本文共 7724 字,大约阅读时间需要 25 分钟。
文章目录
1 字符集、代码点、编码的概念
任何信息存储在计算机中,都将是无差别的0和1的序列。所以,我们要想在计算机中存储字符,那么,我们就需要对字符进行编码,将字符编码为计算机可以识别的0和1的序列。编码就是将信息从一种形式转换为另一种形式。
字符集:
在编码之前,我们首先要确定,我们要对哪些字符进行编码。然后,将这些需要进行编码的字符集合到一起,这样就形成了我们所说的字符集。常见的字符集有:ASCII、GBK、GB2312、Unicode等等。代码点:
字符集中的每一个字符都会被分配一个编号,这个编号我们称之为代码点。 需要注意如下:在ASCII字符集中,代码点是从0开始依次递增的 。但是,并非所有的字符集,代码点都是从0开始依次递增的。编码:
为了在计算机中存储字符,我们需要将字符的代码点转换为0和1的序列,而这个转换的过程,我们称之为字符编码。要想在计算机存储字符,需要经过如下5个步骤:
字符 --> 代码点 --> 编码 --> 0和1的序列(字符的编码) --> 存储到计算机中。2 字符集发展的脉络
2.1 最早是ASCII
最早出现的字符集是ASCII。
2.2 各个国家后续推出的编码表
欧洲:ISO-8859-1、在ASCII基础上的扩充(扩展ASCII编码表)。
中国: GB2312 -> GBK -> GB18030(新的兼容旧的)。
台湾: BIG5。
日本: JIS。
2.3 ANSI到底是什么编码
ANSI对于不同语言的操作系统对应的编码是不同的,如下:
- 简体中文操作系统:GB2312。
- 繁体中文操作系统:Big5。
- 日文操作系统:JIS。
- 英文操作系统:ASCII。
3 ASCII
3.1 ASCII字符集简介及其编码的字符
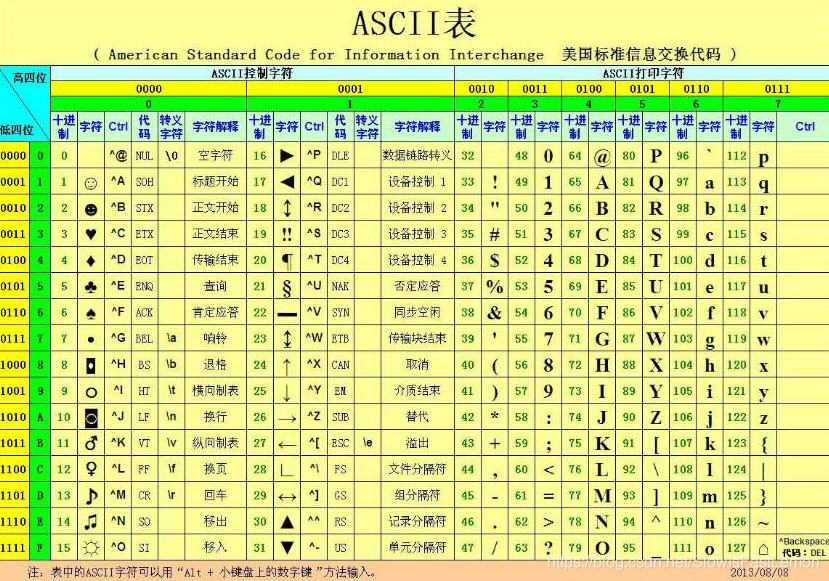
3.2 ASCII字符集的代码点
在ASCII字符集中,代码点是从0开始依次递增的。
3.3 ASCII字符集的编码方式
直接将代码点编码为它所对应的8位二进制数即可。
注意: 一个字节并非一定是8位,所以,严格来说应该是:转换为它所对应的1个字节长的二进制数。
3.4 扩充的ASCII编码
欧洲:ISO-8859-1、在ASCII基础上的扩充(扩展ASCII编码表)。
4 GB2312
4.1 GB2312字符集简介及其编码的字符
包括了汉字信息交换用的基本图形字符。GB2312兼容ASCII,由两个大于127的字节来映射我们增加的字符。发现最高位是0,那么就可以确定这个字节映射的就是ASCII的字符,那么就只读取一个字节,然后去查ASCII表,然后将其解析为对应的字符。发现最高位是1,那么就可以确定这个字节映射的就是GB2312的字符,那么就连续读两个字节,然后去查GB2312,然后将其解析为对应的字符。
4.2 GB2312字符集的代码点
GB2312字符集中,代码点是根据区号和位号来安排的。
GB2312将字符划分为了94个区(区号从1-94),每个区94个字符。字符在区里面的位置叫做位号(位号从1-94)。
比如:字符 <健>,它属于第29区中的第一个字符那么,字符 <健>的区号就是29,位号就是1。 GB2312的代码点计算方式如下:区号+32,位号+32 --> 代码点,那么健的代码点就是61,33。
GB2312的代码点计算方式如下:区号+32,位号+32 --> 代码点,那么健的代码点就是61,33。 +32的原因:
GB2312字符集除了兼容ASCII以外,它还对原ASCII中打印字符进行了2字节的编码,就是我们平时所说的全角字符(第3区)。 全角字符在显示和打印的时候,字符的轮廓占一个汉字的位置:- AAA --> 半角
- AAA --> 全角
为了使全角字符的位号和它所对应的半角字符在ASCII中的代码点保持一致,以方便它们之间的互转。所以,我们对位号+32得到最终的代码点 。区号为什么+32?暂时不知道,哈哈哈哈。

4.3 GB2312字符集的编码方式
由于GB2312字符集兼容ASCII,所以,原ASCII的字符仍旧按照它原来的方法进行编码(1个字节)。GB2312采用2个字节对自身的字符进行编码:区号转换为二进制存入高字节中,位号转换为二进制数存入低字节中,两个字节的最高位固定为1。
最高位固定为1的原因:
如果一个字节,它的最高位为0,那么,我们就可以判定这个字节存储的是ASCII字符的编码,我们就应该按照ASCII的字符编码方法对它进行解析,得到正确的结果。如果一个字节,它的最高位为1,我们就可以判定这个字节及其后面的一个字节,存储的是GB2312字符的编码,我们就应该将这个字节及其后面的一个字节,按照GB2312的字符编码方法对它进行解析,得到正确的结果。5 GBK
随着计算机的发展,它的普及率越来越高,它的应用场合也越来越多,而GB2312字符集中只有6763个汉字,而我们常用的汉字就有几千个。显然,这6763个汉字已经满足不了越来越多的使用场合了。
因此,我们在GB2312字符集的基础上进行了扩充,建立了GBK字符集:
- GBK字符集 兼容 GB2312字符集(这就意味着GBK也是兼容ASCII的)
- GBK字符集 仍然采用1个字节对原ASCII字符进行编码,仍然采用2个字节对原GB2312字符进行编码,采用2个字节对扩充进来的字符进行编码。
- GBK字符集 不要求低字节最高位固定为1。因为,它需要更多的空间来对扩充进来的字符进行编码。
6 GB18030
随着时间的推进,我们在GBK字符集的基础上又创建了GB18030字符集。
- GB18030字符集 兼容 GBK字符集(这就意味着GB18030兼容GB2312、兼容ASCII)
- GB18030字符集 仍然采用1个字节对原ASCII字符进行编码,仍然采用2个字节对原GB2312字符进行编码,仍然使用2个字节对原GBK字符进行编码。采用4个字节对扩充进来的字符进行编码因为,它需要更多的空间来对扩充进来的字符进行编码。
兼容性: ASCII(128) --> GB2312(7445) --> GBK(21886) --> GB18030(汉字70,244)。
7 Unicode
Unicode标准有两套,不过后期这两套标准基本上是一致的。
UNICODE协会:
- 字符集全称:Universal Character Encoding
- 缩写:UNICODE
- 翻译:通用字符集编码
ISO 10646工作组:
- 字符集全称:Universal Coded Character Set
- 缩写:UCS
- 翻译:通用编码字符集
- 标准号:ISO 10646
7.1 Unicode介绍
UNICODE字符集分为 17个区(标准的称呼应该是 17个平面):
- 区号为: 0-16(0x00 - 0x10),每个区65536个字符。
- 位号为: 0-65535(0x0000 - 0xFFFF)。
代码点: 高两位十六进制数对应的是区号、低四位十六进制数对应的是位号 。
- 平面0的代码点:0x00 0000 - 0x00 FFFF
- 平面1的代码点:0x01 0000 - 0x01 FFFF
- 平面2的代码点:0x02 0000 - 0x02 FFFF
- …
- 平面17的代码点:0x10 0000 - 0x10 FFFF
由此可以发现:
- UNICODE字符集的代码点是从0开始依次递增的(和ASCII一致)。
- UNICODE字符集的代码点范围:0x00 0000 - 0x10 FFFF。
代码点表示方法:
- U+十六进制数字 ,比如:U+00 00FF(所以,上面表示代码点的方法是错误的)。
低0区的字符:
- 第0区的字符是每个国家和地区的常用字符。也就是说,第0区混杂了各个国家常用的字符。
- 第0区又叫做:基本多语种平面。
思考:为什么这么做?
第0区代码点的数值较小,所对应的编码值也较小,这就意味着第0区代码点更节省空间(我们不一定非要采用3个字节来对Unicode进行编码)。那么很显然,将使用较为频繁的常用字符分配到第0区,就意味着更加节省空间。UNICODE字符集的标准编码规则是UTF-8、UTF-16、UTF-32,下面分别介绍。
7.2 UTF-8:变长的编码规则
UTF-8以1个字节为单位,分别使用1个字节、2个字节、3个字节、4个字节对字符进行编码。
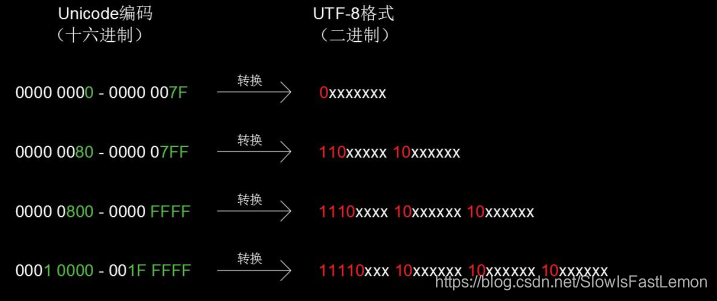
( x的序列 --> 代码点所对应的二进制形式 )
- 1个字节:对于平面0中的原ASCII字符,使用1个字节进行编码(兼容ASCII)
- 0xxxxxxx (填充7位–>128种组合–>128个字符)
- 2个字节:对于平面0中的原ASCII字符后面的1920个字符,使用2个字节进行编码
- 110xxxxx 10xxxxxx (填充11位–>2048种组合–>2048个字符–>1920 +128=2048)
- 3个字节:对于平面0剩余的字符,使用3个字节进行编码
- 1110xxxx 10xxxxxx 10xxxxxx (填充16位–>65536种组合–>65536个字符–>平面0:65536个字符)
- 4个字节:对于其它平面(辅助平面)的字符,使用4个字节进行编码
- 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx(填充21位–>2097151种组合–>2097151个字符–>远远高于字符集实际代码点最大值)
7.3 UTF-16:变长的编码规则
UTF-16以2个字节为单位,分别使用2个字节、4个字节对字符进行编码(不兼容ASCII)。

( x的序列 --> 代码点所对应的二进制形式 )
- 2个字节:对平面0的字符,使用2个字节进行编码
- xxxxxxxx xxxxxxxx (16位–>65536种组合–>65536个字符–>平面0:65536个字符)
( z的序列 --> 代码点所对应的二进制数 减去 0x10000 )
- 4个字节:对其它平面的字符,使用4个字节进行编码
- 110110zz zzzzzzzz 110111zz zzzzzzzz (填充20位–>1048576种组合–>1048576个字符–>低于字符集实际代码点最大值–>这也是-0x10000的原因)
对于4字节的编码来说:
- 高2字节取值范围:11011000 00000000 - 11011111 11111111 --> D800-DBFF
- 低2字节取值范围:11011100 00000000 - 11011111 11111111 --> DC00-DFFF
现在的问题是:对于2字节的编码来说,也可能出现110110xx xxxxxxxx 或者 110111xx xxxxxxxx 这样的编码。意思就是:2字节的编码,也可能是以 110110 或者 110111 作为开头的。这时,我们就无法区分2个字节的数据,它到底是2个字节的编码还是4个字节编码的一部分。因为,高位上的 110110 和 110111 是我们进行区分的标识,而2字节编码的高位也可能是一样的数值。为了解决这个问题:UNICODE协会禁止 D800 - DFFF 区间的代码点对应任何字符。这样的话,2字节的编码就避免了以 110110 或者 110111 开头,因为,在这个区间的代码点没有对应任何字符。
7.4 UTF-32:定长的编码规则
对每个代码点都使用固定的4个字节进行编码(不兼容ASCII),直接将代码点所对应的二进制扩充为32位(高位补0)即可。
7.5 Unicode字符存储的字节序问题
我们可以常常看到如下形式编码:UTF-16LE、UTF-16BE、UTF-32LE、UTF -32BE 。为什么UTF-16和UTF-32的后面会有LE、BE的标志呢?为什么UTF-8的后面没有LE、BE的标志呢?
UTF-8的存储过程如下:
- UNICODE字符集 --> 代码点 --> UTF-8 --> 编码值 --> 存储。
UTF-16和UTF-32的存储过程如下:
- UNICODE字符集 --> 代码点 --> UTF-16或UTF-32 --> 编码值 --> 确认排序 --> 存储。
为什么需要确认排序?字节顺序会影响对数据的解析结果。
排序是排的哪部分的序?编码单位内部的字节顺序。
UTF-8字符存储的字节序问题:
UTF-8编码规则,是以字节为单位的。怎么理解呢?字节的存储顺序不影响对数据的解析结果 。所以,它不可能存在乱序的问题。所以,不需要排序。比如,对于”小马奔腾“(下面的编码都是假设值,并不是真正的值):
- 小 --> 1字节编码 0xxxxxxx
- 马 --> 2字节编码 110xxxxx 10xxxxxx
- 奔 --> 3字节编码 1110xxxx 10xxxxxx 10xxxxxx
- 腾 --> 4字节编码 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
实际的存储情况:从第一个字符开始,顺序存储,且每个字符都从高字节开始存储。存储内容如下:
0xxxxxxx 110xxxxx 10xxxxxx 1110xxxx 10xxxxxx 10xxxxxx 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx 如果我们按照从第一个字符开始,顺序存储,每个字符从低字节开始存储,仍然不影响解析结果,因为每一个字符的最高字节都有特定的标志。存储内容如下: 0xxxxxxx 10xxxxxx 110xxxxx 10xxxxxx 10xxxxxx 1110xxxx 10xxxxxx 10xxxxxx 10xxxxxx 11110xxxUTF-16字符存储的字节序问题:
UTF-16编码规则,是以2字节为单位的。我们需要知道,2字节的存储顺序不影响对数据的解析结果 ,但是2字节内部的存储顺序则会影响对数据的解析结果。比如,对于马来说:
- 马 --> 4字节编码 110110zz zzzzzzzz 110111zz zzzzzzzz
是按照110110zz zzzzzzzz 110111zz zzzzzzzz这种格式存储,还是按照110111zz zzzzzzzz 110110zz zzzzzzzz这种格式存储,都不影响解析结果,因为对于4字节编码,每个2字节中的高字节都有特定的开始标志。
实际的存储情况:从第一个字符开始,顺序存储,且每个字符都是按照从高2字节开始存储。
我们上面也说了,2字节内部的顺序可以影响对数据的解析结果。看如下例子:
假设有如下两个字的编码:
- 奔 --> 4字节编码 11011010 11011011 11011100 11011101
- 腾 --> 4字节编码 11011011 11011010 11011101 11011100
对于两字节内部的顺序我们可以按照大端的格式存储,也可以按照小端的格式存储:
- BE Big-Endian – 大端:11011010 11011011 11011100 11011101
- LE Little-Endian – 小端:11011011 11011010 11011101 11011100
如果解析端未能按照正确的格式解析,就会出现字符解析错误的情况。所以,为了避免由于2字节内部的字节顺序而导致数据被错误的解析,所以,UNICODE给我们提供了LE、BE的选择。
那么对于UTF-16两字节编码也是同样的情况:
假设有如下两个字符的编码:- 小 --> 2字节编码 10000000 00000000
- 马 --> 2字节编码 00000000 10000000
BE:
- 10000000 00000000
LE:
- 00000000 10000000
UTF-32字符存储的字节序问题:
UTF-32编码规则,是以4字节为单位的,且所有的字符都是固定的4个字节。所以,4字节内部的顺序会影响对数据的解析,且存储只存在两种情况。假设有如下两个字符的编码:
- 小 --> AA AB AC AD
- 马 --> BA BB BC BD
对于不同的字符来说,一定是从第一个字符开始,顺序存储。
我们有如下两种情况进行存储:- BE:AA AB AC AD
- LE:AD AC AB AA
所以,为了避免由于4字节内部的字节顺序而导致数据被错误的解析,所以,UNICODE给我们提供了LE、BE的选择。
7.6 UTF-16和UTF-32的三种子风格、BOM
BOM:
BOM(byte order mark:字节顺序标记),放在文本的开头,用于标识字节序。UTF-16编码值:U+FE FF 、UTF-32编码值:U+00 00 FE FF。对于不带BOM的编码格式,则对于解析端则必须知道编码格式才能正确解析,否则就会解析错误。
UTF-8带BOM:
UTF-8可以带BOM,但是,这并不会影响字符的存储的字节顺序。它仅仅是用来提示当前文本是使用UTF-8存储的,仅此而已。比如:
- 我 --> 使用UTF-8不带BOM的实际存储效果 --> E6 88 91
- 我 --> 使用UTF-8带BOM的实际存储效果 --> EF BB BF E6 88 91
UTF-16的三种子风格:
有如下字符: UNICODE字符集 --> --> UTF-16 --> 编码值:D8 00 DC FF实际存储效果:
- UTF -16BE --> D8 00 DC FF (windows会存储为带BOM的形式,如果其他系统下不会存储为带BOM的形式,那么解析的时候必须知道存储格式才能解析成功,否则解析失败,将乱码)
- UTF -16LE --> 00 D8 FF DC (windows会存储为带BOM的形式)
- UTF-16
- –> 默认:D8 00 DC FF(实际对应BE)
- –> 带BOM:FE FF D8 00 DC FF(实际对应BE) –> 带BOM:FF FE 00 D8 FF DC(实际对应LE)
UTF-32的三种子风格:
有如下字符: UNICODE字符集 --> --> UTF-32 --> 编码值:00 01 00 FF实际存储效果:
- UTF -32BE --> 00 01 00 FF (windows会存储为带BOM的形式)
- UTF -32LE --> FF 00 01 00 (windows会存储为带BOM的形式)
- UTF-32
- –> 默认:00 01 00 FF(实际对应BE)
- –> 带BOM:00 00 FE FF 00 01 00 FF(实际对应BE)
- –> 带BOM:FF FE 00 00 FF 00 01 00(实际对应LE)
注意: 不带BOM的前提一定是编码端和解析端已经统一了编码规则!
7.7 UCS-2和UCS-4
关于UCS-2和UCS-4的内容参见如下博客即可:
参考资料:
转载地址:https://muzimin.blog.csdn.net/article/details/102934301 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
