本文共 32809 字,大约阅读时间需要 109 分钟。
mysql常识
本文前面主要是对《mysql_5.5中文参考手册》部分内容的整理。
说明:登录mysql后,可以看到mysql> 的提示符,可以输入相关命令;输入命令后,需要以“;”号结束,否则会一直等待,少数的命令不需要“;”号,如QUIT;系统默认“;”号结束处才是一条命令的结束,才真正开始执行;多个短命令,可以放在一起,中间用“;”号隔开;我们也可借助外部工具,如navicat来管理数据为库,在navicat中单个查询命令也可以以“;”号结束,但在复杂查寻的内部,则不能有“;”号;可以将多条命令写在一个sql文件中,不同的命令之间用“;”号隔开,否则会出错,如下所示CREATE TABLE person (id SMALLINT UNSIGNED NOT NULL AUTO_INCREMENT,name CHAR(60) NOT NULL,PRIMARY KEY (id));create table shirt (id smallint unsigned not null auto_increment,style enum('t-shirt','polo','dress') not null,color enum('red','blue','orange','white','black') not null,owner smallint unsigned not null references person(id),primary key (id));insert into person values (null,'Antonio Paz');select @last:=last_insert_id();insert into shirt values (null,'polo','blue',@last),(null,'dress','white',@last),(null,'t-shirt','blue',@last);insert into person values (null,'Lilliana Angelovska');select @last:=last_insert_id();insert into shirt values (NULL, 'dress', 'orange', @last),(NULL, 'polo', 'red', @last),(NULL, 'dress', 'blue', @last),(NULL, 't-shirt', 'white', @last);select * from person;select s.* from person p,shirt s where p.name like 'Lilliana%' and s.owner=p.id and s.color !='white'; 然后使用source命令批量执行。
mysql中命令不区分大小写,但创建数据库的时候要注意大小写,大写的数据库名称,查询的时候用小写查不出来,同时也要与linux shell和python相区别,它们的编程是区分大小写的;
使用navicat将txt文本load进数据库出现乱码,首先查看txt文件是否是utf-8格式;然后在navicat中设置数据库属性,字符集选utf8mb4 – UTF-8 Unicode或utf8 – UTF-8 Unicode,排序规则选utf8mb4_general_ci或utf8_general_ci;mysql状态表:
| 提示符 | 含义 |
|---|---|
| mysql> | 准备好接受新的命令 |
| -> | 等待多选命令的下一行 |
| '> | 等待下一行,等待以单引号“'”开始的字符串的结束 |
| "> | 等待下一行,等待以双引号“"”号开始的字符串的结束 |
| `> | 等待下一行,等待以反斜点“`”号开始的字符串的结束 |
| /*> | 等待下一行,等待以/*号开始的注释的结束 |
mysql基本操作汇总
| 操作 | 代码 | 解释 |
|---|---|---|
| mysql连接 | mysql -h 主机名 -u mysql用户名 -p | 连接mysql通常需要提供用户名和密码,如果登录服务器之外的其他机器,还需要指定主机名称,运行后会提示输入密码,登录mysql后,会出现mysql>; windows下直接在命令行客户端输入密码则可以登录mysql的shell |
| mysql连接 | mysqldump: Got error: 2002: Can’t connect to local MySQL server through socket | 一是,修改mysql配置文件里的socket项的值为 '安装目/mysql.sock',不过这种方法需要重启mysql服务,很不厚道。二是,为/tmp/mysql.sock创建一个软链接到 '安装目录/mysql.sock':ln -s '安装目录/mysql.sock' /tmp/mysql.sock |
| 查看版本信息 | SELECT VERSION(); | 当前mysql版本信息 |
| 查看用户信息 | SELECT USER(); | |
| 断开mysql连接 | QUIT | linux下也可以按ctrl+D键断开连接 |
| 取消正在输入的语句 | \c | 回到mysql>命令等待状态 |
| 查看日期 | SELECT CURRENT_DATE; | mysql中日期是以2017-11-07为标准形式的,mysql有好一些对日期进行格式化及日期计算的函数 |
| 计算器 | 比如SELECT (4+1)*5; | 可以得到结果25 |
| 查看mysql中的数据库 | SHOW DATABASES; | 显示一列已存在的数据库名称 |
| 找出当前选择了哪个数据库 | SELECT DATABASE(); | |
| 选择某数据库 | USE 数据库名称; | 之后就可以对数据进行相关操作 |
| 创建数据库 | CREATE 数据库名称; | 注意数据库名称是区分大小写的,后续访问要与之相同;数据只要创建一次就行,刚创建的数据库是空的 |
| 显示数据库表 | SHOW TABLES; | |
| 创建数据库表 | CREATE TABLE PET (name VARCHAR(20),ower VARCHAR(20),species VARCHAR(20),sex CHAR(1),birth DATE,death DATE [,primary key(name ,ower )]) [engine=MYISAM,default charset=utf8]; | VARCHAR是可变字长,可以是1~65535中的任何一个,如果后面发现之前的设置不合理,可以使用ALTER TABLE来更改;[]部分表示可选,关于[Mysql 主键约束Primary Key](https://www.cnblogs.com/haodawang/p/5967222.html) |
| 创建数据库表 | CREATE TABLE | 通过default charset=gb2312 可用中文来命名字段,但实际上跟其他程序一起用的时候还是容易出问题 |
| 查看数据库表的结构信息 | DESCRIBE PET; | |
| 将数据装入数据库表 | LOAD DATA LOCAL INFILE '/path/pet.txt' INTO TABLE PET; | 如果是在window下,使用“\r\n”作为行结束符的,应该使用LOAD DATA LOCAL INFILE '/path/pet.txt' INTO TABLE PET LINES TERMINATED BY '\r\n';同时要注意txt文本的编码格式,有可能开关会多出一些字符 |
| 插入数据到数据库表 | INSERT INTO PET VALUES ("Buffy","Harold","dog","f","1989-05-13 ",null); | 在插入数据时,都需要用""号,但是空值时不能用""号,直接用null或\N都可以 |
| 操作 | 代码 | 解释 |
|---|---|---|
| 数据库中检索信息 | SELECT what_to_select FROM which_table WHERE conditions_to_satisfy; | 可以获取整个表,也可以只获取一部分字段,可以作用WHERE来筛选符合特定要求的数据,还可以用AND和OR对多个条件组合,可以用GROUP BY按某些字段分组,可以用ORDER BY按某字段排序;更复杂的条件需要逻辑运算的,通过()号将一部分运算结果作为一整体,另一部分运算结果用()作为一个整体,中间通过逻辑运算符连接;我们也查询到的列进行重命名 |
| 按条件查询 | select * from STUDENT HAVING STU_AGE in(11,12); | HAVING具有与where相同的效果,但是where是在获得查询结果前进行筛选,而HAVING是在获取查询结果后在结果中筛选,因而可以用在更复杂的情景中,比如HAVING可以order by 、group by等关键词之后,而where则在这些关键词之前 |
| 查询一个字段对应的多个值 | select * from STUDENT where STU_AGE in(11,12); | IN关键字可以判断某个字段的值是否在指定的集合中。如果字段的值在集合中,则满足查询条件,该纪录将被查询出来。如果不在集合中,则不满足查询条件。 |
| 按范围查询 | 用between 值1 and 值2,或大于and小于 | 虽然几乎所有的数据库都支持 BETWEEN ... AND 运算符,但不同的数据库对 BETWEEN ... AND 处理方式是有差异的。在 MySQL 中,BETWEEN 包含了 value1 和 value2 边界值,如上面选取 uid 在 2 到 5 之间的用户数据例子。而有的数据库则不包含 value1 和 value2 边界值(类似于大于 and 小于),也有数据库包含 value1 而不包含 value2(类似于 大于等于 and小于)。所以在使用 BETWEEN ... AND 的时候,请检查你的数据库是如何处理 BETWEEN 边界值的。 |
| 查询唯一值 | SELECT DISTINCT what_to_select FROM which_table WHERE conditions_to_satisfy; | 选出符合条件的记录并去重,其实通过group by 也能达到 去重的目的,有的时候更方便更好控制结果按自己想要的方式呈现 |
| 从某一行开始查询 | select * from table_name limit 第几行,行数; | 第几行是从0开始的,即0代表第一行 |
| 读取最后几行 | select * from table_name order by id desc limit 第几行,行数; | |
| 排序 | SELECT name, species, birth FROM pet ORDER BY species, birth DESC; | DESC表示按降序排序结果, order by 多个条件时,先按第一个条件排再按第二个条件排 |
| 复合查询 | SELECT * FROM (SELECT name, species, birth FROM pet)AS TABLE1 ORDER BY species, birth DESC; | DESC表示按降序排序结果, order by 多个条件时,先按第一个条件排再按第二个条件排 |
| 删除表中数据 | DELETE FROM which_table; | 和标准的SQL语句不同,DELETE支持ORDER BY和LIMIT子句,通过这两个子句,我们可以更好地控制要删除的记录。如当我们只想删除WHERE子句过滤出来的记录的一部分,可以使用LIMIB,如果要删除后几条记录,可以通过ORDER BY和LIMIT配合使用。假设我们要删除users表中name等于"Mike"的前6条记录。可以使用如下的DELETE语句:DELETE FROM users WHERE name = 'Mike' LIMIT 6;一般MySQL并不确定删除的这6条记录是哪6条,为了更保险,我们可以使用ORDER BY对记录进行排序。DELETE FROM users WHERE name = 'Mike' ORDER BY id DESC LIMIT 6; |
| 修改数据 | UPDATE pet SET DEATH="1999-09-12" WHERE NAME="Claws";UPDATE temp_id_area SET SF = CONCAT(split(SF,'市',1),'市') WHERE LOCATE('市',SF); UPDATE temp_id_area SET SF = CONCAT(split(SF,'地区',1),'地区') WHERE LOCATE('地区',SF); UPDATE temp_id_area SET SF = CONCAT(split(SF,'自治区',1),'自治区') WHERE LOCATE('自治区',SF); UPDATE temp_id_area SET SF = CONCAT(split(SF,'省',1),'省') WHERE LOCATE('省',SF); UPDATE temp_id_area SET SFBM = SUBSTR(SSBM,1,2); | |
| 时间与日期 | SELECT CURRENT_DATE;或SELECT CURDATE(); | 获取当前日期 |
| 获取日期的年、月、日 | SELECT YEAR(CURDATE());SELECT MONTH(CURRENT_DATE);SELECT DAY(CURRENT_DATE); | CURRENT_DATE也可以换成其他日期格式的数据;也可以用取模的方式来间接获取月份,如SELECT MOD(CURDATE(),12);但注意,此时的范围是0-11,因而如果是12月份要加1 |
| 加上时间隔 | SELECT DATE_ADD(CURDATE(),INTERVAL 1 MONTH); | 假如当前日期是2017-11-07,得到的结果将是2017-12-07 |
| null操作 | 使用IS NULL或IS NOT NULL来作为判断; | mysql中null表示空,没有值,null不能与用算术比较符操作;在GROUP BY中,两个null视为相同;执行ORDER BY ,null排在最前面,加上DESC则排在最后面 |
| 标准SQL模式匹配 | 使用LIKE或NOT LIKE,而不能使用=或!= | mysql提供标准的SQL模式匹配,以及基于像linux实用程序vi,grep,sed的正则表达式模式匹配,在mysql中模式默认忽略大小写 |
| “_” | 匹配任何单个字符 | |
| "%" | 匹配任意数目字符,包括零字符 | |
| 扩展正则表达式 | REGEXP或NOT REGEXP或RLIKE或NOT RLIKE | 为了定位一个模式,以便匹配被测试值的开始或结束,以"^"在模型的开头,表示匹配以某模式开始的记录;以"$"在模式的结尾,表示匹配以某模式结束的记录;要想使用regexp来强制区分大小写需要使其中一个字符转换为二进制字符 |
| '.' | 匹配任意单个的字符 | |
| "[XXX]" | 匹配在方括号内的任意字符,如"[abc]"匹配"a"或"b"或"c";"[a-z]"匹配任何字母,因为mysql不区分大小写;"[0-9]"匹配任何数字 | |
| "*" | 匹配一个或任意多个出现在它前面的字符,如"x*"匹配任意数量的x,"[0-9]*"匹配任何数量数字,".*"匹配任何数量的任意字符 | |
| 要想找出以“b”开头的名字 | SELECT * FROM PET WHERE name LIKE 'b%'; | SELECT * FROM PET WHERE name REGEXP '^b'; |
| 要想找出以“b”开头的名字,只要小写b开头的 | SELECT * FROM PET WHERE name REGEXP BINARY '^b'; | |
| 要想找出以“fy”结尾的名字 | SELECT * FROM PET WHERE name LIKE '%fy'; | SELECT * FROM PET WHERE name REGEXP 'fy$'; |
| 要想找出包含“w”的名字 | SELECT * FROM PET WHERE name LIKE '%w%'; | SELECT * FROM PET WHERE name REGEXP 'W'; |
| 要想找出正好包含5个字符的名字,使用“_”模式字符 | SELECT * FROM PET WHERE name LIKE '_____'; | SELECT * FROM PET WHERE name REGEXP '^.....$'; 或者用.{5}代替5个点 |
| 计数 | SELECT COUNT(*) FROM PET ;SELECT COUNT(*) FROM PET GROUP BY SEX ; | 使用计数如果不需要检索整个表,应该用where来限定范围提高效率 |
| 最大值 | MAX() | (请注意,MIN和MAX函数会忽略NULL值) |
| 最小值 | MIN() | (请注意,MIN和MAX函数会忽略NULL值) |
| 平均值 | AVG() | |
| 求和 | SUM() | 以上几个都需要配合group by使用 |
| 使用一个以上的表 | SELECT pet.name,event.remark FROM pet,event where pet.name =event.name AND event.type='little'; | FROM子句列出两个表,因为查询需要从两个表提取信息。当从多个表组合(联结)信息时,你需要指定一个表中的记录怎样能匹配其它表的记录。这很简单,因为它们都有一个name列。查询使用WHERE子句基于name值来匹配2个表中的记录。因为name列出现在两个表中,当引用列时,你一定要指定哪个表。把表名附在列名前即可以实现 |
| 一个表的记录与同一个表的其它记录进行比较 | SELECT p1.*,p2.* FROM pet as p1,pet as p2 WHERE p1.species = p2.species AND p1.sex = 'f' AND p2.sex = 'm'; | |
| 批量运行 | mysql> source filename ; | filename 中的多条sql语句末尾一定要加上“;”号,否则出错 |
创建表时生成数据插入或修改时间
MYSQL 数据乱码和字符集问题
MySQL的字符集问题
关于MySQL的字符集问题更详细可
MySQL的字符集支持(Character Set Support)有两个方面: 字符集(Character set)和排序方式(Collation)。 对于字符集的支持细化到四个层次: 服务器(server),数据库(database),数据表(table)和连接(connection)。MySQL默认字符集
MySQL对于字符集的指定可以细化到一个数据库,一张表,一列,应该用什么字符集。
但是,传统的程序在创建数据库和数据表时并没有使用那么复杂的配置,它们用的是默认的配置,那么,默认的配置从何而来呢? (1)编译MySQL 时,指定了一个默认的字符集,这个字符集是 latin1; (2)安装MySQL 时,可以在配置文件 (my.cnf) 中指定一个默认的的字符集,如果没指定,这个值继承自编译时指定的; (3)启动mysqld 时,可以在命令行参数中指定一个默认的的字符集,如果没指定,这个值继承自配置文件中的配置,此时 character_set_server 被设定为这个默认的字符集; (4)当创建一个新的数据库时,除非明确指定,这个数据库的字符集被缺省设定为character_set_server; (5)当选定了一个数据库时,character_set_database 被设定为这个数据库默认的字符集; (6)在这个数据库里创建一张表时,表默认的字符集被设定为 character_set_database,也就是这个数据库默认的字符集; (7)当在表内设置一栏时,除非明确指定,否则此栏缺省的字符集就是表默认的字符集; 简单的总结一下,如果什么地方都不修改,那么所有的数据库的所有表的所有栏位的都用 latin1 存储,不过我们如果安装 MySQL,一般都会选择多语言支持,也就是说,安装程序会自动在配置文件中把 default_character_set 设置为 UTF-8,这保证了缺省情况下,所有的数据库的所有表的所有栏位的都用 UTF-8 存储。查看默认字符集
(默认情况下,mysql的字符集是latin1(ISO_8859_1)
通常,查看系统的字符集和排序方式的设定可以通过下面的两条命令:show variables like 'character%';
结果如下:
+--------------------------+----------------------------+| Variable_name | Value |+--------------------------+----------------------------+| character_set_client | utf8 || character_set_connection | utf8 || character_set_database | latin1 || character_set_filesystem | binary || character_set_results | utf8 || character_set_server | latin1 || character_set_system | utf8 || character_sets_dir | /usr/share/mysql/charsets/ |+--------------------------+----------------------------+
show variables like 'collation%'
结果如下:
+----------------------+-------------------+| Variable_name | Value |+----------------------+-------------------+| collation_connection | utf8_general_ci || collation_database | latin1_swedish_ci || collation_server | latin1_swedish_ci |+----------------------+-------------------+
MySQL中涉及的几个字符集解释:
character_set_server/default_character_set:服务器字符集,默认情况下所采用的。 character_set_database:数据库字符集。 character_set_table:数据库表字符集。 优先级依次增加。所以一般情况下只需要设置character_set_server,而在创建数据库和表时不特别指定字符集,这样统一采用character_set_server字符集。 character_set_client:客户端的字符集。客户端默认字符集。当客户端向服务器发送请求时,请求以该字符集进行编码。 character_set_results:结果字符集。服务器向客户端返回结果或者信息时,结果以该字符集进行编码。 在客户端,如果没有定义character_set_results,则采用character_set_client字符集作为默认的字符集。所以只需要设置character_set_client字符集。 要处理中文,则可以将character_set_server和character_set_client均设置为GB2312,如果要同时处理多国语言,则设置为UTF8。修改默认字符集
(1) 最简单的修改方法,就是修改mysql的my.cnf文件中的字符集键值,一般情况下my.cnfd在/etc文件夹下。如果没有可以自己创建该文件。并添加如下内容:(还没验证)
default_character_set = utf8character_set_server = utf8
修改完后,重启mysql的服务,service mysql restart
mysql> SHOW VARIABLES LIKE 'character%';查看,发现数据库编码均已改成utf8 (2) 还有一种修改字符集的方法,就是使用mysql的命令 在登录数据库时,我们用mysql --default-character-set=字符集-u root -p进行连接,这时我们再用show variables like '%char%';命令查看字符集设置情况,可以发现客户端、数据库连接、查询结果的字符集已经设置成登录时选择的字符集了; 如果是已经登录了,可以使用set names 字符集;命令来实现上述效果,等同于下面的命令: mysql> set character_set_client=utf8;mysql> set character_set_connection=utf8;mysql> set character_set_database=utf8;mysql> set character_set_results=utf8;mysql> set character_set_server=utf8;mysql> set character_set_system=utf8;mysql> set collation_connection=utf8;mysql> set collation_database=utf8;mysql> set collation_server=utf8;
(3)其他的一些设置方法:
修改数据库的字符集mysql>use mydbmysql>alter database mydb character set utf-8;
创建数据库指定数据库的字符集
mysql>create database mydb character set utf-8;
mysql中文乱码问题
解决乱码的方法是,在执行SQL语句之前,将MySQL以下三个系统参数设置为与服务器字符集character-set-server相同的字符集。
character_set_client:客户端的字符集。 character_set_results:结果字符集。 character_set_connection:连接字符集。 关于编码格式GBK、GB2312、UTF8 UTF- 8:Unicode Transformation Format-8bit,允许含BOM,但通常不含BOM。是用以解决国际上字符的一种多字节编码,它对英文使用8位(即一个字节),中文使用24为(三个字节)来编码。UTF-8包含全世界所有国家需要用到的字符,是国际编码,通用性强。UTF-8编码的文字可以在各国支持UTF8字符集的浏览器上显示。如,如果是UTF8编码,则在外国人的英文IE上也能显示中文,他们无需下载IE的中文语言支持包。GBK是国家标准GB2312基础上扩容后兼容GB2312的标准。GBK的文字编码是用双字节来表示的,即不论中、英文字符均使用双字节来表示,为了区分中文,将其最高位都设定成1。GBK包含全部中文字符,是国家编码,通用性比UTF8差,不过UTF8占用的数据库比GBD大。
GBK、GB2312等与UTF8之间都必须通过Unicode编码才能相互转换:
GBK、GB2312--Unicode--UTF8 UTF8--Unicode--GBK、GB2312对于一个网站、论坛来说,如果英文字符较多,则建议使用UTF-8节省空间。不过现在很多论坛的插件一般只支持GBK。
GB2312是GBK的子集,GBK是GB18030的子集
GBK是包括中日韩字符的大字符集合 如果是中文的网站 推荐GB2312 GBK有时还是有点问题 为了避免所有乱码问题,应该采用UTF-8,将来要支持国际化也非常方便 UTF-8可以看作是大字符集,它包含了大部分文字的编码。 使用UTF-8的一个好处是其他地区的用户(如香港台湾)无需安装简体中文支持就能正常观看你的文字而不会出现乱码。gb2312是简体中文的码
gbk支持简体中文及繁体中文 big5支持繁体中文 utf-8支持几乎所有字符解决方法
首先分析乱码的情况
1.写入数据库时作为乱码写入 2.查询结果以乱码返回 究竟在发生乱码时是哪一种情况呢? 我们先在mysql 命令行下输入 show variables like ‘%char%’; 查看mysql 字符集设置情况: 文件系统字符集是固定的,系统、服务器的字符集在安装时确定,与乱码问题无关;乱码的问题与客户端、数据库连接、数据库、查询结果的字符集设置有关。 *注:客户端是看访问mysql 数据库的方式,通过命令行访问,命令行窗口就是客户端,通过JDBC 等连接访问,程序就是客户端。 我们在向mysql 写入中文数据时,在客户端、数据库连接、写入数据库时分别要进行编码转换在执行查询时,在返回结果、数据库连接、客户端分别进行编码转换。现在我们应该清楚,乱码发生在数据库、客户端、查询结果以及数据库连接这其中一个或多个环节。为什么从命令行直接写入中文不设置也不会出现乱码?可以明确的是从命令行下,客户端、数据库连接、查询结果的字符集设置没有变化输入的中文经过一系列转码又转回初始的字符集,我们查看到的当然不是乱码但这并不代表中文在数据库里被正确作为中文字符存储举例来说,现在有一个utf8 编码数据库,客户端连接使用GBK 编码,connection 使用默认的ISO8859-1(也就是mysql 中的latin1),我们在客户端发送“中文”这个字符串,客户端将发送一串GBK 格式的二进制码给connection 层,connection 层以ISO8859-1 格式将这段二进制码发送给数据库,数据库将这段编码以utf8 格式存储下来,我们将这个字段以utf8格式读取出来,肯定是得到乱码,也就是说中文数据在写入数据库时是以乱码形式存储的,在同一个客户端进行查询操作时,做了一套和写入时相反的操作,错误的utf8 格式二进制码又被转换成正确的GBK 码并正确显示出来。
我们可以通过之前讲的方法来设置相应的字符集。通过这样的设置,整个数据写入读出流程中都统一了字符集,就不会出现乱码了。
如果是通过JDBC 连接数据库,可以这样写URL:URL=jdbc:mysql://localhost:3306/abs?useUnicode=true&characterEncoding=字符集,JSP 页面等终端也要设置相应的字符集。 R连接mysql乱码问题
在R读入mysql数据库出现中文乱码,首先确保mysql数据库中字符集编码格式为utf-8;然后在本地电脑上(windows系统)的数据源设置中(控制面板–管理工具–数据源–配置–detail)设置好对应mysql数据库连接的字符集编码为utf-8,然后在R中channel_temp=odbcConnect(“数据库连接的名称”,uid =“xx” ,pwd =“xx”,DBMSencoding=“UTF-8”),指定编码,则不会出现乱码。
mysq NULL值替换 将mysql数据库中的NULL值替换为空 UPDATEqrt_order_info SET order_num=’’ WHERE order_num=“NULL”; 原本在数据库的NULL是被当成字符串了,不同的语言,表示空的方法都不一样,mysql中是"\N";所有可以在加载数据前,对NULL作替换,这样一次性导入后就自动为空,而不需要像上面那样去数据库里UPDATE了。 mysql内NULL判断的是空,就是没有任何值,此时用navicat查看的时候可以看淡灰色的"(Null)"字样;有时会在数据库记录的某一栏看不到任务记录,此时未必是NULL,有可能是空字符,’’,只不过字符串里没任何内容,此时要用where xx=’’; python操作MYSQL 数据库
通过pymysql操作MYSQL 数据库
该部分来源、,关于防sql注入可参考。
PyMysql是在Python3.x版本中用于连接mysql服务器的一个库,在python2中使用mysqldb; 安转好pymysql库后,按照如下方式使用:执行sql语句前需要获取cursor,因为配置默认自动提交,故在执行sql语句后需要主动commit,最后不要忘记关闭连接。 1、创建连接import pymysql# Connect to the databaseconnection = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='zhyea.com', db='employees', charset='utf8mb4', cursorclass=pymysql.cursors.DictCursor)
也可以使用字典进行连接参数的管理,这样子更优雅一些:
import pymysqlconfig = { 'host':'127.0.0.1', 'port':3306, 'user':'root', 'password':'zhyea.com', 'db':'employees', 'charset':'utf8mb4', 'cursorclass':pymysql.cursors.DictCursor, } # Connect to the databaseconnection = pymysql.connect(**config) #host根据实际情况填写,如果集群在局域网,填写局域网ip地址即可。charset填写mysql中的编码格式。 **2、使用cursor()方法获取游标对象 **
cursor= db.cursor() 3、使用execute() 方法执行SQL操作 查询数据库可用cursor.execute("select version()")#该操作可直接获取查询结果 也可以进一步使用fetchone()方法获取单条数据 ,该方法获取下一个查询结果集,结果集是一个对象
data1=cursor.fetchone()
使用fetchmany(n)方法获取n条数据,
使用fetchall()方法获取多条数据,接收全部的返回结果行 rowcount:一个只读属性,并返回执行execute()方法后的影响行数 删除表操作cursor.execute("drop table if exists t") 使用预处理语句创建表
sql = """create table t(id int,name varchar(10)) engine=innodb charset utf8""" cursor.execute(sql)
插入操作
sql = """insert into t(id,name) values(1,'china')""" with connection.cursor() as cursor: # 执行sql语句,插入记录 sql = 'INSERT INTO employees (first_name, last_name, hire_date, gender, birth_date) VALUES (%s, %s, %s, %s, %s)' cursor.execute(sql, ('Robin', 'Zhyea', tomorrow, 'M', date(1989, 6, 14))); 更新数据库
sql = "UPDATE device_init_stats SET device_stats=0,device_stats_temp = 0,vol_meter='%s',time_meter='%s',leaks_end=1,instantaneous_delivery='%s',levels_risk=0 where path='%s'" % (vol_cur,time_cur,instantaneous_delivery,path)cursor.execute(sql)
4、提交SQL操作
connection.commit()# 没有设置默认自动提交,需要主动提交,以保存所执行的语句
如果存在多次,不管commit()是放在for循环里面还是外面,都能将全部记录插入到该表中
注意执行效率的问题,如果每个循环都提交会很慢,但放在for循环外面一次性提交效率与**executemany()**相似。详情可 5、关闭连接connection.close();
6、完整的例子
import pymysql#连接配置信息config = { 'host':'127.0.0.1', 'port':3306, 'user':'root', 'password':'zhyea.com', 'db':'employees', 'charset':'utf8mb4', 'cursorclass':pymysql.cursors.DictCursor, }# 创建连接connection = pymysql.connect(**config)# 获取明天的时间tomorrow = datetime.now().date() + timedelta(days=1)# 执行sql语句try: with connection.cursor() as cursor: # 执行sql语句,插入记录 sql = 'INSERT INTO employees (first_name, last_name, hire_date, gender, birth_date) VALUES (%s, %s, %s, %s, %s)' cursor.execute(sql, ('Robin', 'Zhyea', tomorrow, 'M', date(1989, 6, 14))); # 没有设置默认自动提交,需要主动提交,以保存所执行的语句 connection.commit()finally: connection.close(); 7、执行事务
事务机制可以确保数据的一致性 事务有四个属性:原子,一致,隔离,持久型;通常称为ACID Python DB API 2.0 的事务提供了两个方法 commit 或 rollback 比如#使用预处理语句创建表sql = """insert into t(id,name) values(1,'china')"""try: # 执行sql cursor.execute(sql) # 提交到数据库执行 db.commit()except: # 如果发生错误 db.rollback()
对于支持事务的数据库,在python数据库编程中,当游标建立之时,就自动开始了一个隐形的数据库事务,这个区别于mysql客户端。
commit()方法提交所有的事务,rollback()方法回滚当前游标的所有操作。每个方法都开启了一个新的事务。 8、错误处理 DB API中定义了一些数据库操作的错误及异常 异常 描述 Warning 当有严重警告时触发,例如插入数据是被截断等等。必须是 StandardError 的子类。 Error 警告以外所有其他错误类。必须是 StandardError 的子类。 InterfaceError 当有数据库接口模块本身的错误(而不是数据库的错误)发生时触发。 必须是Error的子类。 DatabaseError 和数据库有关的错误发生时触发。 必须是Error的子类。 DataError 当有数据处理时的错误发生时触发,例如:除零错误,数据超范围等等。 必须是DatabaseError的子类。 OperationalError 指非用户控制的,而是操作数据库时发生的错误。例如:连接意外断开、 数据库名未找到、事务处理失败、 内存分配错误等等操作数据库是发生的错误。 必须是DatabaseError的子类。 IntegrityError 完整性相关的错误,例如外键检查失败等。必须是DatabaseError子类。 InternalError 数据库的内部错误,例如游标(cursor)失效了、事务同步失败等等。 必须是DatabaseError子类。 ProgrammingError 程序错误,例如数据表(table)没找到或已存在、SQL语句语法错误、 参数数量错误等等。必须是DatabaseError的子类。 NotSupportedError 不支持错误,指使用了数据库不支持的函数或API等。例如在连接对象上 使用.rollback()函数, 然而数据库并不支持事务或者事务已关闭。 必须是DatabaseError的子类Python数据库连接池——PooledDB
通过pandas.read_sql操作MYSQL 数据库
sql = "select * from water_outlier where path='%s' and hour_perday='%s'" % (path,hour_cur)device_outlier = pd.read_sql(sql, con=connection)if device_outlier.empty == True: print('没有相关的记录信息!') continuevol_L=device_outlier['vol_L'][0]print('当前值为vol_L=%s m³/h'%(vol_L)) 上面的con=connection可直接使用4.1中pymysql中的connection。
使用pandas.read_sql读取数据的好处是读入的数据是dataframe,就可以直接使用dataframe的很多方法和属性。对于数据的定位,统计等都比较方便。spark连接mysql数据库
1、将mysql-connector-java-5.1.22-bin.jar文件放入/opt/spark/lib/文件夹内(放到别的文件夹也可)
2、修改spark-env.sh文件 加入:export SPARK_CLASSPATH=/opt/spark/lib/mysql-connector-java-5.1.22-bin.jar:$SPARK_CLASSPATH
3、spark程序实例
from pyspark import SparkContext from pyspark.sql import SQLContext import sys #solve the UnicodeEncodeError reload(sys) sys.setdefaultencoding('utf8') if __name__ == "__main__": sc = SparkContext(appName="mysqltest") sqlContext = SQLContext(sc) df = sqlContext.read.format("jdbc").options(url="jdbc:mysql://202.117.16.203\ :3306/logstat?user=shelly&password=123456",dbtable="lms_levels").load() df.show() sc.stop() 常见错误
1、
错误: 原因: 利用pandas读取mysql数据库,如果返回为空则出现此错误 解决方法: 利用if (df.empty)==True来进行处理 2、 错误: ‘numpy.float64’ object has no attribute ‘translate’ Inserting value to Mysql in Python 原因: 因为python中默认的浮点型数据可能是float64,与mysql中不一致,导致数据无法写入mysql 解决方法: 利用float()进行类型转换java操作MYSQL 数据库
新建java项目 然后新建一个文件夹——libs(用来放各种外部包) 在包里面加入连接mysql数据库的包 如mysql-connector-java-8.0.11.jar 将下载的复制粘贴到我们的java项目的libs文件下面 右键工程名,点出build path中的configure build path,然后在java build path中的Libraries分页中选择Add JARs…,选择刚才添加的JDBC,如下图: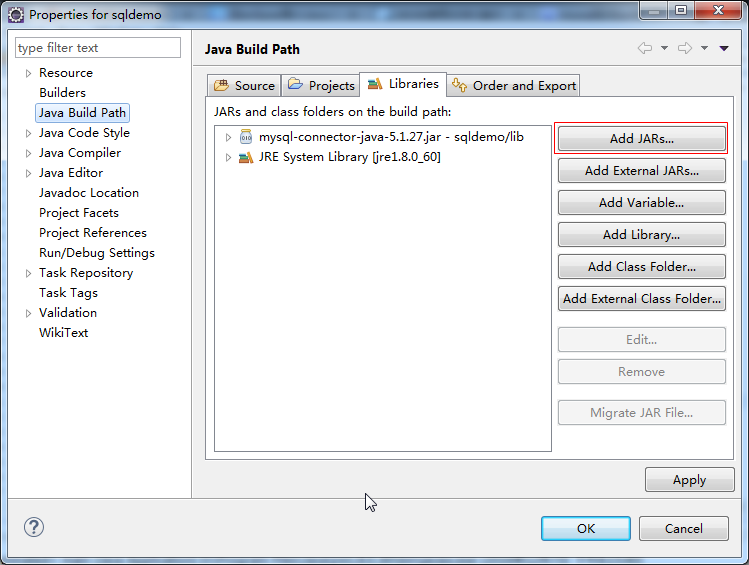 数据包准备: 在数据库sqltestdb中创建如下数据表emp:
数据包准备: 在数据库sqltestdb中创建如下数据表emp: CREATE TABLE emp( empno INT(4) PRIMARY KEY, ename VARCHAR(10), job VARCHAR(9), hiredate DATE, sal FLOAT(7,2)) ;
添加数据:
 连接数据库并读取数据: 数据库名称:sqltestdb 数据包名称:emp 端口号:3306 用户名:root 密码:root
连接数据库并读取数据: 数据库名称:sqltestdb 数据包名称:emp 端口号:3306 用户名:root 密码:root package sqldemo;import java.sql.Connection;import java.sql.DriverManager;import java.sql.ResultSet;import java.sql.SQLException;import java.sql.Statement;public class main { public static void main(String[] args) { //声明Connection对象 Connection con; //驱动程序名 String driver = "com.mysql.jdbc.Driver"; //URL指向要访问的数据库名mydata String url = "jdbc:mysql://localhost:3306/sqltestdb"; //MySQL配置时的用户名 String user = "root"; //MySQL配置时的密码 String password = "123456"; //遍历查询结果集 try { //加载驱动程序 Class.forName(driver); //1.getConnection()方法,连接MySQL数据库!! con = DriverManager.getConnection(url,user,password); if(!con.isClosed()) System.out.println("Succeeded connecting to the Database!"); //2.创建statement类对象,用来执行SQL语句!! Statement statement = con.createStatement(); //要执行的SQL语句 String sql = "select * from emp"; //3.ResultSet类,用来存放获取的结果集!! ResultSet rs = statement.executeQuery(sql); System.out.println("-----------------"); System.out.println("执行结果如下所示:"); System.out.println("-----------------"); System.out.println("姓名" + "\t" + "职称"); System.out.println("-----------------"); String job = null; String id = null; while(rs.next()){ //获取stuname这列数据 job = rs.getString("job"); //获取stuid这列数据 id = rs.getString("ename"); //输出结果 System.out.println(id + "\t" + job); } rs.close(); con.close(); } catch(ClassNotFoundException e) { //数据库驱动类异常处理 System.out.println("Sorry,can`t find the Driver!"); e.printStackTrace(); } catch(SQLException e) { //数据库连接失败异常处理 e.printStackTrace(); }catch (Exception e) { // TODO: handle exception e.printStackTrace(); }finally{ System.out.println("数据库数据成功获取!!"); } }} 运行结果:
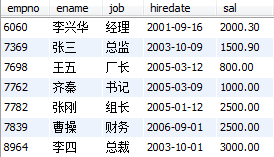
Succeeded connecting to the Database!-----------------执行结果如下所示:-----------------姓名 职称-----------------李兴华 经理张三 总监王五 厂长齐秦 书记张刚 组长曹操 财务李四 总裁数据库数据成功获取!!
增加、删除和修改数据:
增加数据:
String name;String id; PreparedStatement psql;ResultSet res;//预处理添加数据,其中有两个参数--“?”psql = con.prepareStatement("insert into emp (empno,ename,job,hiredate,sal) " + "values(?,?,?,?,?)");psql.setInt(1, 3212); //设置参数1,创建id为3212的数据psql.setString(2, "王刚"); //设置参数2,name 为王刚psql.setString(3, "总裁"); DateFormat dateFormat2 = new SimpleDateFormat("yyyy-MM-dd");Date myDate2 = dateFormat2.parse("2010-09-13");psql.setDate(4,new java.sql.Date(myDate2.getTime()));psql.setFloat(5, (float) 2000.3);psql.executeUpdate(); //执行更新 MYSQL 数据导入导出
MySQL数据导出
数据表导出:
在navicat中直接导出已存在的数据表,导出格式很多,最常用的导出格式是.sql,.excel; 查询结果导出: navicat中查询结果也是可以直接导出的,不用再复制粘贴了。linux下查询结果可通过如下方式导出:
在已连接数据库情况下,select * from edu_iclass_areas into outfile 'test.xls' #这里需要绝对路径 但可能遇到用户权限问题,而无法写成功。 也可以采用下面的方式来输出文件。 mysql -h 主机 -u 用户 -p密码 -P端口 -D库 -Bse “select house_id,type from 表名 where account_id=123;” > /tmp/a.txt
使用命令导出:
window下 1.导出整个数据库 mysqldump -u 用户名 -p 数据库名 > 导出的文件名mysqldump -u dbuser -p dbname > dbname.sql
2.导出一个表
mysqldump -u 用户名 -p 数据库名 表名> 导出的文件名mysqldump -u dbuser -p dbname users> dbname_users.sql
3.导出一个数据库结构
mysqldump -u dbuser -p -d --add-drop-table dbname >d:/dbname_db.sql-d 没有数据 --add-drop-table 在每个create语句之前增加一个drop table
linux下
一、导出数据库用mysqldump命令(注意mysql的安装路径,即此命令的路径): 1、导出数据和表结构: mysqldump -u用户名 -p密码 数据库名 > 数据库名.sql#/usr/local/mysql/bin/ mysqldump -uroot -p abc > abc.sql
敲回车后会提示输入密码
2、只导出表结构 mysqldump -u用户名 -p密码 -d 数据库名 > 数据库名.sql#/usr/local/mysql/bin/ mysqldump -uroot -p -d abc > abc.sql
注:/usr/local/mysql/bin/ —> mysql的data目录
linux下更详细的mysql数据导出可,还是比较详细的。MySQL数据导入
关于批量导入数据到mysql数据库,首先可以从数据库导出批量文件,有多种格式,如excel,txt或sql;对于txt文件后期可以利用load导入其他数据库,但出要先创建数据库,如下面的命令所示,在navicat中使用load,文件名中不能有中文;对于sql文件,它导出得到的是包含一系列insert 语句的文件,有的会包含类似下面的完整命令,此时直接在navicat中运行该.sql文件即可;如果是在mysql的shell里直接运行的话,可用source *.sql。
DROP TABLE IF EXISTS `temp_integrated`;CREATE TABLE `temp_integrated` ( `cust_code` varchar(32) NOT NULL COMMENT 'xx', `cust_name` varchar(32) DEFAULT NULL COMMENT 'xx', `id_card_no` varchar(32) DEFAULT NULL COMMENT 'xx', `province` varchar(32) DEFAULT NULL COMMENT 'xx', `cust_add` varchar(32) DEFAULT NULL COMMENT 'xx', `county` varchar(32) DEFAULT NULL COMMENT 'xx') ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;INSERT INTO temp_integrated VALUES ('xxx', 'xx','xx', 'xx', 'xx', 'xx'); mysql将一张表的查询结果存到另一张表中
由于mysql不支持select into 方法,mysql怎样将一张表的查询结果存到另一张表中?
找了两个方法 第一种:create table dust select * from student;//用于复制前未创建新表dust的情况下 第二种 insert into dust select * from student;//已经创建了新表dust的情况下 类别一、 如果两张张表(导出表和目标表)的字段一致,并且希望插入全部数据,可以用这种方法: INSERT INTO 目标表 SELECT * FROM 来源表 ;
类别二、 如果只希望导入指定字段,可以用这种方法:
INSERT INTO 目标表 (字段1, 字段2, ...) SELECT 字段1, 字段2, ... FROM 来源表 ;
请注意以上两表的字段必须一致,否则会出现数据转换错误。
mysql数据库备份
MySQL中的函数
MySQL中的内置函数
| 函数名 | 用途 | 举例 | 解释 |
|---|---|---|---|
| abs(N) | 返回N的绝对值 | select ABS(-32); | 32 |
| sign(N) | 返回参数的符号(为-1、0或1) | select SIGN(-32);select SIGN(0); | -10 |
| mod(N,M) | 取模运算,返回N被M除的余数(同%操作符) | select MOD(234, 10); | 4 |
| floor(N) | 返回不大于N的最大整数值 | select FLOOR(-1.23); | -2 |
| ceiling(N) | 返回不小于N的最小整数值 | select CEILING(1.23); | 2 |
| round(N, D) | 返回N的四舍五入值,保留D位小数(D的默认值为0) | select ROUND(-1.23); | -1 |
| exp(N) | 返回值e的N次方(自然对数的底) | select EXP(2); | 7.389056 |
| log(N) | 返回N的自然对数 | select LOG(2); | 0.693147 |
| pow(X,Y)或power(X,Y) | 返回值X的Y次幂 | select POW(2,2); | 4 |
| sqrt(N) | 返回非负数N的平方根 | select SQRT(4); | 2 |
| pi() | 返回圆周率 | select PI(); | 3.141593 |
| cos(N) | 返回N的余弦值 | select COS(PI()); | -1.000000 |
| sin(N) | 返回N的正弦值 | select SIN(PI()); | 0.000000 |
| tan(N) | 返回N的正切值 | select TAN(PI()+1); | 1.557408 |
| acos(N) | 返回N反余弦(N是余弦值,在-1到1的范围,否则返回NULL) | select ACOS(1); | |
| asin(N | 返回N反正弦值 | select ASIN(0.2); | 0.201358 |
| atan(N) | 返回N的反正切值 | select ATAN(2); | 1.107149 |
| atan2(X,Y) | 返回2个变量X和Y的反正切(类似Y/X的反正切,符号决定象限) | select ATAN(-2,2); | -0.785398 |
| cot(N) | 返回X的余切 | select COT(12); | -1.57267341 |
| RAND() | 返回在范围0到1.0内的随机浮点值(可以使用数字N作为初始值) | select RAND(); | 0.5925 |
| degrees(N) | 把N从弧度变换为角度并返回 | select DEGREES(PI()); | 180.000000 |
| radians(N) | 把N从角度变换为弧度并返回 | select RADIANS(90); | 1.570796 |
| truncate(N,D) | 保留数字N的D位小数并返回 | select TRUNCATE(1.223,1); | 1.2 |
| least(X,Y,...) | 返回最小值(如果返回值被用在整数(实数或大小敏感字串)上下文或所有参数都是整数(实数或大小敏感字串)则他们作为整数(实数或大小敏感字串)比较,否则按忽略大小写的字符串被比较) | select LEAST(2,0); | 0 |
| greatest(X,Y,...) | 返回最大值(其余同LEAST()) | select GREATEST(2,0);select GREATEST("B","A","C"); | 2"C" |
| STD | 估算总体方差,根号内除以n,对应excel函数:STDEVP | select STD(字段名) from 数据表; | |
| STDDEV_SAMP | 即估算样本方差,根号内除以(n-1),对应excel函数:STDEV | select STD(字段名) from 数据表; |
MySQL中自定义函数
mysql中可以通过自定义函数来完成一些功能。
新建一个函数: 语法结构:Create function function_name(参数列表)returns返回值类型函数体
函数名,应该合法的标识符,并且不应该与已有的关键字冲突。
一个函数应该属于某个数据库,可以使用db_name.funciton_name的形式执行当前函数所属数据库,否则为当前数据库。 参数部分,由参数名和参数类型组成。 返回值类类型 函数体由多条可用的mysql语句,流程控制,变量声明等语句构成。 多条语句应该使用begin end语句块包含。在给变量赋值时一定要使用set …… 注意,一定要有return返回值语句。#下面的程序自定义了一个分割字符串的函数,参数f_string为待分割的字符串,f_delimiter参数为定义的分割字符,参数f_order为从分割好的字符串数组中取第几个值;#mysql中默认的命令分隔符为;号,当遇到;号时就要执行命令,这里自定义了$$为命令分隔符,这样后面的不同命令之间就可以使用$$分隔,与;不同的是,它不需立即执行,可以等到所有的命令读取完毕后再由mysql解释器一次性执行DELIMITER $$ DROP function IF EXISTS `func_splitString` $$ CREATE FUNCTION `func_splitString` ( f_string varchar(1000),f_delimiter varchar(5),f_order int) RETURNS varchar(255) CHARSET utf8 BEGIN declare result varchar(255) default ''; set result = reverse(substring_index(reverse(substring_index(f_string,f_delimiter,f_order)),f_delimiter,1)); return result; END$$
上面函数的使用方法,先运行该函数,这样函数就会存在mysql所在计算机的内存中,这样其他命令就可以像调用内置函数一样调用该函数,如下:
SELECT func_splitString('a,b,c',',','2') 将得到结果b
变量
如上,使用set varX=XXX
用户变量(@)和系统变量(@@)MySQL存储过程的创建
语法:
CREATE PROCEDURE 过程名([[IN|OUT|INOUT] 参数名 数据类型[,[IN|OUT|INOUT] 参数名 数据类型…]]) [特性 ...] 过程体DELIMITER // CREATE PROCEDURE myproc(OUT s int) BEGIN SELECT COUNT(*) INTO s FROM students; END //DELIMITER ;
分隔符:
MySQL默认以";“为分隔符,如果没有声明分割符,则编译器会把存储过程当成SQL语句进行处理,因此编译过程会报错,所以要事先用“DELIMITER //”声明当前段分隔符,让编译器把两个”//"之间的内容当做存储过程的代码,不会执行这些代码;“DELIMITER ;”的意为把分隔符还原。
参数:
存储过程根据需要可能会有输入、输出、输入输出参数,如果有多个参数用","分割开。MySQL存储过程的参数用在存储过程的定义,共有三种参数类型,IN,OUT,INOUT:
IN参数的值必须在调用存储过程时指定,在存储过程中修改该参数的值不能被返回,为默认值 OUT:该值可在存储过程内部被改变,并可返回 INOUT:调用时指定,并且可被改变和返回过程体:
过程体的开始与结束使用BEGIN与END进行标识。
条件语句IF-THEN-ELSE语句:
#条件语句IF-THEN-ELSEDROP PROCEDURE IF EXISTS proc3;DELIMITER //CREATE PROCEDURE proc3(IN parameter int) BEGIN DECLARE var int; SET var=parameter+1; IF var=0 THEN INSERT INTO t VALUES (17); END IF ; IF parameter=0 THEN UPDATE t SET s1=s1+1; ELSE UPDATE t SET s1=s1+2; END IF ; END ; //DELIMITER ;
下面是一个往表格中插入行的例子
#条件语句IF-THEN-ELSEDROP PROCEDURE IF EXISTS proc3;DELIMITER //CREATE PROCEDURE proc3(IN date_string varchar(32)) BEGIN IF MONTH(date_string)=12 THEN INSERT INTO temp_month_interval VALUES( CONCAT(year(CURDATE()),'11','01'),CONCAT(year(CURDATE()),'11','30'),CONCAT(year(CURDATE()),'11','01'),CONCAT(year(CURDATE()),'11','30'), CONCAT(year(CURDATE()),'10','01'),CONCAT(year(CURDATE()),'10','31'),CONCAT(year(CURDATE()),'10','01'),CONCAT(year(CURDATE()),'10','31'), CONCAT(year(CURDATE()),'09','01'),CONCAT(year(CURDATE()),'09','30'),CONCAT(year(CURDATE()),'09','01'),CONCAT(year(CURDATE()),'09','30'), CONCAT(year(CURDATE()),'08','01'),CONCAT(year(CURDATE()),'08','31'),CONCAT(year(CURDATE()),'08','01'),CONCAT(year(CURDATE()),'08','31'), CONCAT(year(CURDATE()),'07','01'),CONCAT(year(CURDATE()),'07','31'),CONCAT(year(CURDATE()),'07','01'),CONCAT(year(CURDATE()),'07','31'), CONCAT(year(CURDATE()),'06','01'),CONCAT(year(CURDATE()),'06','30'),CONCAT(year(CURDATE()),'06','01'),CONCAT(year(CURDATE()),'06','30')); ELSE INSERT INTO temp_month_interval VALUES( CONCAT(year(CURDATE()),'11','01'),CONCAT(year(CURDATE()),'11','30'),CONCAT(year(CURDATE()),'11','01'),CONCAT(year(CURDATE()),'11','30'), CONCAT(year(CURDATE()),'10','01'),CONCAT(year(CURDATE()),'10','31'),CONCAT(year(CURDATE()),'10','01'),CONCAT(year(CURDATE()),'10','31'), CONCAT(year(CURDATE()),'09','01'),CONCAT(year(CURDATE()),'09','30'),CONCAT(year(CURDATE()),'09','01'),CONCAT(year(CURDATE()),'09','30'), CONCAT(year(CURDATE()),'08','01'),CONCAT(year(CURDATE()),'08','31'),CONCAT(year(CURDATE()),'08','01'),CONCAT(year(CURDATE()),'08','31'), CONCAT(year(CURDATE()),'07','01'),CONCAT(year(CURDATE()),'07','31'),CONCAT(year(CURDATE()),'07','01'),CONCAT(year(CURDATE()),'07','31'), CONCAT(year(CURDATE()),'06','01'),CONCAT(year(CURDATE()),'06','30'),CONCAT(year(CURDATE()),'06','01'),CONCAT(year(CURDATE()),'06','30')); END IF ; END ; //DELIMITER ;
调用过程:
call proc3(CURDATE())
这样表里的数据就得到更新。
存储过程的更详细信息可查阅MySQL性能提升
能先用where 缩减查询范围先缩减
此条对运行速度影响最大
先想清楚要实现的功能,尽量在查询一个表的时候完成
多生成一些新的字段都没关系,对性能影响不大,但反复查询就很影响性能
少自己创建函数
调用自己创建的函数速度很慢
MySQL数据库访问并发数和数据库访问过大时性能优化
跨数据库操作
在表的前面加上数据进行限定,如select * from 库.表 where …MySql赋值操作符"=“与”:="
“:=” 是真正意义上的赋值操作,左边的变量设置为右边的值。
“=” 则只在两种情况下作为赋值用,第一种就是在SET语句里面,SET var = value; 另一种是在UPDATE语句里面的那个SET,如update table_name set column_name where…。除了方面这两种情况外"="则作为比较操作符使用。
判断库或表是否存在
如何判断mysql数据库中是否存在某张表
方法1、 DROP TABLE IF EXISTS tablename;
方法2、 做一个sql查询,比如:select * from tablename/select count(*) from tablename,如果返回值为空,则表不存在。 方法3、 查询:SHOW TABLES LIKE table1,判断返回值。如: if(mysql_num_rows(mysql_query(“SHOW TABLES LIKE '”.$table."’")==1) { echo “Table exists”; } else { echo “Table does not exist”; } 方法4、 CREATE TABLE IF NOT EXISTSyourdb.yourtable (…) mysql判断数据库是否存在
(1) 判断数据库存在, 则删除:
drop database if exists db_name; (2) 如果单纯显示是否存在数据库, 则可用: show databases like ‘db_name’;MYSQL之水平分区----MySQL partition分区
mysql插入float类型数据问题
float类型可以存浮点数(即小数类型),但是float有个缺点的,当不指定小数位数的时候,那么它就会出现小数位数与想要的不一致。
所以在创建浮点类型的时候应该指定小数位数,float(m,d),m表示的是最大长度,d表示的显示的小数位数。 需要注意的是如果插入的数小数后位数不够,多余的位将随机补值,而不是补0,这一点很意外。MySQL5.7 添加用户、删除用户与授权
mysql -uroot -proot
MySQL5.7 mysql.user表没有password字段改 authentication_string; 一. 创建用户:命令:CREATE USER 'username'@'host' IDENTIFIED BY 'password';
PS:username -你将创建的用户名,
host指定该用户在哪个主机上可以登陆,此处的"localhost",是指该用户只能在本地登录,不能在另外一台机器上远程登录,如果想远程登录的话,将"localhost"改为"%",表示在任何一台电脑上都可以登录;也可以指定某台机器可以远程登录; password- 该用户的登陆密码,密码可以为空,如果为空则该用户可以不需要密码登陆服务器。 修改用户密码 更改用户名密码,官方推荐使用alter ALTER USER test@'%' IDENTIFIED BY '123456';
还有一种
update mysql.user set authentication_string=password("新密码") where User="test" and Host="localhost"; 用update语句需要flush privileges;
上面两种方法都不行,最后使用 SET PASSWORD = PASSWORD(‘123456’);二.授权:
命令:GRANT privileges ON databasename.tablename TO 'username'@'host'
PS: privileges- 用户的操作权限,如SELECT , INSERT , UPDATE 等(详细列表见该文最后面).如果要授予所的权限则使用ALL.;databasename- 数据库名,tablename-表名,如果要授予该用户对所有数据库和表的相应操作权限则可用*表示, 如*.*.
mysql> flush privileges;
PS:必须执行flush privileges;
否则登录时提示:ERROR 1045 (28000): Access denied for user ‘user’@‘localhost’ (using password: YES )
之后可以使用mysql -utest -p #测试是否创建成功
详情
正常创建用户失效的问题 就是没有刷新权限,才导致了这问题。 删除用户@>mysql -u root -p @>密码 mysql>Delete FROM user Where User='test' and Host='localhost'; mysql>flush privileges; mysql>drop database testDB; //删除用户的数据库删除账户及权限:>drop user 用户名@'%'; >drop user 用户名@ localhost;
修改mysql数据表
mysql中一些计算
Mysql 相邻两行记录某列的差值
在oracle中,有
但mysql中没有lag和lead函数,可以如下实现:某列记录占该列总和的比值
select AAA,AAA/(select sum(AAA) from dbdbdb.BBB) as ratioA from dbdbdb.BBB
mysql行转列
mysql主从高可用
可参考《虚拟机装linux系统》转载地址:https://blog.csdn.net/qingqing7/article/details/78465858 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
