http协议
 无链接:是指限制每次连接只处理一个请求,可节省传输时间 *****浏览器与服务器之间得连接过程都是短暂的,每次连接都处理一个请求和响应,对每一个页面的访问,浏览器与服务器之间都要建立一次单独的链接 *****浏览器到服务器之间的所有通讯都是完全分开的请求和响应对
无链接:是指限制每次连接只处理一个请求,可节省传输时间 *****浏览器与服务器之间得连接过程都是短暂的,每次连接都处理一个请求和响应,对每一个页面的访问,浏览器与服务器之间都要建立一次单独的链接 *****浏览器到服务器之间的所有通讯都是完全分开的请求和响应对 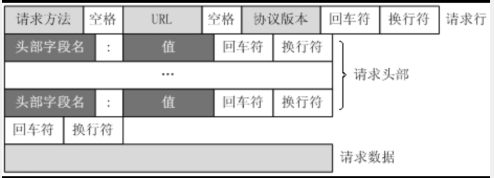
 响应报文(服务器响应消息): HTTP响应也由四个部分组成,分别是: 状态行 消息报头 空行 响应正文
响应报文(服务器响应消息): HTTP响应也由四个部分组成,分别是: 状态行 消息报头 空行 响应正文 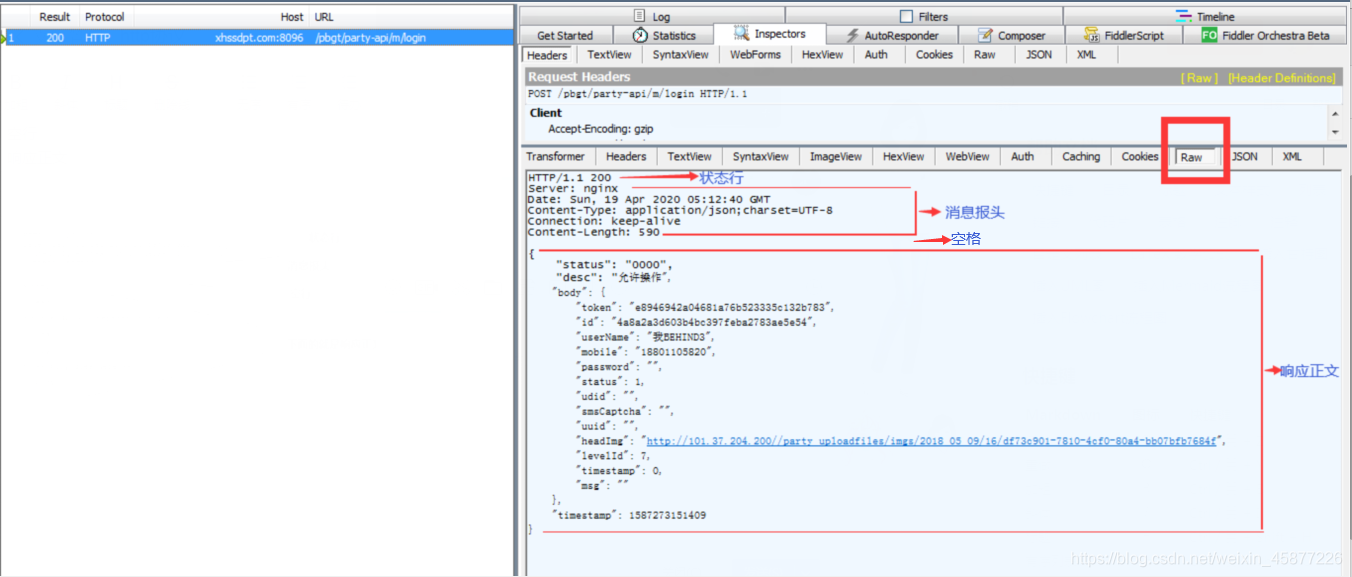
 四.Response 状态码信息 HTTP应答:状态行,消息报头,正文 1.状态码: 1xx 请求已接收,继续处理(服务器已经接收了这 个请求,继续处理) 2xx 请求成功 3xx 重定向,继续处理 4xx 客户端请求错误(403 Forbidden(使用 python 编写一个爬虫,频繁的去访问豆瓣,如果短时间内访问次数过多被豆瓣检查出来,那我们对外的ip就会被封掉,这时候无论我是使用浏览器还是使用其他的方式访问豆瓣,都会被403拒绝,可能要等上一天的时间/更多时间才能访问豆瓣)/404 NotFound(访问一个不存在的资源)/400 Bad Request) 5xx 服务端错误(服务器上发生未知的错误)
四.Response 状态码信息 HTTP应答:状态行,消息报头,正文 1.状态码: 1xx 请求已接收,继续处理(服务器已经接收了这 个请求,继续处理) 2xx 请求成功 3xx 重定向,继续处理 4xx 客户端请求错误(403 Forbidden(使用 python 编写一个爬虫,频繁的去访问豆瓣,如果短时间内访问次数过多被豆瓣检查出来,那我们对外的ip就会被封掉,这时候无论我是使用浏览器还是使用其他的方式访问豆瓣,都会被403拒绝,可能要等上一天的时间/更多时间才能访问豆瓣)/404 NotFound(访问一个不存在的资源)/400 Bad Request) 5xx 服务端错误(服务器上发生未知的错误) 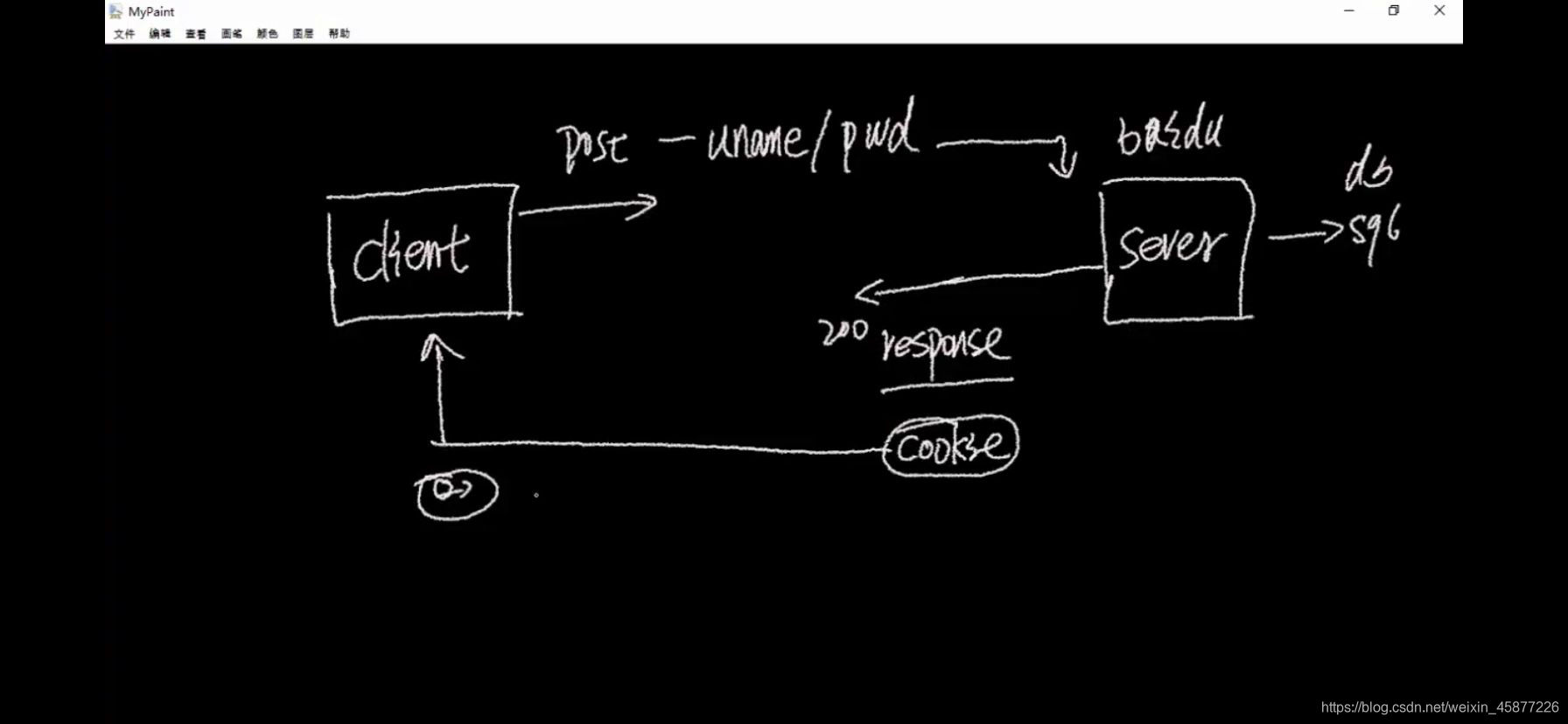
发布日期:2022-02-24 01:06:43
浏览次数:5
分类:技术文章
本文共 2166 字,大约阅读时间需要 7 分钟。
一.HTTP协议简介:
**HTTP:**超文本传输协议,客户端和服务器之间数据传输的协议(基于TCP/IP协议之上),(属于应用层的面向对象的协议,是一种详细规定了浏览器和万维网服务器之间互相通信的规则)
二.HTTP协议发展历程:
为什么有了HTTP2.0(只用于HTTPS://网址,又称为HTTP/2、HTTPS安全的协议即SSL)呢?
因为http协议是纯文本,无状态的协议纯文本: 客户端和服务器之间发送的报文信息我们可以直接就看到,一目了然(如登录的时候用户名和密码直接能看到就不安全了)
**无状态:**是指协议对于事物处理没有任何能力,缺少状态意味着如果后续处理需要前面的信息,则必须重传,这样可能导致每次连接传送的数据量增大
每次发的请求,服务器不能区分到底是不是同一个人发的(如想买东西,我第一次添加到购物车几个苹果手机,第二次添加到购物车里一个苹果电脑,通过http协议来实现的话,发了两个请求,由于http是无状态的,服务器就不知道这两个请求是不是一个人发的,因为向服务器发送请求有好多,不止我买东西,别人也买东西都是无状态就乱了,不知道是谁买的)三.HTTP协议的会话方式:
浏览器和服务器之间通信过程要经历四个步骤:
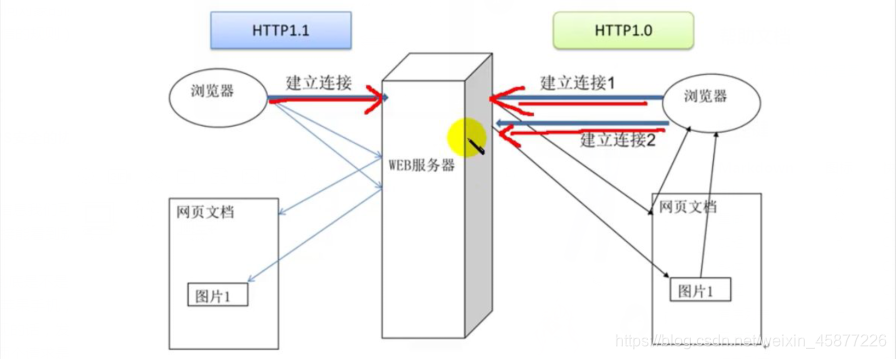
无链接:是指限制每次连接只处理一个请求,可节省传输时间 *****浏览器与服务器之间得连接过程都是短暂的,每次连接都处理一个请求和响应,对每一个页面的访问,浏览器与服务器之间都要建立一次单独的链接 *****浏览器到服务器之间的所有通讯都是完全分开的请求和响应对 四.HTTP1.0和HTTP1.1的区别:
提高了效率 在HTTP1.0版本中,浏览器请求一个带有图片的网页,会由于下载图片而与服务器之间开启一个新的连接,但在HTTP1.1版本中,允许浏览器在拿到当前请求对应的全部资源再断开连接,提高了效率 。(在这里1.0需要建立2次连接,1.1只需要建立1次连接)
五.报文:
**报文:**客户端与服务器之间通信传输的内容我们称之为报文
请求报文:客户端发送给服务器的叫请求报文 响应报文:服务器发送给客户端响应的叫响应报文 报文格式:
**服务器默认端口:**80(也可以改成其他的端口,如:8080等)
请求报文(客户端请求信息):
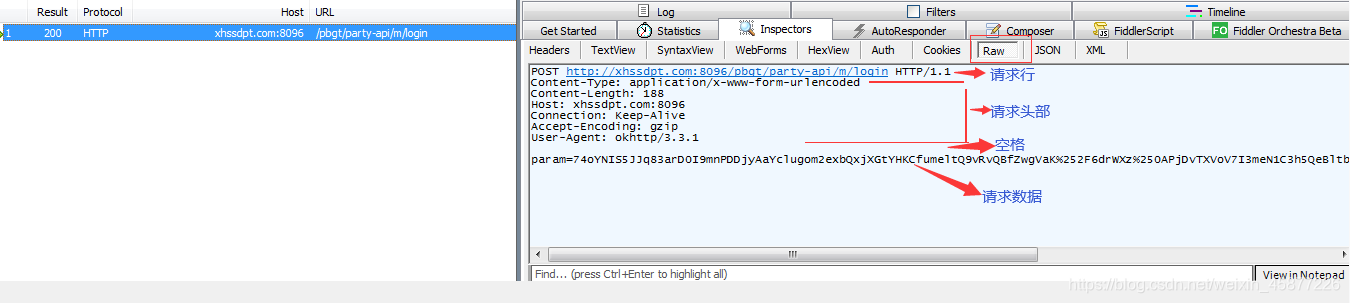
客户端发送一个HTTP请求到服务器的请求消息包含以下格式(四个部分): 请求行(request):请求方法 url 协议版本 请求头部(header):头部字段名 值 空行 请求数据 响应报文(服务器响应消息): HTTP响应也由四个部分组成,分别是: 状态行 消息报头 空行 响应正文 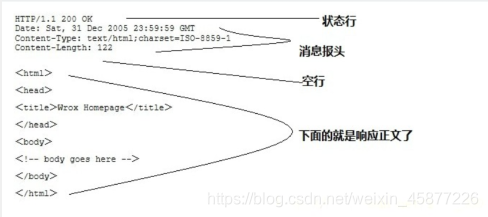
二.HTTP协议的方法:
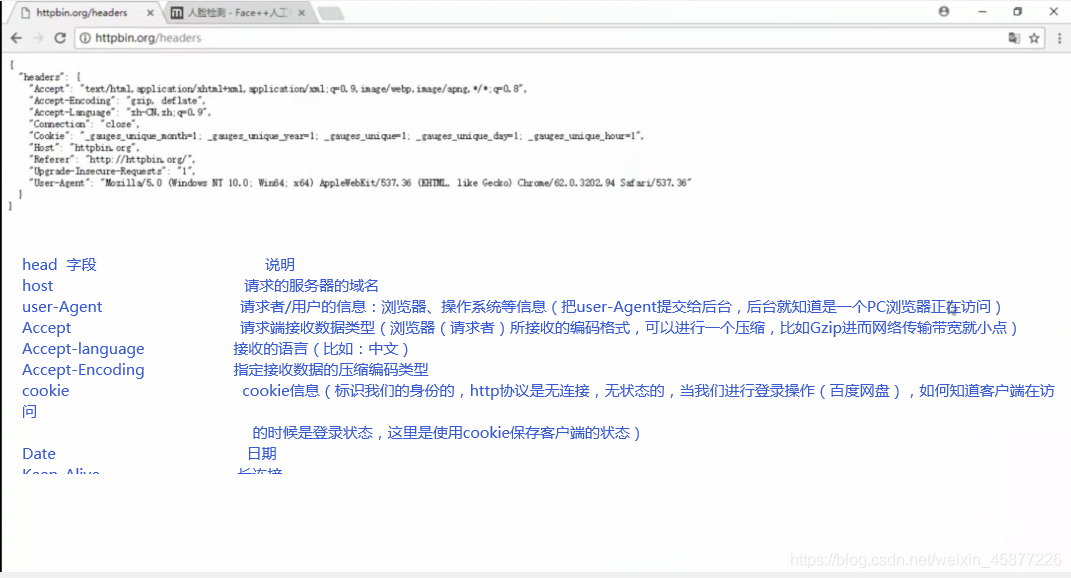
请求方法: 方法 说明 GET 请求资源 POST 提交表单/文件,可能修改服务器资源,如登录 PUT 更新资源 DELETE 删除指定资源 OPTIONS 获取服务器支持的http请求方法 检查服务器的性能 三.Request 头信息 四.Response 状态码信息 HTTP应答:状态行,消息报头,正文 1.状态码: 1xx 请求已接收,继续处理(服务器已经接收了这 个请求,继续处理) 2xx 请求成功 3xx 重定向,继续处理 4xx 客户端请求错误(403 Forbidden(使用 python 编写一个爬虫,频繁的去访问豆瓣,如果短时间内访问次数过多被豆瓣检查出来,那我们对外的ip就会被封掉,这时候无论我是使用浏览器还是使用其他的方式访问豆瓣,都会被403拒绝,可能要等上一天的时间/更多时间才能访问豆瓣)/404 NotFound(访问一个不存在的资源)/400 Bad Request) 5xx 服务端错误(服务器上发生未知的错误) 根据状态码判断请求的状态
1xx/3xx 我们继续请求 2xx 我们请求成功,如200 4xx /5xx 说明请求发生错误,这时候我们就结束当前 的请求 2.http应答Headers headers字段 说明 Content-Length 数据长度(服务器返回i给我们的客户端 数据的长度) Content-Type 传输内容格式 Content-Range 断点续传范围,例如:200-400/400 Set-Cookiecookie信息是记录客户端登录状态的,因为http协议是无连接无状态的,那我们的状态就是靠cookie
例如: 打开百度,进行百度帐号的登录,使用浏览器或者是python模块,首先要进行一个登录的操作,在百度的服务器是要有一个帐号和密码的,客户端发起一个post,提交表单(表单内容:uname,password)提交给服务器后,服务器会在自己的后台数据库中进行用户名和密码的校验,如果是校验成功,服务器应答一个200报文还设置了一个cookie信息,cookie信息给了客户端后,客户端就要把cookie信息保存住了,只有 把cookie信息保存住了,再次访问百度的时候,百度才知道,是已有的账户,已经进行了登录,有时候在访问一个网站的时,它下面会有个菜单栏提示:10天内自动登录,这个所租的事情就是将我们的这个网站的登录信息进行了保存,她在这里有一个时间戳超过10天会让你再次输入密码进行登录操作,这个实质就是使用的cookie。 转载地址:https://blog.csdn.net/weixin_45877226/article/details/105603221 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
路过,博主的博客真漂亮。。
[***.116.15.85]2024年04月07日 06时03分46秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
C实现bitmap位图
2021-06-28
中标麒麟等的RedHat系列Linux系统里如何卸载某个安装包对应的软件?
2021-06-28
关于bp神经网络的原理与自建研究以及计算结果。
2021-06-28
利用requests与Threading编写python多线程HTTP下载器
2021-06-28
HC_SR04超声波模块的应用
2021-06-28
TightVNC二次开发(1) 软件安装与测试
2021-06-28
TightVNC二次开发(2) Windows下使用VS2012编译服务器端和客户端
2021-06-28
小波C++库
2021-06-28
减佣还是返佣,外卖“佣金争议”背后的经济学
2021-06-28
解构荣耀销量奇迹背后的化学反应:技术+品质+产品力
2021-06-28
泰禾集团联席总裁葛勇:战“疫”于未然,文化筑居中国
2021-06-28
联想10年: 沽空不断,市值徘徊,10亿股先生为何叫不醒?
2021-06-28
年报发布后股价三连涨,神州租车何以成为 “方舱号”?
2021-06-28
CobaltStrike 部署
2021-06-28
Linux 安装 JAVA
2021-06-28
160.相交链表
2021-06-29
树莓派(Raspberry Pi)——利用原装摄像头实现简单圆形检测
2021-06-29
挑战程序设计竞赛(第2版)
2019-04-26
RabbitMQ集群及镜像配置部署详解
2019-04-26
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 305896023 位访客
访问时间: 2024-04-18 14:13:22
访问IP: 3.129.70.63
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版