本文共 4330 字,大约阅读时间需要 14 分钟。
Gmapping 原理分析
概念:
1.Gmapping是基于滤波SLAM框架
2.Gmapping是基于RBpf粒子滤波算法,即将定位与建图过程分离开,先进行定位后进行建图
3.Gmapping在RBpf上主要做了两个方面的改进:改进提议分布和选择性重采样
Gmapping有效利用了车轮里程计信息,这也是Gmapping对激光雷达频率要求较低的原因:里程计可以提供机器人的先验位姿。而hector和cartographer的设计初衷不是为了解决平面移动机器人定位和建图,Heator主要用于救灾等地面不平坦的场景,因此无法使用里程计。而cartographer是用于手持激光雷达完成SLAM的过程,也没有里程计可以用。
随着场景的增大所需要的粒子增加,因为每一个粒子都需要携带一副地图,因此在构建大地图时所需要的粒子和计算量都需要增加。因此不适合构建大的地图场景。并且没有回环检测,因此在回环闭合时可能造成地图错位,虽然增加粒子数可以使地图闭合但是以增加计算量和内存为代价。Gmapping和Cartographer一个是基于滤波框架的SLAM另一个是基于优化框架的SLAM。
提出问题:
1.为什么RBpf可以将定位和建图分离;
2.Gmapping是如何在RBpf的基础上改进提议分布的;
3.为什么要执行选择性重采样
4.什么是粒子退化及如何防止粒子退化
5.为什么Gmapping严重依赖里程计
6.什么是提议分布
7.什么是目标分布
8.为什么需要提议分布和目标分布
9.算法中是如何计算权重
10.粒子滤波粒子数和传感器精度之间的关系
11.为什么在大回环的环境中增加粒子数可以使建出的地图正确闭合
12.Gmapping是基于滤波框架的SLAM方法,为什么建图过程中界面上显示的地图不断调整
摘要
这部分简单解释了Gmapping是基于RBpf。RBpf是一种有效解决同时定位与建图的算法,它将定位与建图分开;并且每一个粒子都携带一副地图。但是RBpf也存在缺点:所用粒子数多和频繁执行重采样。粒子数多会造成计算量和内存消耗变大;频繁执行重采样会造成粒子退化。因此Gmapping在RBpf的基础上改进提议分布和选择性重采样,从而减少粒子个数和防止粒子退化。改进提议分布不但考虑里程计信息还考虑最近一次的观测(激光)信息这样就可以使提议分布的更加精确从而更加接近目标分布。选择性重采样通过设定阈值,只有在粒子权重变化超过阈值时才执行重采样从而大大减少重采样的次数。
这里可以先回答第一个问题:为什么RBpf可以先定位后建图?
这里我们用公式来描述一下:
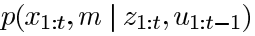
我们有观测和控制数据共同推测位姿和地图。由概率论可知联合概率可以转变为条件概率 即:P(x,y) = p(y|x)p(x)
通俗点解释就是我们在求两个变量的联合分布时,可以先求一个变量,再将这个变量作为条件求解另一个变量。这就解释Gmapping为什么先定位后建图:同时定位与建图是比较困难的,因此我们可以先求解位姿,然后在已知位姿的条件下进行建图。
第一章 简介:
RBpf被引入解决SLAM问题,即先定位再建图。RBpf的主要问题在于其复杂度高,因为需要较多的粒子来构建地图并频繁的执行重采样。因此减少粒子数是RBpf算法改进的方向之一;同时由于RBpf频繁执行重采样造成粒子退化。因此减少粒子重采样次数是RBpf算法改进的另一个方向。
这里回答一下:什么是粒子退化?
粒子退化主要是指正确的粒子被丢弃和粒子多样性的减少,而频繁重采样则加剧了正确的粒子被丢弃的可能性和粒子多样性减小的速率。这里先涉及一下重采样的知识,我们知道在进行重采样之前会计算每个粒子数的权重,有时会因为环境相似度高或是由于测量噪声的影响会使接近正确状态的粒子数权重较小而错误状态的粒子的权重反而会大。重采样是依据粒子权重来采集粒子的,这样正确的粒子就可能被丢弃,频繁的执行重采样则更加剧了正确但权重较小的粒子被丢弃的可能性。这也就是粒子退化的原因之一。
另外一个原因就是频繁重采样导致粒子多样性减少的速率加大,什么是粒子多样性呢?就是粒子的不同,最开始有十个粒子,如果发生重采样后其中五个粒子被丢弃,剩下五个粒子复制出五个粒子,这时十个粒子只要五个粒子是不同的,也就是粒子多样性减少。
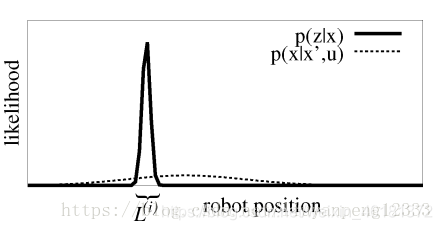
回到论文中,为了减少粒子数,Gmapping提出了改进提议分布,为了减少重采样的次数Gmapping提出了选择性重采样。现在问题到了如何改进提议分布了,先简单说一下后面会有详细介绍。就以下图为例,图中虚线为p(x|x’,u)的概率分布也就是我们里程计采样的高斯分布,这里只是一维的情况。实线为p(z|x)的概率分布也就是使用激光进行观测后获得状态的高斯分布。由图可知,观测提供的信息的准确度(方差小)相比控制的准确度要高很多,这就是Gmapping改进提议分布的动因。但问题是我们无法对观测建模,这就造成了我们想用观测但是观测的模型又不能直接获得,后面的论文中改进提议分布就是围绕如何利用最近一次观测来模拟目标分布。
第二章 使用RBpf建图:
这节主要讲RBpf建图的过程,首先RBpf是个什么东西(好像骂人的话哈哈哈)?SLAM要解决的问题就是由控制数据U1:t和观测数据Z1:t来求位姿和地图的联合分布:
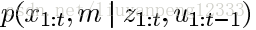
问题是这两个东西在一起并不好求,怎么使用条件概率把这两个拆开,先求解位姿,我们知道有了位姿后建图是一件很容易的事情。这就是RB要做的事情:先定位再进行建图。公式就变成了下面的形式:
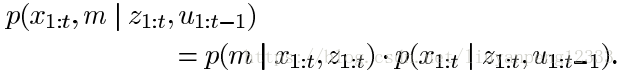
为了估计位姿,RBpf使用粒子滤波来估计机器人位姿,而粒子滤波中最常用的是重要性重采样算法。这个算法通过不断迭代来估计每一时刻机器人的位姿。算法总共包括四个步骤:采样- 计算权重-重采样-地图估计
粒子滤波部分参考:https://blog.csdn.net/weixin_46181372/article/details/110763976
下面会用到提议分布和目标分布的知识,这里我先回答一下什么是提议分布和目标分布以及为什么需要这两个概念?
目标分布:什么是目标分布,就是我根据机器人携带的所有传感器的数据能确定机器人状态置信度的最大极限。我们知道机器人是不能直接进行测量的,它是靠自身携带的传感器来获得对自身状态的估计。比如说我们想要估计机器人位姿就会有一个不确定度,这个不确定度是机器人对当前位姿确定性的最大极限,因为我没有数据信息来对机器人的状态进行约束了。机器人位姿变量通常由高斯函数来表示,不确定度就对应变量的方差。
提议分布:为什么要有提议分布?有人会说有了目标分布为什么还要有提议分布进行采样来获取下一时刻机器人位姿信息。答案是没有办法对目标分布建模采样。知道里程计模型的都明白里程计模型是假设里程计三个参数是服从高斯分布的,因为我们可以从高斯分布中采样出下一时刻起的位姿。但对于激光观测是无法进行高斯建模的,这样是激光SLAM使用粒子滤波而不是使用扩展卡尔曼滤波的原因之一。为什么呢?我们知道基于特征的SLAM算法经常会用到扩展卡尔曼滤波,因为基于特征的地图进行观测会返回机器人距离特征的一个距离和角度值,这时很容易对观测进行高斯建模然后使用扩展卡尔曼滤波。而激光返回的数据是360点的位置信息,每个位置信息都包括一个距离和角度信息,要对360个点进行高斯建模计算量不言而喻。但问题是我们希望从一个分布中进行采样来获取对下一时刻机器人位姿的估计,而在计算机中能模拟出的分布也就是高斯分布、三角分布等有限的分布。因此提议分布被提出来代替目标分布来提取下一时刻机器人位姿信息。而提议分布毕竟不是目标分布因此使用粒子权重来表征提议分布和目标分布的不一致性。
第三章 在RBpf的基础上改进提议分布和选择性重采样
这要围绕如何改进提议分布和选择性重采样展开:
我们知道我们需要从提议分布中采样得到下一时刻机器人的位姿。那么提议分布与目标分布越接近的话我们用的粒子越少,如果粒子直接从目标分布中采样的话,只需要一个粒子就可以获得机器人的位姿估计了。
但是由第一幅图片我们可知里程计提供位姿信息的不确定度要比激光大的多,我们知道激光的分布相比里程计分布更接近真正的目标分布,因此如果可以把激光的信息融入到提议分布中的话那样提议分布就会更接近目标分布。
同时因为粒子要覆盖里程计状态的全部空间,而这其中只有一小部分粒子是正真符合目标分布的,因此在计算权重时粒子的权重变化就会很大。但我们只有有限的粒子来模拟状态分布,因此我们需要把权重小的粒子丢弃,让权重大的粒子复制以达到使粒子收敛到真实状态附近。但这就造成需要频繁重采样,也就造成了RBpf的另一个弊端即:发生粒子退化。这里就解释了RBpf需要大量粒子并执行频繁重采样。
为了改进提议分布,论文中使用最近的一次观测,因此提议分布变成了:

为了获得改进的提议分布,我们可以第一步从运动模型采集粒子,第二步使用观测对这些粒子加权以选出最好的粒子。然后用这些权重大粒子来模拟出改进后的提议分布。但是如果观测概率比较尖锐则需要更多的粒子数目以能够覆盖观测概率。这样就导致了和从里程计中采样相同的问题,计算量太大。
目标分布通常只有几个峰值并在大多数情况下只有一个峰值。因此我们可以直接从峰值附近采样的话就可以大大简化计算量。因此论文中在峰值附近采K个值来模拟出提议分布。首先使用扫描匹配找出概率大的区域然后进行采样。我们通常使用高斯函数来构建提议分布,因此有了K个数据后我们就可以模拟出一个高斯函数作为提议分布:
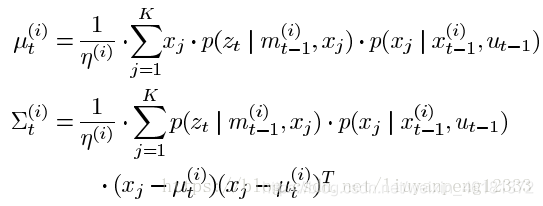
有了模拟好的提议分布我们就可以采样出下一时刻机器人的位姿信息。
这里还有一个问题就是权重计算,我们知道权重描述的是目标分布和提议分布之间的差别。因此我们在计算权重时就是计算我们模拟出的提议分布和目标分布的不同。而这种不同体现在我们是由有限的采样模拟出目标分布,因此权重的计算公式为:
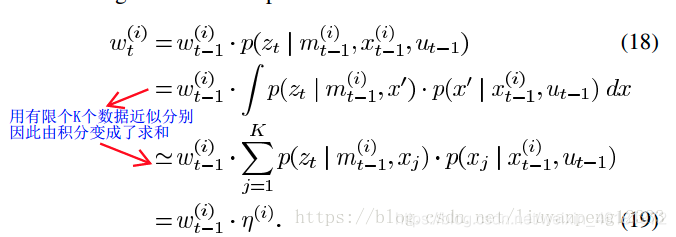
到此改进提议分布就完成了,接下来是选择性重采样。这部分比较简单,就是设定一个阈值,当粒子的权重变化大于我们设定的阈值时就会执行重采样,这样减少了采样的次数,也就减缓了粒子退化。至此理论部分就讲完了!
总结:
可以参考粒子滤波的文章一起阅读,方便理解一些:https://blog.csdn.net/weixin_46181372/article/details/110763976
感觉还是有一些地方没有看懂,后续还要再结合源码深入了解一下!
本文转载自:https://blog.csdn.net/liuyanpeng12333/article/details/81946841
转载地址:https://blog.csdn.net/weixin_46181372/article/details/111240459 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
