pandas数据处理 笔记2
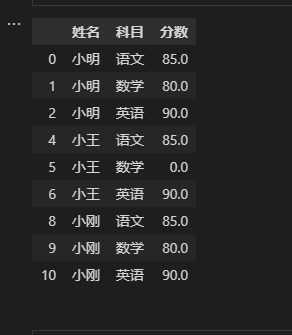 修改后的数据
修改后的数据
发布日期:2022-03-04 11:48:30
浏览次数:8
分类:技术文章
本文共 667 字,大约阅读时间需要 2 分钟。
导入所需要的库文件
import numpy as np
import pandas as pd读取excel
df=pd.read_excel(r’’,skiprows=2) # 因为数据有两行空值,需要跳过。
df.head()检测excel文件是否存在空值
df.isnull #is null/not null 用来检测空值,可用于df和series
df[“姓名”].isnull # 用来检测该列有没有空值空值的处理
df.dropna(how=“all”,axis=“columns”,inplace=True) # 将列全部为空值的列删去
df.dropna(how=“all”,axis=“rows”,inplace=True) # 将行方向全部为空值的删去 注意:inplace为true则修改当前的df,否则将返回新的df。 df.loc[:,“姓名”]=df[“姓名”].fillna(method=“ffill”) # 将姓名这一列中的空值,用ffill的方式填充。ffill:为取上一行的不为空的值填充空值,bfill:使用后一个不为空的值填充。 df.loc[:,“分数”]=df[“分数”].fillna(0)# 用0将分数这一列的空值填充 还有一种方法,等同于 df.fillna({“分数”:0})清洗后的数据存入到新的excel
df.to_excel(r’’,index=False) # 当index=false时,index这一列将不导入到excel中。
修改后的数据 转载地址:https://blog.csdn.net/xxy_yinji/article/details/119391196 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关注你微信了!
[***.104.42.241]2024年03月28日 23时13分22秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
Vue源码 阅读前必须知道 javascript 的基础内容
2019-04-26
剖析 Vue 原理 | 实现 双向绑定 MVVM
2019-04-26
丘比特射箭时为何要蒙上眼睛?
2019-04-26
ES6 一文弄懂 var let const 三剑客区别 吊打面试题
2019-04-26
ES6 面试题:你可以写出一百个 div 吗?一万个呢?
2019-04-26
ES6 在es6中自定义封装 jQuery
2019-04-26
ES5 中的 严格模式
2019-04-26
HNUCM-OJ Problem 1614 幸运数 模拟 最短子段和
2019-04-26
【前端干货】金三银四 我面了腾讯 分享面经/学习笔记/实习经历 (附视频讲解分享)
2019-04-26
【前端知识梳理】HTML篇 笔记整理(一)
2019-04-26
LeetCode 76. 最小覆盖子串 【滑动窗口】
2019-04-26
js 用几种方式实现继承(构造函数继承、原型链继承、组合方式继承)
2019-04-26
女朋友要我教她CSS,我就写了这一篇长文,感动哭了?
2019-04-26
LeetCode 69. x 的平方根 【二分查找】
2019-04-26
LeetCode 34. 在排序数组中查找元素的第一个和最后一个位置【二分查找】
2019-04-26
LeetCode 81. 搜索旋转排序数组 II【二分查找】
2019-04-26
hexo butterfly主题 添加全局吸底APlayer
2019-04-26
LeetCode 215. 数组中的第K个最大元素 【小顶堆与快速选择】
2019-04-26
LeetCode 347. 前 K 个高频元素【桶排序】
2019-04-26
LeetCode 695. 岛屿的最大面积【dfs】
2019-04-26
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 306241038 位访客
访问时间: 2024-04-19 16:30:10
访问IP: 3.138.122.4
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版