实战项目一:爬取西刺代理(获取代理IP)
发布日期:2021-07-01 04:21:57
浏览次数:68
分类:技术文章
本文共 1606 字,大约阅读时间需要 5 分钟。
爬虫的学习就是与反扒措施、反扒系统做斗争的一个过程,而使用代理IP是我们重要的防反扒的重要措施,代理IP的来源有两种一是你花钱去购买商家会给你提供一个接口你直接调用就可以了,二是自己在网上爬取高效IP。在这篇博客中我重点给大家讲一下如何从网上获取高效IP,我们下面的IP来源于,这是我很久之前写的一篇博客,今天来进行“翻新”一番希望可以帮助到大家。
安装必要的第三方库
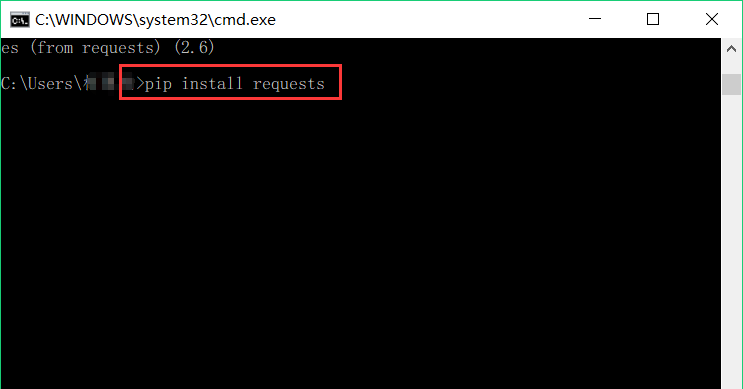
BeautifulSoup和requests,BeautifulSoup负责解析HTML网页源码,requests负责发送请求来获取网页源码,BeautifulSoup和requests均属于Python爬虫的基础库,可以通过pip安装。打开命令行输入命令pip install BeautifulSoup4和pip install requests进行安装:
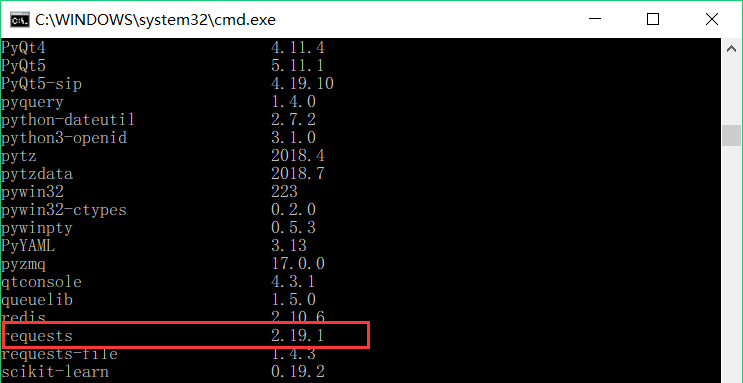
过后在输入命令pip list在pip安装包列表中检查BeautifulSoup和requests库是否安装成功
分析网页结构
待续。。。。
完整代码
#IP地址取自国内髙匿代理IP网站:http://www.xicidaili.com/nn/ from bs4 import BeautifulSoupimport requests,randomdef get_ipInfors(url, headers): ''' 爬取IP数据,单个IP信息以json格式存储,所有json格式的IP数据信息放入列表中 return:ip_infor ''' web_data = requests.get(url, headers=headers) soup = BeautifulSoup(web_data.text, 'lxml') nodes = soup.find_all('tr') for node in nodes[1:]: ip_ = node.find_all('td') ip_address = ip_[1].text ip_port = ip_[2].text ip_type = ip_[5].text ip_time = ip_[8].text ip_infors = { "ip_address" : ip_address, "ip_port" : ip_port, "ip_type" : ip_type, "ip_time" : ip_time } return ip_inforsdef write_ipInfors(ip_infors): ''' 将IP数据写入文件中 ''' for ip_infor in ip_infors: f=open('IP.txt','a+',encoding='utf-8') f.write(ip_infors) f.write('\n') f.close()if __name__ == '__main__': for i in range(1,10): url = 'https://www.xicidaili.com/nn/{}'.format(i) headers = { 'Host': 'www.xicidaili.com', 'Referer': 'https://www.xicidaili.com/', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36' } ip_infors = get_ipInfors(url, headers=headers) proxies = write_ipInfors(ip_infors) 转载地址:https://mtyjkh.blog.csdn.net/article/details/86750473 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
做的很好,不错不错
[***.243.131.199]2024年04月17日 11时55分51秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
架构设计与分层
2019-04-26
【01】Java面试----基础方面的陷阱
2019-04-26
排序算法整合
2019-04-26
Java程序员常见笔试题分析
2019-04-26
Java笔试题
2019-04-26
Spring Boot快速入门---(一)spring boot的创建及几种启动方式
2019-04-26
【物联网实训项目】------(一)家庭智慧安防系统之前期项目工作准备
2019-04-26
【物联网实训项目】------(二)家庭智慧安防系统之定时监控
2019-04-26
【物联网实训项目】------(三)家庭智慧安防系统之实时监控
2019-04-26
【物联网实训项目】------(四)家庭智慧安防系统之智能温控
2019-04-26
【物联网实训项目】------(五)家庭智慧安防系统之智能监控
2019-04-26
【物联网实训项目】------(六)家庭智慧安防系统之智能监控
2019-04-26
【物联网实训项目】------(七)家庭智慧安防系统之人脸验证
2019-04-26
日常琐事(一)
2019-04-26
数据结构----绪论
2019-04-26
篇章二线性表---基础知识
2019-04-26
篇章二线性表---常见操作
2019-04-26
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 306372720 位访客
访问时间: 2024-04-20 05:27:03
访问IP: 3.145.59.187
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版