本文共 10059 字,大约阅读时间需要 33 分钟。
微信公众号: 【明天依旧可好】
最新更新时间: 2021-4-12注:关于pandas的相关问题,若本文未涉及可在下方留言告诉我,我会在文章中进行补充的
Ctrl+F 可进行全文查找
原文链接:,欢迎转载
文章目录
0 安装
pip方式
pip install pandas
Anaconda
conda install pandas
1 文件
1.1 文件读写模式
以CSV文件的读取为例,代码如下
import pandas as pd#设置只读模式file_path = os.path.join("test.csv")data = pd.read_csv(open(file_path,'r',encoding='utf-8'),sep='|') | mode | 描述 |
|---|---|
| “r” | 打开,只读。文件的指针将会放在文件的开头。这是默认模式; |
| “w” | 打开,只写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件; |
| “a” | 打开,指向文件尾,在已存在文件中追加; |
| “rb” | 打开一个二进制文件,只读; |
| “wb” | 打开一个二进制文件,只写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件; |
| “ab” | 打开一个二进制文件,进行追加 ; |
| “r+” | 以读/写方式打开一个已存在的文件; |
| “w+” | 以读/写方式建立一个新的文本文件。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件 ; |
| “a+” | 以读/写方式打开一个文件文件进行追加 ; |
| “rb+” | 以读/写方式打开一个二进制文件; |
| “wb+” | 以读/写方式建立一个新的二进制文件。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件 |
| “ab+” | 以读/写方式打开一个二进制文件进行追加 ; |
1.2 读取CSV文件
import pandas as pdimport osfile_path = os.path.join("test.csv")#读取test.csv文件中的A、B列,若不设置usecols参数,默认读取全部数据。data = pd.read_csv(open(file_path,'r',encoding='utf-8'),sep='|',usecols=["A","B"]) 1.3 读取excel文件
excel文件的读取都可以用以下函数来实现
pd.read_excel(io, sheetname=0,header=0,skiprows=None,index_col=None,names=None, arse_cols=None,date_parser=None,na_values=None,thousands=None, convert_float=True,has_index_names=None,converters=None,dtype=None, true_values=None,false_values=None,engine=None,squeeze=False,**kwds)
参数详解:
io:excel文件路径;sheetname:默认是sheetname为0,返回多表使用sheetname=[0,1],若sheetname=None是返回全表 。注意:int/string返回的是dataframe,而none和list返回的是dict of dataframe。header:指定作为列名的行,默认0,即取第一行,数据为列名行以下的数据;若数据不含列名,则设定 header = None;skiprows:省略指定行数的数据,比如省略第三行,skiprows=2;skip_footer:省略从尾部数的行数据index_col:指定列为索引列;names:指定列的名字,传入一个list数据
1.4 读取txt文件
这里使用read_table()函数。
import pandas as pddata=pd.read_table('../data/datingTestSet2.txt',sep='\t',header=None)data.head()"""输出:0 1 2 30 40920 8.326976 0.953952 31 14488 7.153469 1.673904 22 26052 1.441871 0.805124 13 75136 13.147394 0.428964 14 38344 1.669788 0.134296 1""" 函数原型:
pandas.read_table(filepath_or_buffer,sep='\t',delimiter=None, header='infer',names=None,index_col=None,usecols=None,squeeze=False, prefix=None,mangle_dupe_cols=True,dtype=None,engine=None,converters=None, true_values=None,false_values=None,skipinitialspace=False,skiprows=None, nrows=None,na_values=None,keep_default_na=True,na_filter=True,verbose=False, skip_blank_lines=True,parse_dates=False,infer_datetime_format=False, keep_date_col=False,date_parser=None,dayfirst=False,iterator=False, chunksize=None,compression='infer',thousands=None,decimal=b'.',lineterminator=None, quotechar='"',quoting=0,escapechar=None,comment=None,encoding=None,dialect=None, tupleize_cols=None,error_bad_lines=True,warn_bad_lines=True,skipfooter=0, doublequote=True,delim_whitespace=False,low_memory=True,memory_map=False, float_precision=None)
常用参数简介:
filepath_or_buffer:文件路径。sep:分隔符,默认为\t。header:用作列名的行号,默认为0(第一行),如果没有header行就应该设置为None。names:用于结果的列名列表,结合header=None。skiprows:跳过指定行。na_values:缺失值处理,na_values= ["null"],用null字符替换缺失值。nrows:定需要读取的行数:nrows = 100, 指定读取前100行数据。
1.5 读取JSON文件
import pandas as pddf = pd.read_json('frame.json') 1.6 写入CSV文件
#任意的多组列表a = [1,2,3]b = [4,5,6]#字典中的key值即为csv中的列名data_dict = { 'a_name':a,'b_name':b}#设置DataFrame中列的排列顺序#如果无需重命名,columns这一参数可以省略dataFrame = pd.DataFrame(data_dict, columns=['a_name', 'b_name'])#将DataFrame存储到csv文件中,index表示是否显示行名,default=TruedataFrame.to_csv("test.csv", index=False, sep='|')#如果希望在不覆盖原文件内容的情况下将信息写入文件,可以加上mode="a"dataFrame.to_csv("test.csv", mode="a", index=False,sep='|') 1.7 写入JSON文件
import pandas as pdimport numpy as npdf = pd.DataFrame(np.arange(16).reshape(4, 4), index=['onw', 'two', 'three', 'four'], columns=['A', 'B', 'C', 'D'])df.to_json('df.json') 2 DataFrame
2.1 获取列名
DataFrame.columns.values.tolist()
2.2 遍历
遍历DataFrame数据。
for index, row in df.iterrows(): print(row["column"])
2.3 合并(concat方法)
谈到DataFrame数据的合并,一般用到的方法有concat、join、merge。
这里就介绍concat方法,以下是函数原型。pd.concat(objs, axis=0, join=‘outer’, join_axes=None, ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False)
参数说明 :
objs: series,dataFrame或者是panel构成的序列list。 axis: 需要合并链接的轴,0是行,1是列。 join: 连接的方式 inner,或者outer。2.3.1 相同字段的表首尾相接
# 现将表构成list,然后在作为concat的输入frames = [df1, df2, df3]result = pd.concat(frames)#重置索引(index),不然后面容易出问题,我曾经因为这个找了一个上午的bug。df = result.reset_index(drop=True)
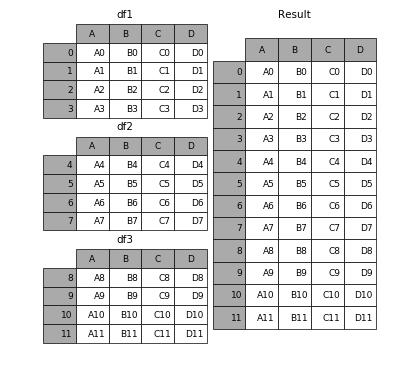
2.3.2 横向表拼接(行对齐)
特别注意: axis=1时,concat()的拼接是根据df.index来的,index相同的的行进行拼接。
2.3.2.1 axis参数说明
当axis = 1的时候,concat就是行对齐,然后将不同列名称的两张表合并。
result = pd.concat([df1, df4], axis=1)
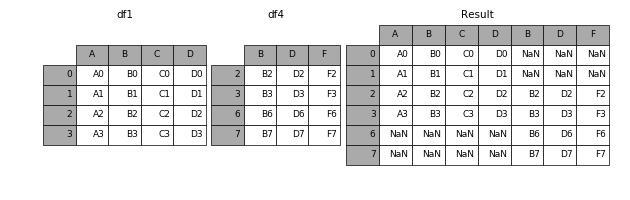
2.3.2.2 join参数说明
加上join参数的属性,如果为inner得到的是两表的交集,如果是outer,得到的是两表的并集。
result = pd.concat([df1, df4], axis=1, join='inner')
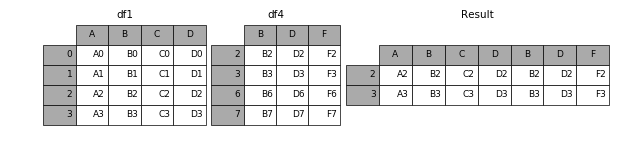
2.3.2.3 join_axes参数说明
如果有join_axes的参数传入,可以指定根据那个轴来对齐数据
例如根据df1表对齐数据,就会保留指定的df1表的轴,然后将df4的表与之拼接result = pd.concat([df1, df4], axis=1, join_axes=[df1.index])
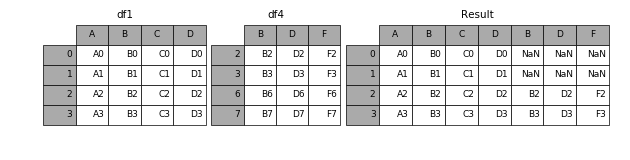
2.4 将df按照某个字段进行拆分求和(groupby()函数)

dataset_new_2 = dataset_new.groupby(by='Datetime')['AEP_MW'].sum()# 此时得到的dataset_new_2数据类型为Series,可以通过下面代码转化为DataFramedict_dataset = { 'Datetime':dataset_new_2.index,'AEP_MW':dataset_new_2.values}dataset_new_3 = pd.DataFrame(dict_dataset)dataset_new_3.head() 2004/10/1的AEP_MW为所有值的和

3 行列
3.1 查找
查找DataFrame数据类型中的某一(多)行(列)
这里记录三个可以实现该功能的函数:loc、iloc、ix。
- loc:通过标签选取数据,即通过index和columns的值进行选取。loc方法有两个参数,按顺序控制行列选取。
- iloc:通过行号选取数据,即通过数据所在的自然行列数为选取数据。iloc方法也有两个参数,按顺序控制行列选取。
- ix:混合索引,同时通过标签和行号选取数据。ix方法也有两个参数,按顺序控制行列选取。
代码示例如下:
#df数据 a b cd 0 1 2e 3 4 5f 6 7 8g 9 10 11
3.1.1 loc(按行\列标签进行查找)
通过标签选取数据,即通过index和columns的值进行选取。loc方法有两个参数,按顺序控制行列选取。
#1.定位单行df.loc['e'] #df数据参考上文'''a 3b 4c 5Name: e, dtype: int32==================================='''#2.定位单列df.loc[:,'a']'''d 0e 3f 6g 9Name: a, dtype: int32==================================='''#3.定位多行#方法一:df.loc['e':]''' a b ce 3 4 5f 6 7 8g 9 10 11==================================='''#方法二df.loc[['e','f','g']]''' a b ce 3 4 5f 6 7 8g 9 10 11==================================='''#4.定位多行多列#方法一:df.loc['e':,:'b']''' a be 3 4f 6 7g 9 10==================================='''#方法二:df.loc['e':,['a','b']]''' a be 3 4f 6 7g 9 10==================================='''
3.1.2 iloc(按行\列号进行查找)
通过行号选取数据,即通过数据所在的自然行列数为选取数据。iloc方法也有两个参数,按顺序控制行列选取。
#1.定位单行df.iloc[1] #df数据参考上文'''a 3b 4c 5Name: e, dtype: int32==================================='''#2.定位单列df.iloc[:,1]'''d 1e 4f 7g 10Name: b, dtype: int32==================================='''#3.定位多行df.iloc[1:3] #或者df.iloc[[1,2,3]]''' a b ce 3 4 5f 6 7 8==================================='''#4.定义多行多列df.iloc[1:3,1:2]#或者df.iloc[1:3,[1,2]]''' be 4f 7==================================='''
3.1.3 查找含有特定值的行
import pandas as pdimport numpy as np a=np.array([[1,2,3],[4,5,6],[7,8,9]])df=pd.DataFrame(a,index=['row0','row1','row2'],columns=list('ABC'))print(df)#选取A为4的行df=df[df['A'].isin([4])]print(df)"""输出 A B Crow0 1 2 3row1 4 5 6row2 7 8 9 A B Crow1 4 5 6""" 3.2 删除
删除DataFrame中某一行
df.drop([16,17])
3.2.1删除特定数值的行
import pandas as pdimport numpy as np a=np.array([[1,2,3],[4,5,6],[7,8,9]])df=pd.DataFrame(a,index=['row0','row1','row2'],columns=list('ABC'))print(df)#通过~取反,选取不包含数字4的行df=df[~df['A'].isin([4])]print(df)"""输出 A B Crow0 1 2 3row1 4 5 6row2 7 8 9 A B Crow0 1 2 3row2 7 8 9""" 3.3 修改
3.3.1 修改列名
df.columns = ['A','B','C']
3.4 排序
df.sort_values(by="sales" , ascending=False)
函数原型:
DataFrame.sort_values(by, axis=0, ascending=True, inplace=False, kind=‘quicksort’, na_position=‘last’)
列举常用的参数用法:
- by:函数的操作对象是DataFrame
- axis:进行操作的列名,多个列名用列表表示
- ascending:默认为升序True
#dataFrame:''' col1 col2 col30 A 2 01 A 1 12 B 9 93 NaN 8 44 D 7 25 C 4 3'''df = df.sort_values(by=['col1'])'''输出: col1 col2 col30 A 2 01 A 1 12 B 9 95 C 4 34 D 7 23 NaN 8 4'''
3.5 转置(行列转换)
将dataFrame原先的行变成列,将原先的列变为行
df = df.T
4 索引
-
reindex()
更新index或者columns, 默认:更新index,返回一个新的DataFrame -
set_index()
将DataFrame中的列columns设置成索引index 打造层次化索引的方法 -
reset_index()
将使用set_index()打造的层次化逆向操作 既是取消层次化索引,将索引变回列,并补上最常规的数字索引
详细讲解:
4.1 更新
reindex():更新index或者columns。
默认:更新index,返回一个新的DataFrame。# 返回一个新的DataFrame,更新index,原来的index会被替代消失# 如果dataframe中某个索引值不存在,会自动补上NaNdf2 = df1.reindex(['a','b','c','d','e'])# fill_valuse为原先不存在的索引补上默认值,不再是NaNdf2 = df1.reindex(['a','b','c','d','e'], fill_value=0)# inplace=Ture,在DataFrame上修改数据,而不是返回一个新的DataFramedf1.reindex(['a','b','c','d','e'], inplace=Ture)# reindex不仅可以修改 索引(行),也可以修改列states = ["columns_a","columns_b","columns_c"]df2 = df1.reindex( columns=states )
4.2 设置
set_index():将DataFrame中的列columns设置成索引index。
打造层次化索引的方法。# 将columns中的其中两列:race和sex的值设置索引,race为一级,sex为二级# inplace=True 在原数据集上修改的adult.set_index(['race','sex'], inplace = True) # 默认情况下,设置成索引的列会从DataFrame中移除# drop=False将其保留下来adult.set_index(['race','sex'], drop=False)
4.3 重置
reset_index():将使用set_index()打造的层次化逆向操作。
既是取消层次化索引,将索引变回列,并补上最常规的数字索引。df.reset_index()
5 重复项
5.1 查看是否存在重复项
DataFrame的duplicated方法返回一个布尔型Series,表示各行是否重复行。
a = df.duplicated()
5.2 删除
而 drop_duplicates方法,它用于返回一个移除了重复行的DataFrame
#去掉A_ID和B_ID重复的行,并保留第一次出现的行df = df.drop_duplicates(subset=['A_ID', 'B_ID'], keep='first')
- 当keep=False时,就是去掉所有的重复行
- 当keep='first’时,就是保留第一次出现的重复行
- 当keep='last’时就是保留最后一次出现的重复行。
6 元素
6.1 查找
通过标签或行号获取某个数值的具体位置(DataFrame数据类型中)
#DataFrame数据 a b cd 0 1 2e 3 4 5f 6 7 8g 9 10 11#获取第2行,第3列位置的数据df.iat[1,2]Out[205]: 5#获取f行,a列位置的数据df.at['f','a']Out[206]: 6'''iat:依据行号定位at:依旧标签定位'''
6.2 修改
修改DataFrame中的某一元素
df['列名'][行序号(index)] = "新数据"
7 处理缺损数据
7.1 dropna()方法
该方法用于检查是否存在缺损数据,若存在则删除相关列与行。
函数原型:pd.dropna(axis=0, how=‘any’, thresh=None, subset=None, inplace=False)
参数说明:
axis: 该参数确定是删除包含缺失值的行或列,axis=0或axis='index’删除含有缺失值的行,axis=1或axis='columns’删除含有缺失值的列。how:any存在即nan即丢弃,all全部为nan才丢弃。thresh:默认值 None值,thresh=n则表明每行至少n的非NaN值,否则则删除该行。subset:定义要在哪些列中查找缺失值。inplace:默认值 False,是否直接在原DataFrame进行修改。
8 实现数据分组求平均值
#求type1Name下属所有类别名type1Name = df.type1Name.unique()#输出每个类别A值的平均值for type1 in type1Name: t = df.type1Name.A == type1 print(df[t].mean())
转载地址:https://mtyjkh.blog.csdn.net/article/details/84752080 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
