本文共 3798 字,大约阅读时间需要 12 分钟。
这是我在某个项目写的一份爬虫代码,今天将它整理一下分享给大家,仅供参考学习,请勿用作其他用途。
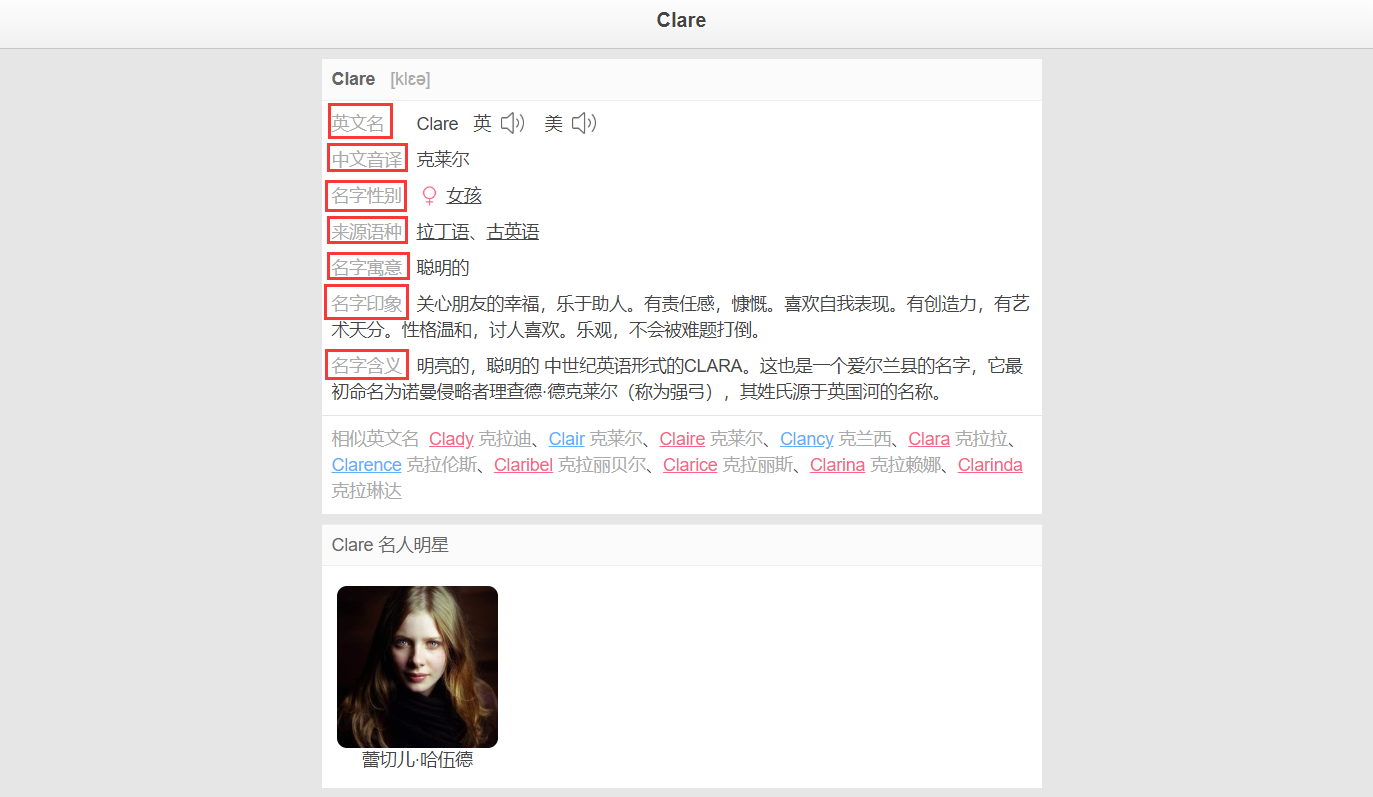
需要爬取的东西
我爬取的是 https://myingwenming.911cha.com 网站,采集的是网站中的中文音译、名字性别、来源语种、名字寓意、名字印象、名字含义6个数据。我分别设置namesChineseTransliteration、namesGender、namesFromLanguage、namesMoral、namesImpression、namesMeaning等6个字段来存放相应的数据。
防反扒措施
在这防反扒这一块我选择每发送一次requests请求更换一个User-Agent与IP。User-Agent的更换我依靠第三方库来完成,在每次发送requests请求前通过{'User-Agent':str(UserAgent().random)}语句来获取一个随机User-Agent。关于代理IP这块我则是事先准备好IP存放到IP.txt文件中,每一次发送requests前从该文件中随机获取一个IP用于本次请求。
def get_ip_list(): ''' 读取IP.txt中的数据 ''' f=open('IP.txt','r') ip_list=f.readlines() f.close() return ip_listdef get_random_ip(ip_list): ''' 从IP列表中获取随机IP ''' proxy_ip = random.choice(ip_list) proxy_ip=proxy_ip.strip('\n') proxies = { 'http': proxy_ip} return proxies 关于requests请求
我这里的requests请求供包含url、、headers、、verify五个参数,在每一次发送请求前更换新的proxies,headers并在超时处理,若请求时间超过10秒则中断本次请求,设置verify=False则会忽略对网页证书的验证。 在我遇到的反扒系统中有这样一种,拿出来和大家分享。对方识别到你的爬虫在网站上爬行时,不会阻止它的爬取行为而是让其陷入一种死循环转态,表现的形式是:本报错同时也不会返回任何数据。在requests请求中加上一个超时设置就可以很好避开该反扒措施。
关于网页解析
在网页解析这块我选择的是Python解析库BeautifulSoup4与解析器lxml,在定位方面我选择的是find()与find_all(),find()返回的是单个结点,find_all()返回结点列表,在提取文本信息中我这里使用的是get_text()。
首先定位到<div class="pp">,其次是div下的p标签,最后分别存入对应的字段当中。
soup = BeautifulSoup(r.text, 'lxml')body = soup.find("div", class_="pp")contents = body.find_all('p') 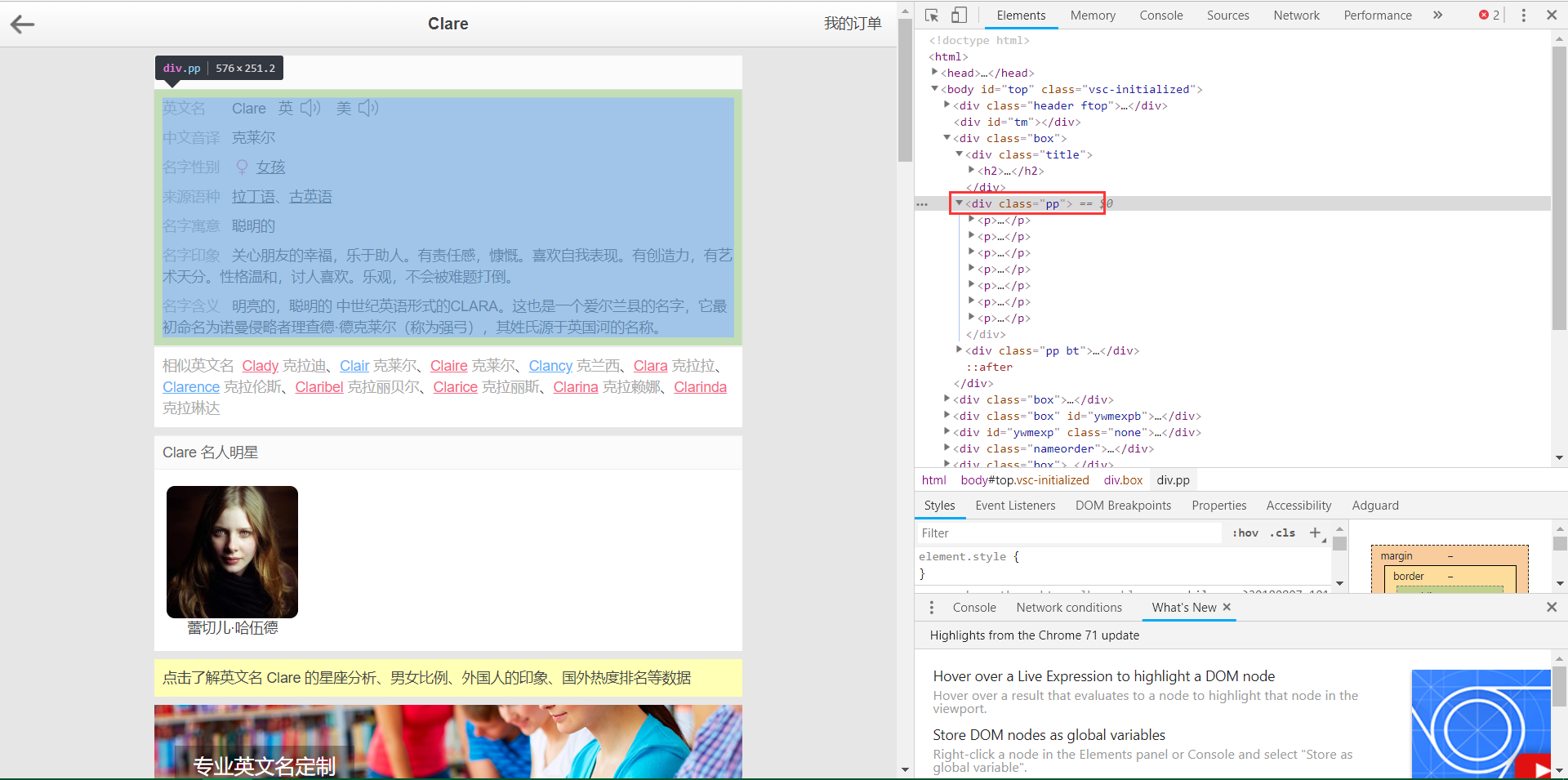
完整代码
from fake_useragent import UserAgentfrom bs4 import BeautifulSoupimport pandas as pdimport requests,csv,time,randomdef get_ip_list(): ''' 读取IP.txt中的数据 ''' f=open('IP.txt','r') ip_list=f.readlines() f.close() return ip_listdef get_random_ip(ip_list): ''' 从IP列表中获取随机IP ''' proxy_ip = random.choice(ip_list) proxy_ip=proxy_ip.strip('\n') proxies = { 'http': proxy_ip} return proxiesdef parsePage(url,ip_list): ''' 爬取网页并返回所需信息以及状态码 ''' headers= { 'User-Agent':str(UserAgent().random)} proxies = get_random_ip(ip_list) try: #verify设置为False,Requests也能忽略对SSL证书的验证。 r = requests.get(url, proxies=proxies, headers=headers, timeout=10,verify=False) except: print('运行错误,程序暂停20秒') time.sleep(20) headers= { 'User-Agent':str(UserAgent().random)} proxies = get_random_ip(ip_list) r = requests.get(url, proxies=proxies, headers=headers, timeout=10, verify=False) #状态码status_code为200代表爬取成功,为404则为未爬取到相关信息 if r.status_code == 200: soup = BeautifulSoup(r.text, 'lxml') body = soup.find("div", class_="pp") contents = body.find_all('p') return r.status_code, contents else: return r.status_code, Nonedef getDict(contents): namesChineseTransliteration = [] #中文音译 namesGender = [] #名字性别 namesFromLanguage = [] #来源语种 namesMoral = [] #名字寓意 namesImpression = [] #名字印象 namesMeaning = [] #名字含义 namesChineseTransliteration.append(contents[1].get_text()[4:]) namesGender.append(contents[-5].get_text()[4:]) namesFromLanguage.append(contents[-4].get_text()[4:]) namesMoral.append(contents[-3].get_text()[4:]) namesImpression.append(contents[-2].get_text()[4:]) namesMeaning.append(contents[-1].get_text()[4:]) str_row=namesChineseTransliteration+namesGender+namesFromLanguage+namesMoral+namesImpression+namesMeaning return str_row def write_file(filePath, row): with open(filePath,'a+',encoding='utf-8',newline='') as csvfile: spanreader = csv.writer(csvfile,delimiter='|',quoting=csv.QUOTE_MINIMAL) spanreader.writerow(row)if __name__ == "__main__": names = pd.read_csv("name_data.csv")['name'] #获取需要爬取文件的名字 base_url = "https://myingwenming.911cha.com/" ip_list = get_ip_list() for name in names: url = base_url + name + ".html" status_code, contents = parsePage(url,ip_list) print("{}检索完成".format(name), "状态码为:{}".format(status_code)) #状态码为200爬取成功,状态码为404爬取失败 if status_code == 200: str_row = getDict(contents) row = ["{}".format(name)] + str_row write_file("new.csv",row) else: continue 有不明的地方在下方留言,我看到后会尽快回复的
欢迎进行我的博客导航: 我的专栏:、转载地址:https://mtyjkh.blog.csdn.net/article/details/86750865 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
