本文共 3407 字,大约阅读时间需要 11 分钟。
在自然语言学习的很长一段时间内自己对正则的把握都是需要什么学什么,后来发现特烦索性今天就把正则表达式的内容系统的整理归纳一下。简单的我就不啰嗦了,直接上干货!
正则表达式(regular expression) 是可以匹配文本片段的模式。最简单的正则表达式就是普通字符串,可以匹配其自身,例如表达式“this”匹配字符串“this”。更多的则是通过元字符来编写正则表达式的匹配规则,例如通过表达式“\d”来匹配阿拉伯数字,通过“[\u4e00-\u9fa5]”来匹配中文。
想了许久还是决定加入一段介绍性的文字,你可以把正则表达式理解为一种“代号”,你去公司面试的时候,面试官叫到下一个面试者请进来,那你就知道他口中的面试者就是来求取工作的人。同理如果你在代码中用到“\d”系统就是知道你指的是阿拉伯数字。至于编译器系统是如何识别这些“代号”(也就是正则表达式),这就是我们下面列举的那些函数的事情了,python处理正则表达式的函数封装在re库中。至于re你可以不用去过多了解导入即可,花最少的时间学习最用的东西。
文章目录
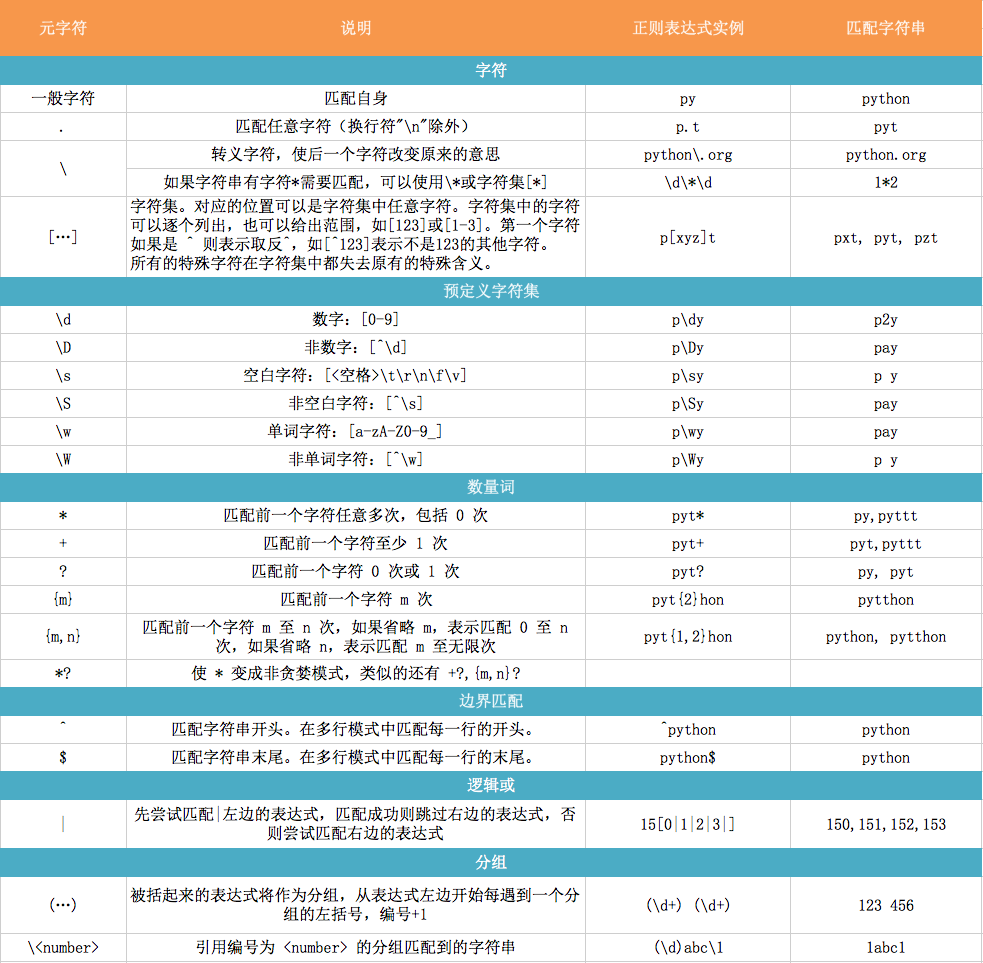
0. 元字符
正则表达式是由普通字符(例如字符 a 到 z)以及特殊字符(称为"元字符")组成的文字模式。模式描述在搜索文本时要匹配的一个或多个字符串。正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。
 图片来源于网络,侵删
图片来源于网络,侵删 1. 函数
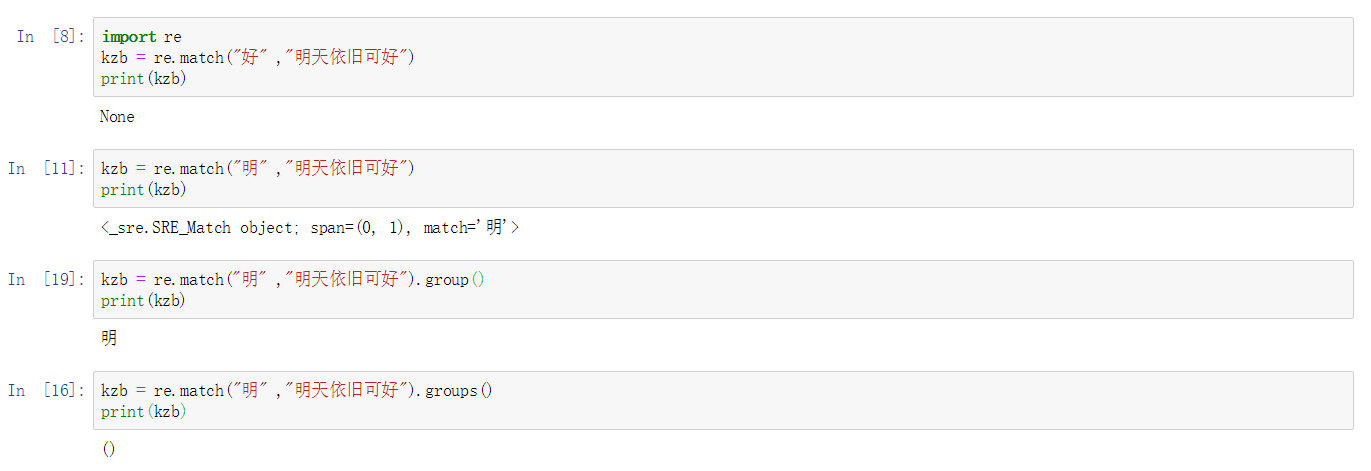
1.1. match()函数
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。Python 自1.5版本起增加了re 模块,re 模块使 Python 语言拥有全部的正则表达式功能。
函数语法
re.match(pattern, string, flags=0)
函数参数说明
| 参数 | 说明 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。(更多见底部注释1) |
实例
1.2. search()函数
re.search 扫描整个字符串并返回第一个成功的匹配。
函数语法
re.search(pattern, string, flags=0)
参数说明
| 参数 | 说明 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。(更多见底部注释1) |
实例

1.3. findall()函数
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。注意:match 和 search 是匹配一次,findall 匹配所有。
函数语法
findall(string[, pos[, endpos]])
参数说明
| 参数 | 说明 |
|---|---|
| string | 待匹配的字符串。 |
| pos | 可选参数,指定字符串的起始位置,默认为 0。 |
| endpos | 可选参数,指定字符串的结束位置,默认为字符串的长度。 |
实例

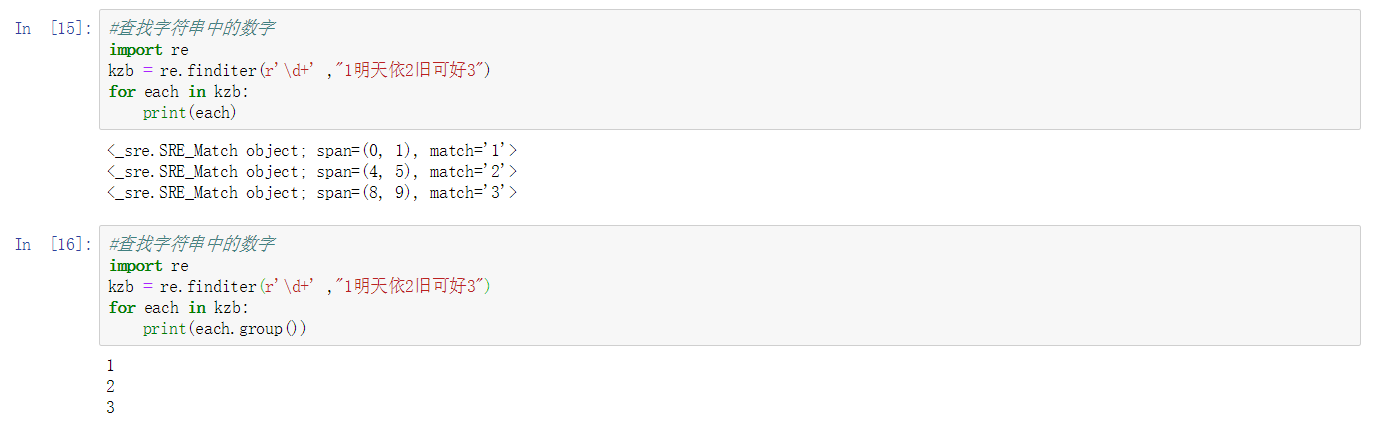
1.4. finditer()函数
finditer方法的行为跟 findall 的行为类似,也是搜索整个字符串,获得所有匹配的结果。但它返回一个顺序访问每一个匹配结果(Match 对象)的迭代器。
函数语法
re.finditer(pattern, string, flags=0)
参数说明
| 参数 | 说明 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。(更多见底部注释1) |
实例
1.5. split()函数
函数语法
re.split(pattern, string[, maxsplit=0, flags=0])
参数说明
| 参数 | 说明 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| maxsplit | 分隔次数,maxsplit=1 分隔一次,默认为 0,不限制次数。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。(更多见底部注释1) |
实例

1.6. sub()函数
sub 方法用于替换。
函数语法
re.sub(pattern, repl, string, count=0, flags=0)
参数说明
| 参数 | 说明 |
|---|---|
| pattern | 正则中的模式字符串。 |
| repl | 替换的字符串,也可为一个函数。 |
| string | 要被查找替换的原始字符串。 |
| count | 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。(更多见底部注释1) |
实例

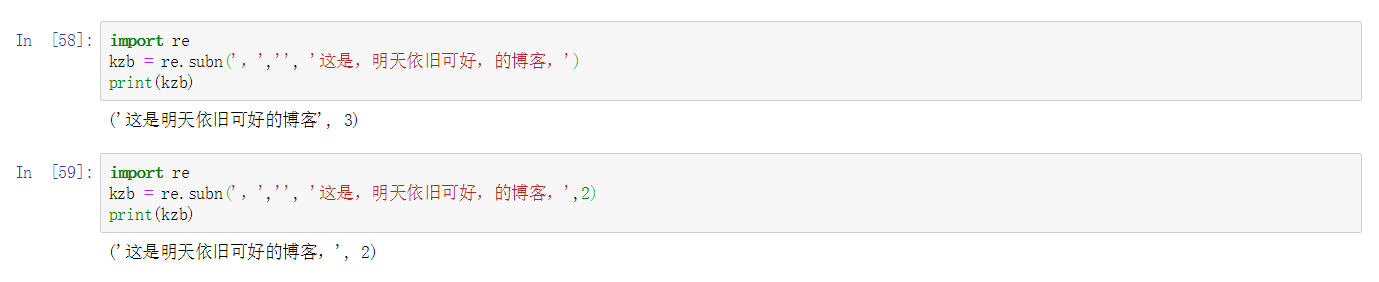
1.7. subn()函数
subn()方法跟 sub 方法的行为类似,也用于替换。它返回一个元组,元组有两个元素,第一个元素是使用 sub 方法的结果,第二个元素返回原字符串被替换的次数。
函数语法
subn(pattern, repl, string, count=0, flags=0)
参数说明
| 参数 | 说明 |
|---|---|
| pattern | 正则中的模式字符串。 |
| repl | 替换的字符串,也可为一个函数。 |
| string | 要被查找替换的原始字符串。 |
| count | 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。(更多见底部注释1) |
实例
2. 其他函数
2.1. group()与groups()函数
用group(num=0) 或 groups() 匹配对象函数来获取匹配成功项。
函数参数说明:
| 参数 | 说明 |
|---|---|
| group(num=0) | 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。 |
| groups() | 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。(注意:是从1开始而不是0) |
实例
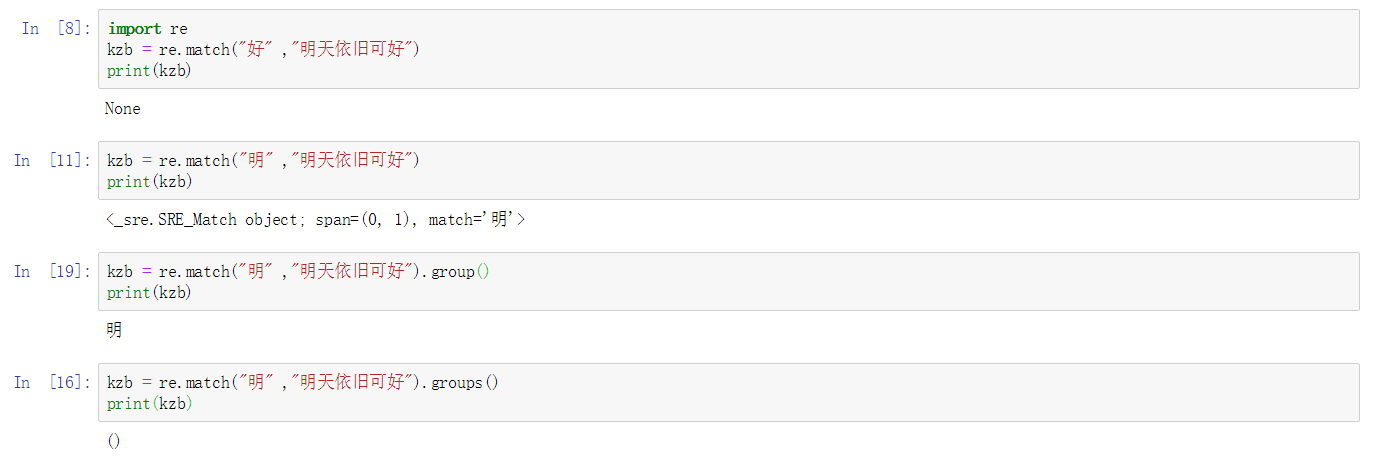
2.2. start()函数
返回匹配开始的位置
实例

2.3. end()函数
返回匹配结束的位置
实例

2.4. span()
返回一个元组包含匹配 (开始,结束) 的位置
实例

3. 实例
3.1. 判断字符串是否全为中文
在这里我采用的是逆向思维,匹配非中文字符,如果未匹配成功则说明该字符串全为中文。
#判断字符串是否为全中文import rekzb = re.findall(u"[^\u4e00-\u9fa5]+", "this is 明天依旧可好's blog")if len(kzb) == 0: print("该字符串中全为中文")else: print("该字符串中含有除中文以外的字符")print("输出匹配结果:" + str(kzb))"""该字符串中含有除中文以外的字符输出匹配结果:['this is ', "'s blog"]""" 3.2. 判断字符串是否全为英文
和判断字符串是否全为中文一样,这次我也采用逆向思维,匹配非英文字符,如果为匹配成功则说明该字符串全为英文名。
#判断字符串是否为全英文import rekzb = re.findall(u"[^a-zA-Z]+", "this is 明天依旧可好's blog")if len(kzb) == 0: print("该字符串中全为英文")else: print("该字符串中哈有除英文以外的字符")print("输出匹配结果:" + str(kzb))'''输出:该字符串中哈有除英文以外的字符输出匹配结果:[' ', " 明天依旧可好'", ' ']''' 然而Python提供了更加直接的isalpha()方法,用于帮助我们判断字符串是否为全英文,而不用我们自己去编写正则表达式。
print("this is 明天依旧可好's blog".isalpha())'''输出:False'''print("this is a blog".isalpha())'''输出:False'''print("thisisablog".isalpha())'''输出:True''' 如有不足欢迎留言指教!
转载地址:https://mtyjkh.blog.csdn.net/article/details/84935221 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
