ORM框架sqlalchemy介绍及基本操作
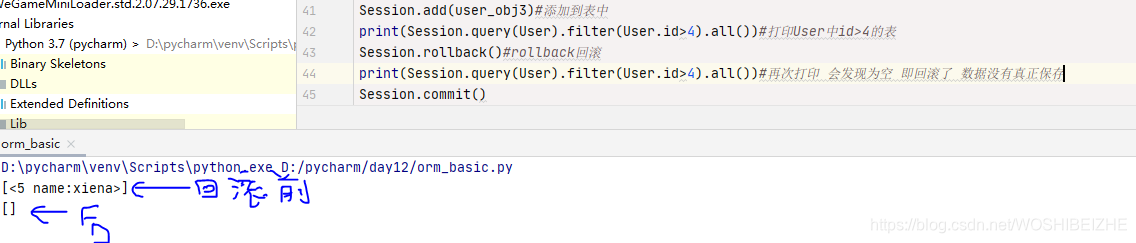 统计
统计 
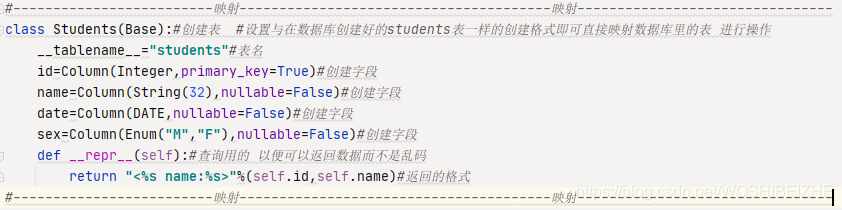 外键关联
外键关联 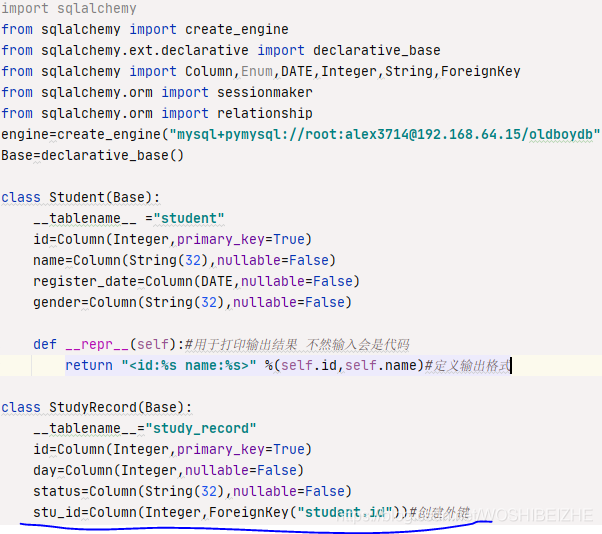
 美观简洁 我们在真实工作中,创建表结构应该是先在别的地方定义好表结构,再导入,要不然增删改查全在一起,太混乱了,我们创建一个新的py文件,然后第一句话导入 那个已经完善了结构的py文件,再实例化,就显得干净很多了
美观简洁 我们在真实工作中,创建表结构应该是先在别的地方定义好表结构,再导入,要不然增删改查全在一起,太混乱了,我们创建一个新的py文件,然后第一句话导入 那个已经完善了结构的py文件,再实例化,就显得干净很多了 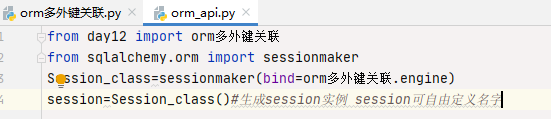 多外键关联 图代码为我创建的新例子,用于解释多外键关联,我定义了客户,及地址的两个表,客户定义了 id 名字 账单地址 跟送货地址 因为我们日常生活也遇到过,账单地址跟送货地址不同,地址则定义的是具体的地址
多外键关联 图代码为我创建的新例子,用于解释多外键关联,我定义了客户,及地址的两个表,客户定义了 id 名字 账单地址 跟送货地址 因为我们日常生活也遇到过,账单地址跟送货地址不同,地址则定义的是具体的地址 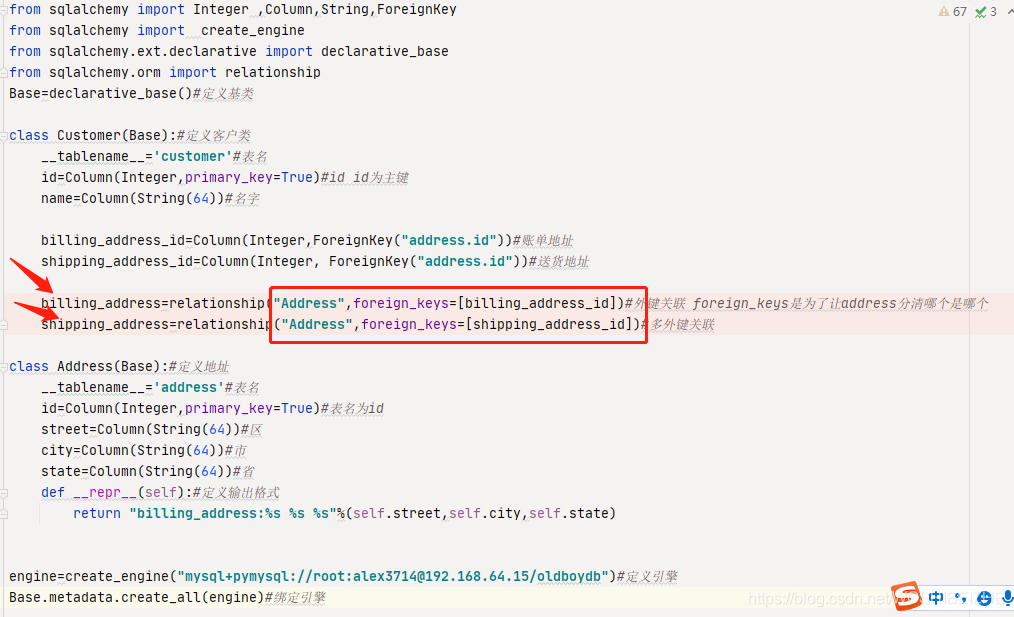 为了美观,将这些结构定义好之后,我们新创一个py文件进行增删改查之类的操作 只需要在新的from 导入即可
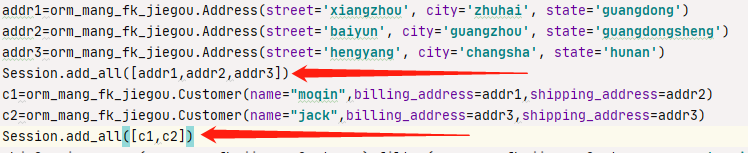
为了美观,将这些结构定义好之后,我们新创一个py文件进行增删改查之类的操作 只需要在新的from 导入即可  然后我们插入数据,我们先得插入address,因为customer客户这里 我们得先知道地址再能定义客户的数据,customer里要填账单地址,定义了address之后,我们customer就可以直接调用address的地址
然后我们插入数据,我们先得插入address,因为customer客户这里 我们得先知道地址再能定义客户的数据,customer里要填账单地址,定义了address之后,我们customer就可以直接调用address的地址 
 这是打印的结果
这是打印的结果 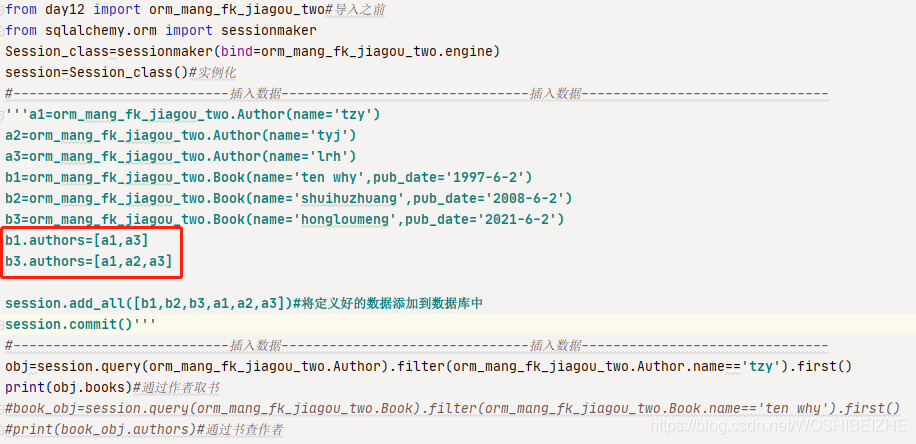 红框定义好之后,会添加到book_m2m_author这个表格之中,我们来数据库中看看 他的表是怎样的 如图 每本书对应每个作者名,当我们想去查书有几个作者时,或者作者写了几本书,就会来到这个表中里调对应的结果。
红框定义好之后,会添加到book_m2m_author这个表格之中,我们来数据库中看看 他的表是怎样的 如图 每本书对应每个作者名,当我们想去查书有几个作者时,或者作者写了几本书,就会来到这个表中里调对应的结果。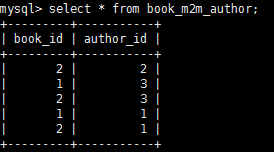 然后我们来通过作者查他写了几本书调用一下
然后我们来通过作者查他写了几本书调用一下  我这里设置的条件是Author作者表里name为tzy写了什么书,我们在打印的时候,这里是通过作者查他写了几本书.因为我们前面定义了蓝色下划线的方法现在直接在后面.books即可 调出他写的书,结果为两本书,我定义的 ten why及hongloumeng
我这里设置的条件是Author作者表里name为tzy写了什么书,我们在打印的时候,这里是通过作者查他写了几本书.因为我们前面定义了蓝色下划线的方法现在直接在后面.books即可 调出他写的书,结果为两本书,我定义的 ten why及hongloumeng  多对多删除 例如我们删除作者数据时,第三个表book_m2m_author会自动的把对应的数据删除, 例如我们想删除作者在某本书的名字如图所示 我们首先查找到这个作者写了什么书 然后查找我们想删除的书的作者有谁 然后remove(“输入第一个查找作者赋值的名”) 然后我们去数据库中查看第三个表时会发现同步的会将数据删除
多对多删除 例如我们删除作者数据时,第三个表book_m2m_author会自动的把对应的数据删除, 例如我们想删除作者在某本书的名字如图所示 我们首先查找到这个作者写了什么书 然后查找我们想删除的书的作者有谁 然后remove(“输入第一个查找作者赋值的名”) 然后我们去数据库中查看第三个表时会发现同步的会将数据删除  那要是我们想删除作者的话,选好之后直接delete
那要是我们想删除作者的话,选好之后直接delete 
发布日期:2022-03-02 13:23:43
浏览次数:34
分类:技术文章
本文共 3152 字,大约阅读时间需要 10 分钟。
前言
我们在学习mysql数据库中,很多字段都得重复操作,一个一个的打,例如select之类操作,也就表名跟字段还有where后的条件有区别,其他都大体一样,那么有没有专业的组件直接帮我们把原生sql封装好了,就意味着我们不用写sql语句,依然可以操作数据库,并以你喜欢的方式操作? ORM介绍 ORM就是对象映射关系程序,相当于把数据库也实例化了,这样我们在编程语言操作数据库时候,可以直接用编程语言对象模型进行操作,而不用sql语言优点:最直接的优点当然是我们不用像之前一样一个一个的打出来,使我们的数据库交互变得简单便捷
缺点:牺牲性能---------------下面我们来一起写一写orm操作------------------
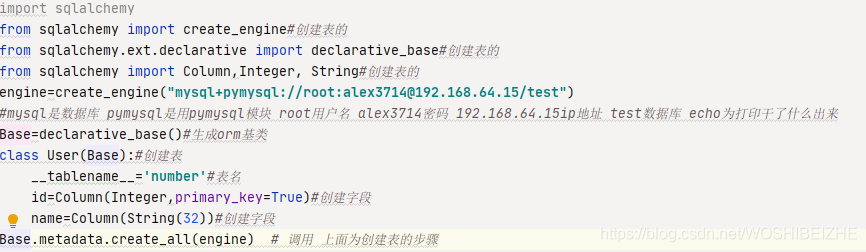
创建表下方为创建表的操作
下方为插入表数据的操作 并在顶端定义from sqlalchemy.orm import sessionmaker

查询表的操作 filter可以查询>< 并且filter查询里要加Userfilter_by可以查= 反正filter不行就用filter_by 英文筛选的意思也可以多条件查询.多加几个filter


先搜索出来要改的数据,然后下方直接定义新的数据 提交即可

统计 分组
图中代码为打印名字出现的字数 group_by(填需要统计的数据) 填User.name即打印名字出现的计算,填User.id 即id出现的次数

外键关联 这是绑定
外键关联,首先外键是用来关联两张表的,我们学习外键关联,先创建两张新的表 我这里创建的是学生及学生记录,通过蓝色下划线 我们就创建了关联两张表的外键 stu_id
在创建完后还必须输入下方第一句语句才创建结构到数据库中Session_class=csessionmaker(bind=engine)绑定数据库 开头有定义session=Session_class()为实例化 session可自己定义名字

插入数据
然后我们尝试导入数据到我们的两个表格中,将每个数据都写好之后,通过蓝色下划线代码导入到数据库中Session.add.all([xxxxx])

stu=session.query(表名).filter(表名.列名==“要找的数据”).first()first 即打印一条的意思 如果有两条会只打印一条 all()则打印所有

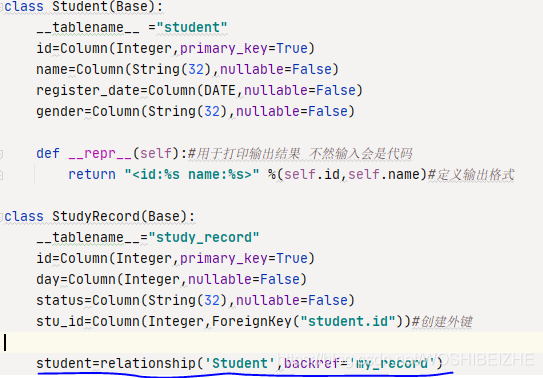
箭头为输出的定义格式,如果不定义会是乱码,由于定义了输出打印id跟name这样子我们看到了tanzhiyong的id是1,但是如果我们想看他的学习状态status怎么办,status又在另一张表上,
要想在上面普通查询print.加一个代码就可查询到另一张表信息可定义下方表名=relationship("关联表的类名",backref="自由定义")第一个表名输入 要关联的另一张表的名字 然后关联表的类名填class后的代码例如下方的调用Student里的tanzhiyong这个学生的status状态,status在study——record表中 则如图普通查询后面加.my_record 即可可以看到我们加了这么一点 就打印了tanzhiyong在study_record的表中所有每一天的状态 
注意打印的格式是按照return定义的
Studnet调StudyRecord则普通查询后方加.“backref里定义的字符串“” `StudyRecord调Student则普通查询很加蓝色下划线前的student 可自定义开头的名字 这里描述的很混乱 抱歉 美观简洁 我们在真实工作中,创建表结构应该是先在别的地方定义好表结构,再导入,要不然增删改查全在一起,太混乱了,我们创建一个新的py文件,然后第一句话导入 那个已经完善了结构的py文件,再实例化,就显得干净很多了 多外键关联 图代码为我创建的新例子,用于解释多外键关联,我定义了客户,及地址的两个表,客户定义了 id 名字 账单地址 跟送货地址 因为我们日常生活也遇到过,账单地址跟送货地址不同,地址则定义的是具体的地址 为了美观,将这些结构定义好之后,我们新创一个py文件进行增删改查之类的操作 只需要在新的from 导入即可 这是导入之前的在day12目录下写好的表结构py文件

然后实例化,就可以进行增删改查操作啦
然后我们插入数据,我们先得插入address,因为customer客户这里 我们得先知道地址再能定义客户的数据,customer里要填账单地址,定义了address之后,我们customer就可以直接调用address的地址 可以看到我们定义了三个地址,注意红箭头,我们先创建到数据库中,不然customer引用不到,然后我们在定义customer时就可以直接账单地址送货地址直接=上方定义好的 addr
这是打印的结果 多对多关联
学习了外键关联,可以互相调用,我们又学习了多外键关联,在上面账单送货地址实例中,多外键关联又实现了账单地址和送货地址分别关联地址类,那么我们再来学习最后一个关联“多对多关联”,我们还是举个例子来说,例如一本书可以有好几个作者,一个作者也可以有好几本书,那就用到多对多关联查询了 1.我们先定义author作者表 2.定义book书表 3.定义一个外键关联着 author及book的表 存放书对应的作者名蓝色下划线的意思:我想去查这个书谁是作者 就得通过secondary去查 book_m2m_author存放着书对应的作者
多对多关联 Book想通过书查作者的名字就.anthors Author想通过作者查书的名字就.books
首先我们为作者及书插入数据,注意红框内的是实现
b1这本书定义作者author为a1及a3 b3这本书定义作者为author为a1,a2,a3 红框定义好之后,会添加到book_m2m_author这个表格之中,我们来数据库中看看 他的表是怎样的 如图 每本书对应每个作者名,当我们想去查书有几个作者时,或者作者写了几本书,就会来到这个表中里调对应的结果。 然后我们来通过作者查他写了几本书调用一下 我这里设置的条件是Author作者表里name为tzy写了什么书,我们在打印的时候,这里是通过作者查他写了几本书.因为我们前面定义了蓝色下划线的方法现在直接在后面.books即可 调出他写的书,结果为两本书,我定义的 ten why及hongloumeng 多对多删除 例如我们删除作者数据时,第三个表book_m2m_author会自动的把对应的数据删除, 例如我们想删除作者在某本书的名字如图所示 我们首先查找到这个作者写了什么书 然后查找我们想删除的书的作者有谁 然后remove(“输入第一个查找作者赋值的名”) 然后我们去数据库中查看第三个表时会发现同步的会将数据删除 那要是我们想删除作者的话,选好之后直接delete 转载地址:https://blog.csdn.net/WOSHIBEIZHE/article/details/118179837 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关注你微信了!
[***.104.42.241]2024年03月27日 22时46分15秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
spring boot 与 Ant Design of Vue 实现新增用户(二十八)
2019-04-27
spring boot 与 Ant Design of Vue 实现修改用户(二十九)
2019-04-27
spring boot 与 Ant Design of Vue 实现删除用户(三十)
2019-04-27
Druid连接池实现自定义场景的多数据库的连接
2019-04-27
CentOs7命令行(静默)的方式安装oracle数据库
2019-04-27
基于VMware安装CentOs7的镜像
2019-04-27
PL/SQL数据库管理工具的使用
2019-04-27
史上最简单的spring-boot集成websocket的实现方式
2019-04-27
带你玩转属于自己的spring-boot-starter系列(一)
2019-04-27
带你玩转属于自己自己的spring-boot-starter系列(二)
2019-04-27
带你玩转属于自己的spring-boot-starter系列(三)
2019-04-27
基于SnowFlake算法如何让分库分表中不同的ID落在同一个库的算法的实现
2019-04-27
Linux文件管理参考
2019-04-27
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 307846620 位访客
访问时间: 2024-04-25 16:31:51
访问IP: 18.216.32.116
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版