Python批量爬取堆糖图片
运行环境
发布日期:2022-02-14 16:09:26
浏览次数:22
分类:技术文章
本文共 1213 字,大约阅读时间需要 4 分钟。
B站一个不错的课程,老师除了开车猛还是有点内容的,适合新手https://www.bilibili.com/video/av32585321?from=search&seid=8881547171717169037#coding=utf-8import requestsimport urllibimport jsonimport jsonpath #%E7%BE%8E%E9%A3%9F#https://www.duitang.com/napi/blog/list/by_search/?kw=%E7%BE%8E%E9%A3%9F&type=feed&include_fields=top_comments%2Cis_root%2Csource_link%2Citem%2Cbuyable%2Croot_id%2Cstatus%2Clike_count%2Clike_id%2Csender%2Calbum%2Creply_count%2Cfavorite_blog_id&_type=&start=24&_=1547548611250url='https://www.duitang.com/napi/blog/list/by_search/?kw={}&start={}'label="英雄联盟" #在代码中直接改搜索内容即可下载搜索图片#转码字符label=urllib.quote_plus(label)#print(label)num=0for index in range(0,2400,24): #print(index) u=url.format(label,index)#转码信息和翻页数字,每一个Jason 文件 # print(u) we_data = requests.get(u).text #请求网站 并返回网页源代码的文本形式 # print(we_data) html =json.loads(we_data) #Json格式的字符串解码转换成Python能够识别的 photo =jsonpath.jsonpath(html,"$..path") # count = jsonpath.jsonpath(html,"$..count") # print(count) #print(photo) for i in photo: a = requests.get(i) with open(r"E:\2333\{}.jpg".format(num),"wb") as f: f.write(a.content) num+=1
代码运行出来的效果以及运行环境
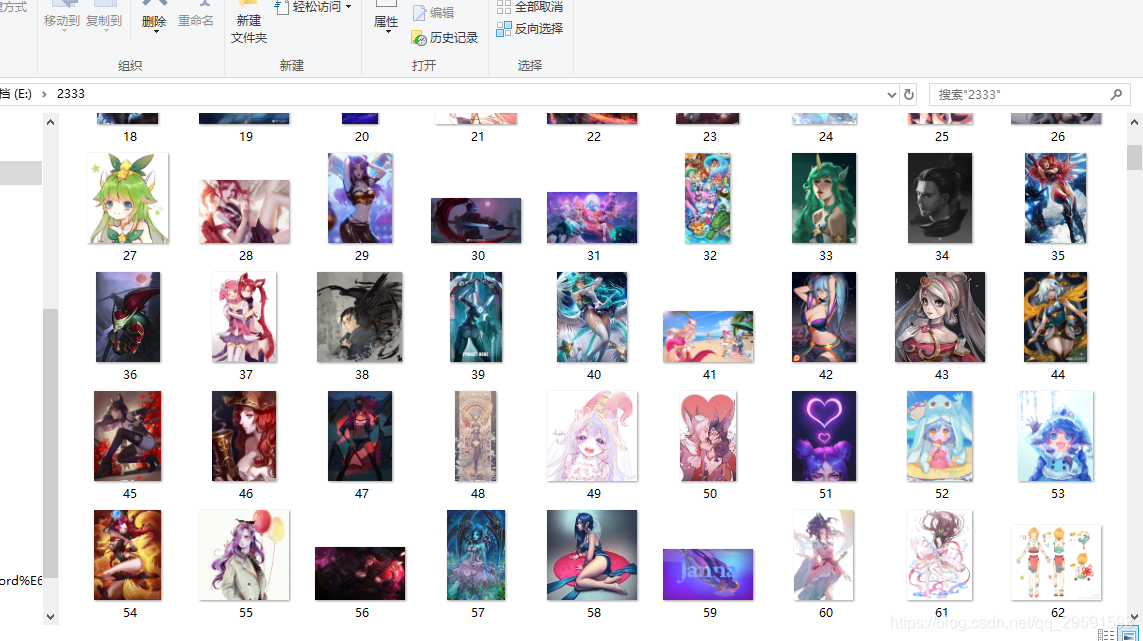
转载地址:https://blog.csdn.net/qq_29591593/article/details/86498027 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
做的很好,不错不错
[***.243.131.199]2024年03月28日 04时50分37秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
使用对象池优化性能
2019-04-27
Unity中的UI方案(基础版)
2019-04-27
Lua(一)——Lua介绍
2019-04-27
Lua(二)——环境安装
2019-04-27
Unity中父子物体的坑
2019-04-27
基础知识——进位制
2019-04-27
Lua(十二)——表
2019-04-27
Lua(十三)——模块与包
2019-04-27
Lua(四)——变量
2019-04-27
Lua(十四)——元表
2019-04-27
Lua(十五)——协同程序
2019-04-27
Lua(十六)——文件
2019-04-27
Lua(十七)——面向对象
2019-04-27
Lua(十八)——错误处理,垃圾回收
2019-04-27
xLua(一)——介绍
2019-04-27
xLua(二)——下载
2019-04-27
xLua(三)——在C#中访问Lua代码
2019-04-27
xLua(四)——C#访问Lua的基本类型
2019-04-27
xLua(五)——C#访问Lua的table
2019-04-27
xLua(六)——C#访问Lua的function
2019-04-27
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 307933677 位访客
访问时间: 2024-04-26 01:29:01
访问IP: 18.116.36.192
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版