本文共 851 字,大约阅读时间需要 2 分钟。
UserAgent是识别浏览器的一串字符串,相当于浏览器的身份证,在利用爬虫爬取网站数据时,频繁更换UserAgent可以避免触发相应的反爬机制。fake-useragent对频繁更换UserAgent提供了很好的支持,可谓防反扒利器。下面将介绍fake-useragent的安装到使用。
安装
在命令行中输入pip install fake-useragent即可完成安装。
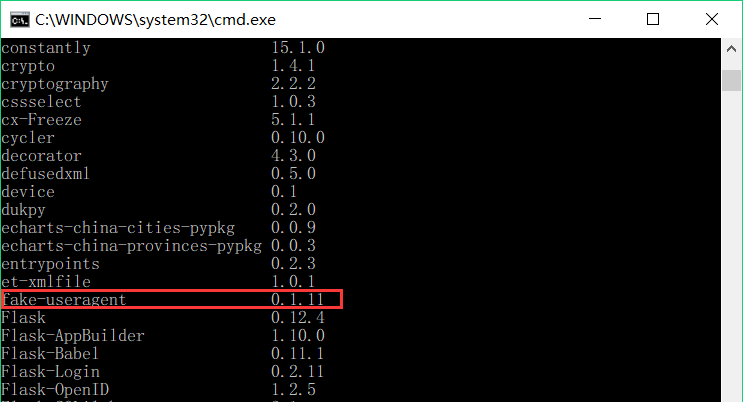
继续输入pip list在检查fake-useragent是否在pip的已安装包列表中,判断其知否安装成功。
使用
安装成功后,我们每次发送requests请求时通过random从中随机获取一个随机UserAgent,两行代码即可完成UserAgent的不停更换。
from fake_useragent import UserAgentheaders= { 'User-Agent':str(UserAgent().random)}r = requests.get(url, proxies=proxies, headers=headers, timeout=10) 更新
我在使用fake_useragent中遇到如下的报错,在起初误认为是部分网站对某些UserAgent的屏蔽导致的fake_useragent调用出错,后来追究下来发现是由于fake_useragent中存储的UserAgent列表发生了变动,而我本地UserAgent的列表未更新所导致的,在更新fake_useragent后报错就消失了。关于这个报错知道更多细节的同学,欢迎在下面留言!
fake_useragent.errors.FakeUserAgentError: Maximum amount of retries reached
更新fake_useragent,在命令行中输入pip install -U fake-useragent即可完成更新,Python的其他包也可以用这种方法完成更新pip install -U 包名。
转载地址:https://mtyjkh.blog.csdn.net/article/details/86751142 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
