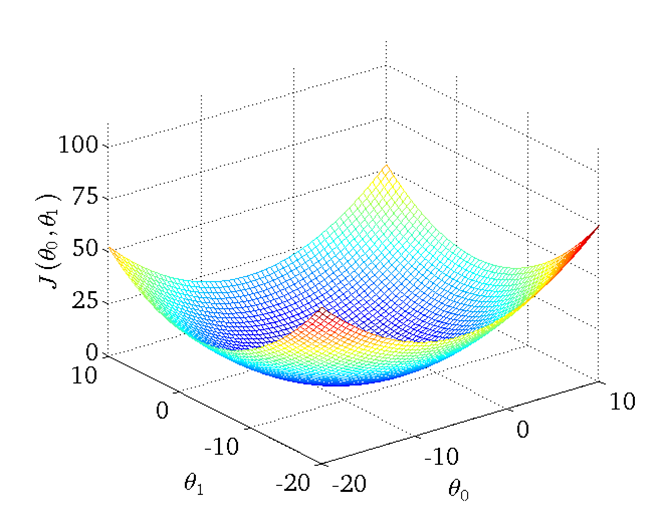
如果有theta0与theta1都不固定,则theta0、theta1、J 的函数为:
当然我们也能够用二维的图来表示,即等高线图:
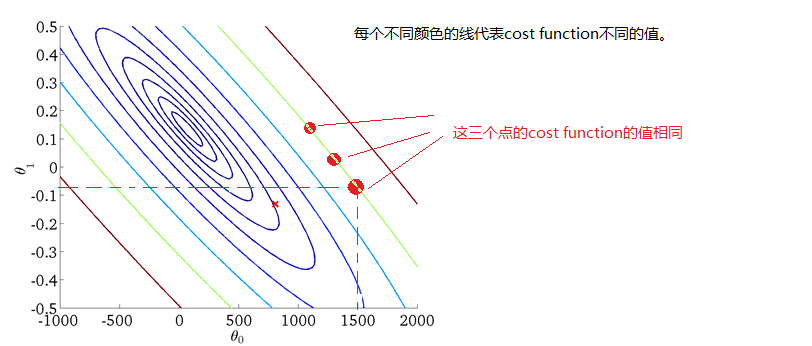
注意:如果是线性回归,则costfunctionJ与的函数一定是碗状的,即只有一个最小点。
三、梯度下降
在知道了如何看出线性函数拟合好不与好后,又生出了一个问题,我们如何调整函数的参数使拟合程度达到最佳呢?
人工手动调试是肯定不行的太耗时间,而且结果不一定让我们满意。这时就需要引入梯度下降的概念找出cost function函数的最小值。
梯度下降原理:将函数比作一座山,我们站在某个山坡上,往四周看,从哪个方向向下走一小步,能够下降的最快。
数学表达式:
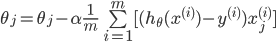
- 其中 α \alpha α为学习速率,控制梯度下降的速度,一般取0.01,0.03,0.1,0.3…
- m为Y的长度,即训练集中元素的个数
- θ j \theta_{j} θj为代价函数
具体方法
(1)先确定向下一步的步伐大小,我们称为Learning rate(即 α \alpha α)。
(2)任意给定一个初始值。 (3)确定一个向下的方向,并向下走预先规定的步伐,并更新。 (4)当下降的高度小于某个定义的值,则停止下降。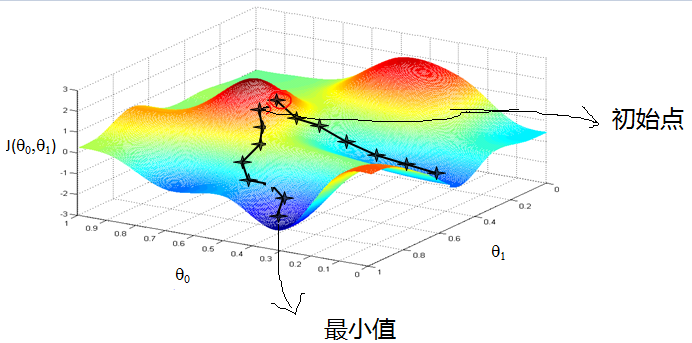
初始点不同,获得的最小值也不同,因此梯度下降求得的只是局部最小值。
代码实现:
# 梯度下降算法def gradientDescent(X,y,theta,alpha,num_iters): m = len(y) n = len(theta) temp = np.matrix(np.zeros((n,num_iters))) # 暂存每次迭代计算的theta,转化为矩阵形式 J_history = np.zeros((num_iters,1)) #记录每次迭代计算的代价值 for i in range(num_iters): # 遍历迭代次数 h = np.dot(X,theta) # 计算内积,matrix可以直接乘 temp[:,i] = theta - ((alpha/m)*(np.dot(np.transpose(X),h-y))) #梯度的计算 theta = temp[:,i] J_history[i] = computerCost(X,y,theta) #调用计算代价函数 print(".") return theta,J_history 刚开始不宜研究过深,后期再对线性回归内容进行补充。
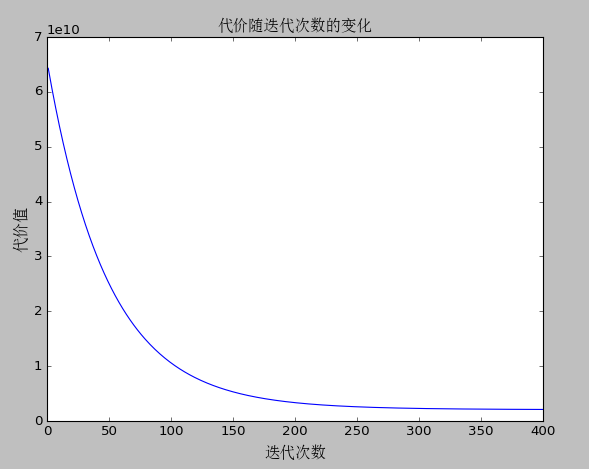
代价随迭代次数的变化
在梯度下降的过程中代价会随迭代次数的增加而减少,但并不是迭代次数越多越好,当迭代次数达到一定值后,代价值几乎不会有变化。
参考文章:,我精减了他这篇博客的内容,并加入python的代码实现。
转载地址:https://mtyjkh.blog.csdn.net/article/details/82794967 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
