本文共 16750 字,大约阅读时间需要 55 分钟。
mysql的john用法总结
左”的笛卡尔积和“右”的笛卡尔积
根据mysql join 连接的方式我把它归为两类,“左”的笛卡尔积和“右”的笛卡尔积。
假设有两个表A和B,分别有m行和n行 1、“左”的笛卡尔积就是我们通常的笛卡尔积,也就A的所有元素依次连接B的第一个元素,然后A的所有元素依次连接B的第二个元素,依此类推,这样最终得到的表就有m*n行;“左”的笛卡尔积有Inner join、Left join、Cross join(除了right join外的都是) 下面具体说明,我们先创建两个表create table tbl_name (ID int,mSize varchar(100));insert into tbl_name values(1,'tiny,small,big');insert into tbl_name values(2,'small,medium');insert into tbl_name values(3,'tiny,big');
结果如下tbl_name :
| ID | mSize |
|---|---|
| 1 | tiny,small,big |
| 2 | small,medium |
| 3 | tiny,big |
第二个表
create table incre_table (AutoIncreID int);insert into incre_table values(1);insert into incre_table values(2);insert into incre_table values(3);
如果如下incre_table :
| AutoIncreID |
|---|
| 1 |
| 2 |
| 3 |
先看Inner join
select * from tbl_name aINNER JOIN incre_table b
运行结果如下:
| ID | mSize | AutoIncreID |
|---|---|---|
| 1 | tiny,small,big | 1 |
| 2 | small,medium | 1 |
| 3 | tiny,big | 1 |
| 1 | tiny,small,big | 2 |
| 2 | small,medium | 2 |
| 3 | tiny,big | 2 |
| 1 | tiny,small,big | 3 |
| 2 | small,medium | 3 |
| 3 | tiny,big | 3 |
再看Left join
select * from tbl_name aLEFT JOIN incre_table bon 1=1
说明,left join和right join都必须有on条件,其他连接可以选择不写on条件,这里用on 1=1,使所有结果满足要求,结果如下:
| ID | mSize | AutoIncreID |
|---|---|---|
| 1 | tiny,small,big | 1 |
| 2 | small,medium | 1 |
| 3 | tiny,big | 1 |
| 1 | tiny,small,big | 2 |
| 2 | small,medium | 2 |
| 3 | tiny,big | 2 |
| 1 | tiny,small,big | 3 |
| 2 | small,medium | 3 |
| 3 | tiny,big | 3 |
再看Cross join
select * from tbl_name aCROSS JOIN incre_table b
运行结果如下:
| ID | mSize | AutoIncreID |
|---|---|---|
| 1 | tiny,small,big | 1 |
| 2 | small,medium | 1 |
| 3 | tiny,big | 1 |
| 1 | tiny,small,big | 2 |
| 2 | small,medium | 2 |
| 3 | tiny,big | 2 |
| 1 | tiny,small,big | 3 |
| 2 | small,medium | 3 |
| 3 | tiny,big | 3 |
| ID | mSize | AutoIncreID |
|---|---|---|
| 1 | tiny,small,big | 1 |
| 1 | tiny,small,big | 2 |
| 1 | tiny,small,big | 3 |
| 2 | small,medium | 1 |
| 2 | small,medium | 2 |
| 2 | small,medium | 3 |
| 3 | tiny,big | 1 |
| 3 | tiny,big | 2 |
| 3 | tiny,big | 3 |
筛选条件
on 后面的条件是从上面的结果中筛选符合条件的结果。
一般情况下我们都会用A表中的某个字段与B表中相同的字段作为筛选条件。 这里我们比较特殊,用on b.AutoIncreID <=(length(a.mSize) -length(replace(a.mSize,’,’,’’))+1)来筛选mSize中单词个数不小于AutoIncreID的结果,下面逐一查看。select * from tbl_name aINNER JOIN incre_table bon (length(a.mSize) -length(replace(a.mSize,',',''))+1)>=b.AutoIncreID
运行结果:
| ID | mSize | AutoIncreID |
|---|---|---|
| 1 | tiny,small,big | 1 |
| 2 | small,medium | 1 |
| 3 | tiny,big | 1 |
| 1 | tiny,small,big | 2 |
| 2 | small,medium | 2 |
| 3 | tiny,big | 2 |
| 1 | tiny,small,big | 3 |
select * from tbl_name aLEFT JOIN incre_table bon (length(a.mSize) -length(replace(a.mSize,',',''))+1)>=b.AutoIncreID
运行结果:
| ID | mSize | AutoIncreID |
|---|---|---|
| 1 | tiny,small,big | 1 |
| 2 | small,medium | 1 |
| 3 | tiny,big | 1 |
| 1 | tiny,small,big | 2 |
| 2 | small,medium | 2 |
| 3 | tiny,big | 2 |
| 1 | tiny,small,big | 3 |
select * from tbl_name aCROSS JOIN incre_table bon (length(a.mSize) -length(replace(a.mSize,',',''))+1)>=b.AutoIncreID
运行结果也是一样的
select * from tbl_name aRIGHT JOIN incre_table bon (length(a.mSize) -length(replace(a.mSize,',',''))+1)>=b.AutoIncreID
运行结果:
| ID | mSize | AutoIncreID |
|---|---|---|
| 1 | tiny,small,big | 1 |
| 1 | tiny,small,big | 2 |
| 1 | tiny,small,big | 3 |
| 2 | small,medium | 1 |
| 2 | small,medium | 2 |
| 3 | tiny,big | 1 |
| 3 | tiny,big | 2 |
以上是从mysql运行结果来看逻辑过程的,但具体在实现的时候是不是按这个过程来执行,我没有做进一步探讨,因为这里涉及数据库底层实现,内存优化这些,有兴趣的话可以进一步研究。
最小规模
都是以某一共同的字段作为on成立的条件
Inner Join: 得到的结果行数可以小于被连接的两个两个表的行数,关系如下所示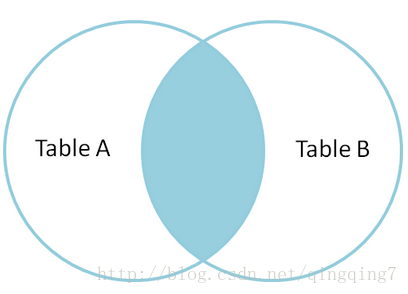 Left Join: 左边的表各行得到保留,如果匹配不到右边,则右侧为NULL,关系如下
Left Join: 左边的表各行得到保留,如果匹配不到右边,则右侧为NULL,关系如下 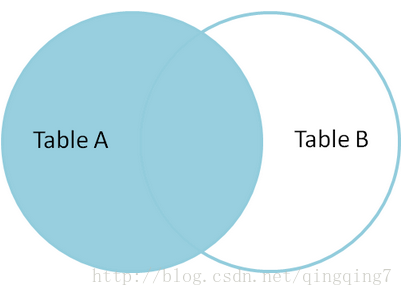 cross Join: 在mysq中与Inner join一致 right Join: 与左连接相反,匹配不到左侧,则左侧为NULL full join: mysql中没有全连接,通过left join Union right join实现,关系如下
cross Join: 在mysq中与Inner join一致 right Join: 与左连接相反,匹配不到左侧,则左侧为NULL full join: mysql中没有全连接,通过left join Union right join实现,关系如下 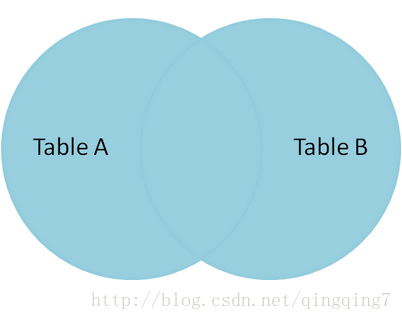
mysql的UNION及UNION ALL用法总结
UNION: 用于合并两个或多个select语句的结果集,并消去重复的值;
注意: 1、合并后的结果集的列名总为第一个select语句结果的列名; 2、被合并的select子集必须有相同的列数,各列的数据类型列的类型可以不一样但要相似,列的顺序必须一致SELECT column_name FROM table1UNIONSELECT column_name FROM table2
UNION ALL: 不去除重复值
SELECT column_name FROM table1UNION ALLSELECT column_name FROM table2
mysql实现交集和差集
mysql中不能直接实现该功能,需要通过组合的方式来达到该效果。
交集: 思路就是将两张表union起来,然后进行计数,由于同时出现在两张表中才是交集的元素,该元素在计数时个数必然大于1。SELECT *,COUNT(*) as inter_flag FROM( SELECT name1,name2 from table_1 UNION SELECT name1,name2 from table_2) as table_tempGROUP BY name1,name2HAVING inter_flag>1
差集:
思路就是将两张表left join,当某一行数据在左表中且在右表中时,左连接后的大表的右半部分不为NULL,去掉这些不为NULL的行即可。SELECT table_temp1.* FROM( SELECT * from table_1) as table_temp1LEFT JOIN( SELECT * from table_2) as table_temp2ON table_temp1.name1=table_temp2.name1WHERE table_temp2.name1 IS NOT NULL
上面是以字段name1作为某一行是否同时在两个表中的标志,实际上可能是多个字段要同时相等才表示某一行同时在两个表中,可以在where语句中加入多个条件来实现。
13.2.7.1. JOIN语法
来源:mysql中文参考手册
MySQL支持以下JOIN语法。这些语法用于SELECT语句的table_references部分和多表DELETE和UPDATE语句:table_references: table_reference [, table_reference] …table_reference: table_factor | join_tabletable_factor: tbl_name [[AS] alias] [{USE|IGNORE|FORCE} INDEX (key_list)] | ( table_references ) | { OJ table_reference LEFT OUTER JOIN table_reference ON conditional_expr }join_table: table_reference [INNER | CROSS] JOIN table_factor [join_condition] | table_reference STRAIGHT_JOIN table_factor | table_reference STRAIGHT_JOIN table_factor ON condition | table_reference LEFT [OUTER] JOIN table_reference join_condition | table_reference NATURAL [LEFT [OUTER]] JOIN table_factor | table_reference RIGHT [OUTER] JOIN table_reference join_condition | table_reference NATURAL [RIGHT [OUTER]] JOIN table_factorjoin_condition: ON conditional_expr | USING (column_ 一个表引用还被称为一个联合表达式。(所有的表通过join会得到一个结果集,select 时就是从这个集合中取数据)
与SQL标准相比,table_factor的语法被扩展了。SQL标准只接受table_reference,而不是圆括号内的一系列条目。
如果我们把一系列table_reference条目中的每个逗号都看作相当于一个内部联合,则这是一个稳妥的扩展。例如:
假设 t1:| a | b | c |
|---|---|---|
| 1 | 4 | 7 |
| 2 | 5 | 8 |
| 3 | 6 | 9 |
t2:
| a | b2 | c2 |
|---|---|---|
| 1 | 4 | 7 |
| 4 | 5 | 8 |
| 5 | 6 | 9 |
t3:
| a3 | b | c3 |
|---|---|---|
| 1 | 1 | 7 |
| 2 | 5 | 8 |
| 3 | 3 | 9 |
t4:
| a4 | b4 | c |
|---|---|---|
| 1 | 4 | 4 |
| 2 | 5 | 5 |
| 3 | 6 | 9 |
SELECT * FROM t1 LEFT JOIN (t2, t3, t4) ON (t2.a=t1.a AND t3.b=t1.b AND t4.c=t1.c)
结果为
a b c a(1) b(1) c(1) a(2) b(2) c(2) a(3) b(3) c(3)1 4 7 2 5 8 3 6 9
空白处为NULL,连接能得到81个可能的结果,但是必须满足on的筛选条件,由于是左连接,左表是基准,所以左表的记录全部都有,后面各表连接上去后,是有值还是空就看能不能满足on条件,这里要同时满足三个条件,t2,t3,t4中找不到这样的记录同时满足这三个条件,因而后面都为空。
t2,t3,t4这一系列table_reference条目中的每个逗号都看作相当于一个内部联合,相当于:SELECT * FROM t1 LEFT JOIN (t2 CROSS JOIN t3 CROSS JOIN t4) ON (t2.a=t1.a AND t3.b=t1.b AND t4.c=t1.c)
在MySQL中,CROSS JOIN从语法上说与INNER JOIN等同(两者可以互相替换。在标准SQL中,两者是不等同的。INNER JOIN与ON子句同时使用,CROSS JOIN以其它方式使用。
通常,在只含有内部联合运行的联合表达式中,圆括号可以被忽略。MySQL也支持嵌套的联合(见7.2.10节,“MySQL如何优化嵌套Join”)。
通常,您不应对ON部分有任何条件。ON部分用于限定在结果集合中您想要哪些行。
如果如下操作SELECT * FROM t1 LEFT JOIN (t2, t3, t4) ON 1=1
on使用1=1这种恒成立的条件,那么会得到81行结果。
但是,您应在WHERE子句中指定这些条件。这条规则有一些例外。在前面的清单中显示的{ OJ … LEFT OUTER JOIN …}语法的目的只是为了保持与ODBC的兼容性。语法中的花括号应按字面书写;该括号不是中间语法。中间语法用于语法描述的其它地方。
- 表引用可以使用tbl_name AS alias_name或tbl_name alias_name指定别名: 假如已经创建如下表格
create table employee (name varchar(10),age int,primary key (name)) engine=MYISAM default charset=UTF8;insert into employee values ('张三',20),('李四',21),('王五',22);create table info (name varchar(10),salary double,primary key (name)) engine=MYISAM default charset=utf8;insert into info values ('张三',6000),('赵六',7000),('田七',8000); employee
张三 20李四 21王五 22
info
name salary张三 6000赵六 7000田七 8000
我们可以如下重命名表格(长的名字可以用代号来表示比较简短,修改程序的时候也比较方便,程序通用性也可能比较强一点)
mysql> SELECT t1.name, t2.salary FROM employee AS t1, info AS t2 WHERE t1.name = t2.name;mysql> SELECT t1.name, t2.salary FROM employee t1, info t2 WHERE t1.name = t2.name;
结果为:
name salary张三 6000
补充:
select * from employee,info;可得到下面的结果 name age name(1) salary张三 20 张三 6000李四 21 张三 6000王五 22 张三 6000张三 20 赵六 7000李四 21 赵六 7000王五 22 赵六 7000张三 20 田七 8000李四 21 田七 8000王五 22 田七 8000
可以看到如果不用连接而是直接多个表的联合表示中查询,其实也是跟连接一样进行了一个笛卡尔积。但跟连接不一样的是它不会强制以左表或右表为标准,筛选的条件就只有where语句。
- ON条件句是可以被用于WHERE子句的格式的任何条件表达式。
- 如果对于在LEFT JOIN中的ON或USING部分中的右表没有匹配的记录,则所有列被设置为NULL的一个行被用于右表。如果一个表在其它表中没有对应部分,您可以使用这种方法在这种表中查找记录:
select employee.* from employee left join info on employee.name=info.name where info.name IS NULL;结果如下:
name age李四 21王五 22
where之前的部分已经得到完整结果,因而这里的where是在左连接后的结果里选择。而不是说先在info里筛选出NULL的部分参与左连接运算。
本例假设info.name被定义为NOT NULL。请参见7.2.9节,“MySQL如何优化LEFT JOIN和RIGHT JOIN”。- USING(column_list)子句用于为一系列的列进行命名。这些列必须同时在两个表中存在。如果表a和表b都包含列c1, c2和c3,则以下联合会对比来自两个表的对应的列:
a LEFT JOIN b USING (c1,c2,c3)先简单的select * from employee left join info using (name);可得到如下结果:
name age salary张三 20 6000李四 21 王五 22
从以上结果看,使用using和on似乎没有太大差别,但是右表中与左表用来连接的列没有出现在最后的结果中。下面看一个更复杂一点的。
create table a (a1 int,c1 int,c2 int,c3 int);insert into a values(1,2,3,4),(4,5,6,7);create table b (b1 int,c1 int,c2 int,c3 int);insert into b values (2,5,6,7),(8,9,3,4);#a表a1 c1 c2 c31 2 3 44 5 6 7#b表b1 c1 c2 c32 5 6 78 9 3 4select * from a left join b using (c1,c2,c3);#结果如下c1 c2 c3 a1 b15 6 7 4 22 3 4 1
从上面也可以看到using和on筛选结果的方式是一样的,但是结果中不会有右表与左表相同的重复列,这个就叫命名吧。
- 两个表的NATURAL [LEFT] JOIN被定义为与INNER JOIN语义相同,或与使用USING子句的LEFT JOIN语义相同。USING子句用于为同时存在于两个表中的所有列进行命名。
select * from a natural join b;#结果c1 c2 c3 a1 b15 6 7 4 2select * from a natural left join b;#结果c1 c2 c3 a1 b15 6 7 4 22 3 4 1 select * from a inner join b using (c1,c2,c3); #结果c1 c2 c3 a1 b15 6 7 4 2select * from a join b using (c1,c2,c3);#结果c1 c2 c3 a1 b15 6 7 4 2
inner join与left join用法很像,只不过是取交集,即连接的两个表任何一方在笛卡尔积结果中出现NULL即被舍去。
NATURAL JOIN 不需要使用条件,会自己去找两表共同的列,最终的效果与使用using的inner join是一样的。 NATURAL left JOIN则与使用using的left join是一样的效果。 不写什么join即为innner join 综上也可以说natural 和using的效果是一样的。至于join本身还是按各种join的规则来。- INNER JOIN和,(逗号)在无联合条件下是语义相同的:两者都可以对指定的表计算出笛卡儿乘积(也就是说,第一个表中的每一行被联合到第二个表中的每一行)。 个人认为笛卡尔积是理解整个连接的基础。
- RIGHT JOIN的作用与LEFT JOIN的作用类似。要使代码可以在数据库内移植,建议您使用LEFT JOIN代替RIGHT JOIN。 这句话的意思应该是,我们根本就不应该去用right join,因为我们只需要将左表和右表颠倒一下就可以用left join实现right join
- STRAIGHT_JOIN与JOIN相同。除了有一点不一样,左表会在右表之前被读取。STRAIGH_JOIN可以被用于这样的情况,即联合优化符以错误的顺序排列表。
select * from a straight_join b using (c1,c2,c3);#结果c1 c2 c3 a1 b15 6 7 4 2
似乎和join没有什么区别
再来看看select * from a join b on (a.c1=b.c1 and a.c2=b.c2 and a.c3=b.c3);#结果a1 c1 c2 c3 b1 c1(1) c2(1) c3(1)4 5 6 7 2 5 6 7select * from a straight_join b on (a.c1=b.c1 and a.c2=b.c2 and a.c3=b.c3);#结果a1 c1 c2 c3 b1 c1(1) c2(1) c3(1)4 5 6 7 2 5 6 7
真没发现有什么区别。using会打乱合列排序,而on不会,但on列有冗余。
您可以提供提示,当从一个表中恢复信息时,MySQL应使用哪个索引。通过指定USE INDEX(key_list),您可以告知MySQL只使用一个索引来查找表中的行。另一种语法IGNORE INDEX(key_list)可以被用于告知MySQL不要使用某些特定的索引。如果EXPLAIN显示MySQL正在使用来自索引清单中的错误索引时,这些提示会有用处。
您也可以使用FORCE INDEX,其作用接近USE INDEX(key_list),不过增加了一项作用,一次表扫描被假设为代价很高。换句话说,只有当无法使用一个给定的索引来查找表中的行时,才使用表扫描。USE KEY、IGNORE KEY和FORCE KEY是USE INDEX、IGNORE INDEX和FORCE INDEX的同义词。
注释:当MySQL决定如何在表中查找行并决定如何进行联合时,使用USE INDEX、IGNORE INDEX和FORCE INDEX只会影响使用哪些索引。当分解一个ORDER BY或GROUP BY时,这些语句不会影响某个索引是否被使用。
部分的联合示例:
mysql> SELECT * FROM table1,table2 WHERE table1.id=table2.id;mysql> SELECT * FROM table1 LEFT JOIN table2 ON table1.id=table2.id;mysql> SELECT * FROM table1 LEFT JOIN table2 USING (id);mysql> SELECT * FROM table1 LEFT JOIN table2 ON table1.id=table2.id LEFT JOIN table3 ON table2.id=table3.id;#我们再生成一张表create table department_info (name varchar(10),department varchar(10));insert into department_info values ('李四','soft'),('赵六','sales');name department李四 soft赵六 salesselect * from employee left join info on employee.name=info.name left join department_info on info.name=department_info.name;#结果如下:name age name(1) salary name(2) department张三 20 张三 6000 李四 21 王五 22 可以看到这里逐步left join 与之前SELECT * FROM t1 LEFT JOIN (t2, t3, t4) ON (t2.a=t1.a AND t3.b=t1.b AND t4.c=t1.c)又有很大的不一样,之前是右边的多个一起参与判断on条件,只有全部成立了,才全部不为空,否则全为空;而这里是逐步left join的,当左表和右边第一个表left join有一部分满足on条件这一部分就不为空,然后结果再参与第二次left join;逐步left join和逗号分隔的多个表的left join相同的是在判断on条件进都会以左表为基准。
mysql> SELECT * FROM table1 USE INDEX (key1,key2) -> WHERE key1=1 AND key2=2 AND key3=3; mysql> SELECT * FROM table1 IGNORE INDEX (key3) -> WHERE key1=1 AND key2=2 AND key3=3;
见7.2.9节,“MySQL如何优化LEFT JOIN和RIGHT JOIN”。
注释:自然联合和使用USING的联合,包括外部联合变量,依据SQL:2003标准被处理。这些变更时MySQL与标准SQL更加相符。不过,对于有些联合,这些变更会导致不同的输出列。另外,有些查询在旧版本(5.0.12以前)工作正常,但也必须重新编写,以符合此标准。对于有关当前联合处理和旧版本中的联合处理的效果的对比,以下列表提供了更详细的信息。- NATURAL联合或USING联合的列会与旧版本不同。特别是,不再出现冗余的输出列,用于SELECT *扩展的列的顺序会与以前不同。 示例:
CREATE TABLE t1 (i INT, j INT);CREATE TABLE t2 (k INT, j INT);INSERT INTO t1 VALUES(1,1);INSERT INTO t2 VALUES(1,1);SELECT * FROM t1 NATURAL JOIN t2;SELECT * FROM t1 JOIN t2 USING (j);
对于旧版本,语句会产生以下输出:
+------+------+------+------+| i | j | k | j |+------+------+------+------+| 1 | 1 | 1 | 1 |+------+------+------+------++------+------+------+------+| i | j | k | j |+------+------+------+------+| 1 | 1 | 1 | 1 |+------+------+------+------+
在第一个SELECT语句中,列i同时出现在两个表中,为一个联合列,所以,依据标准SQL,该列在输出中只出现一次。与此类似,在第二个SELECT语句中,列j在USING子句中被命名,应在输出中只出现一次。但是,在两种情况下,冗余的列均没被消除。另外,依据标准SQL,列的顺序不正确。
现在,语句产生如下输出:+------+------+------+| j | i | k |+------+------+------+| 1 | 1 | 1 |+------+------+------++------+------+------+| j | i | k |+------+------+------+| 1 | 1 | 1 |+------+------+------+
冗余的列被消除,并且依据标准SQL,列的顺序是正确的:
* 第一,两表共有的列,按在第一个表中的顺序排列 * 第二,第一个表中特有的列,按该表中的顺序排列 * 第三,第二个表中特有的列,按该表中的顺序排列- 对多方式自然联合的估算会不同。方式要求重新编写查询。假设您有三个表t1(a,b), t2(c,b)和t3(a,c)每个表有一行:t1(1,2), t2(10,2)和t3(7,10)。同时,假设这三个表具有NATURAL JOIN: 第一步
select * from t1 natural join t2;结果为
b a c2 1 10
因为t1和t2有共同的列’b’,且值相等。
第二步select * from t1 natural join t2 natural join t3;结果为 a c b
t1 natural join t2后得到’a’,‘b’,‘c’三列,再natural join t3时与t3有’b’,'c’两个列相同,并以这两个作为比较的条件,同时相等才有结果,而结果中只有’c’列是相等的,最终结果为空。
在旧版本中,第二个联合的左操作数被认为是t2,然而它应该为嵌套联合(t1 NATURAL JOIN t2)。结果,对t3的列进行检查时,只检查其在t2中的共有列。如果t3与t1有共有列,这些列不被用作equi-join列。因此,在旧版本的MySQL中,前面的查询被转换为下面的equi-join:
SELECT … FROM t1, t2, t3 WHERE t1.b = t2.b AND t2.c = t3.c; 此联合又省略了一个equi-join谓语(t1.a = t3.a)。结果是,该联合产生一个行,而不是空结果。正确的等价查询如下: SELECT … FROM t1, t2, t3 WHERE t1.b = t2.b AND t2.c = t3.c AND t1.a = t3.a; 如果您要求在当前版本的MySQL中获得和旧版本中相同的查询结果,应把自然联合改写为第一个equi-join。 - 在旧版本中,逗号操作符(,)和JOIN均有相同的优先权,所以联合表达式t1, t2 JOIN t3被理解为
((t1, t2) JOIN t3)。现在,JOIN 有更高的优先权,所以表达式被理解为(t1, (t2 JOIN t3))。这个变更会影响使用ON子句的语句,因为该子句只参阅联合操作数中的列。优先权的变更改变了对什么是操作数的理解。 示例:
CREATE TABLE t1 (i1 INT, j1 INT);CREATE TABLE t2 (i2 INT, j2 INT);CREATE TABLE t3 (i3 INT, j3 INT);INSERT INTO t1 VALUES(1,1);INSERT INTO t2 VALUES(1,1);INSERT INTO t3 VALUES(1,1);SELECT * FROM t1, t2 JOIN t3 ON (t1.i1 = t3.i3);
在旧版本中,SELECT是合法的,因为t1, t2被隐含地归为(t1,t2)。现在,JOIN取得了优先权,因此用于ON子句的操作数是t2和t3。因为t1.i1不是任何一个操作数中的列,所以结果是出现在’on clause’中有未知列’t1.i1’的错误。要使联合可以被处理,用使用圆括号把前两个表明确地归为一组,这样用于ON子句的操作数为(t1,t2)和t3:
select * from (t1,t2) join t3 on (t1.i1=t3.i3);#结果为i1 j1 i2 j2 i3 j31 1 1 1 1 1
本变更也适用于INNER JOIN,CROSS JOIN,LEFT JOIN和RIGHT JOIN。
- 在旧版本中,ON子句可以参阅在其右边命名的表中的列。现在,ON子句只能参阅操作数。 示例:
CREATE TABLE t1 (i1 INT);CREATE TABLE t2 (i2 INT);CREATE TABLE t3 (i3 INT);SELECT * FROM t1 JOIN t2 ON (i1 = i3) JOIN t3;
在旧版本中,SELECT语句是合法的。现在该语句会运行失败,出现在’on clause’中未知列’i3’的错误。这是因为i3是t3中的一个表,而t3不是ON子句中的操作数。本语句应进行如下改写:
SELECT * FROM t1 JOIN t2 JOIN t3 ON (i1 = i3); 在旧版本中,一个USING子句可以被改写为一个ON子句。ON子句对比了相应的列。例如,以下两个子句具有相同的语义: a LEFT JOIN b USING (c1,c2,c3)a LEFT JOIN b ON a.c1=b.c1 AND a.c2=b.c2 AND a.c3=b.c3
现在,这两个子句不再是一样的:
* 在决定哪些行满足联合条件时,两个联合保持语义相同。 * 在决定哪些列显示SELECT *扩展时,两个联合的语义不相同。USING联合选择对应列中的合并值,而ON联合选择所有表中的所有列。对于前面的USING联合,SELECT *选择这些值:COALESCE(a.c1,b.c1), COALESCE(a.c2,b.c2), COALESCE(a.c3,b.c3) 对于ON联合,SELECT *选择这些值:a.c1, a.c2, a.c3, b.c1, b.c2, b.c3 使用内部联合时,COALESCE(a.c1,b.c1)与a.c1或b.c1相同,因为两列将具有相同的值。使用外部联合时(比如LEFT JOIN),两列中有一列可以为NULL。该列将会从结果中被忽略。 13.2.7.2. UNION语法
SELECT ...UNION [ALL | DISTINCT]SELECT ...[UNION [ALL | DISTINCT]SELECT ...]
UNION用于把来自许多SELECT语句的结果组合到一个结果集合中。
列于每个SELECT语句的对应位置的被选择的列应具有相同的类型。(例如,被第一个语句选择的第一列应和被其它语句选择的第一列具有相同的类型。)在第一个SELECT语句中被使用的列名称也被用于结果的列名称。 这里也可以看出列名是可以不同的,只要列的数据类型一致就可以。 SELECT语句为常规的选择语句,但是受到如下的限定:- 只有最后一个SELECT语句可以使用INTO OUTFILE。
- HIGH_PRIORITY不能与作为UNION一部分的SELECT语句同时使用。如果您对第一个SELECT指定了HIGH_PRIORITY,则不会起作用。如果您对其它后续的SELECT语句指定了HIGH_PRIORITY,则会产生语法错误。
如果您对UNION不使用关键词ALL,则所有返回的行都是唯一的,如同您已经对整个结果集合使用了DISTINCT。如果您指定了ALL,您会从所有用过的SELECT语句中得到所有匹配的行。
DISTINCT关键词是一个自选词,不起任何作用,但是根据SQL标准的要求,在语法中允许采用。
(在MySQL中,DISTINCT代表一个共用体的默认工作性质。)您可以在同一查询中混合UNION ALL和UNION DISTINCT。被混合的UNION类型按照这样的方式对待,即DISTICT共用体覆盖位于其左边的所有ALL共用体。比如a union all b union c,则b和c中相同的数据只会留一条,但是不影响与a的合并;DISTINCT共用体可以使用UNION DISTINCT明确地生成,或使用UNION(后面不加DISTINCT或ALL关键词)隐含地生成。
如果您想使用ORDER BY或LIMIT子句来对全部UNION结果进行分类或限制,则应对单个地SELECT语句加圆括号,并把ORDER BY或LIMIT放到最后一个的后面。以下例子同时使用了这两个子句:
(SELECT a FROM tbl_name WHERE a=10 AND B=1)UNION(SELECT a FROM tbl_name WHERE a=11 AND B=2)ORDER BY a LIMIT 10;
这种ORDER BY不能使用包括表名称(也就是,采用tbl_name.col_name格式的名称)列引用。可以在第一个SELECT语句中提供一个列别名,并在ORDER BY中参阅别名,或使用列位置在ORDER BY中参阅列。(首选采用别名,因为不建议使用列位置。)
另外,如果带分类的一列有别名,则ORDER BY子句必须引用别名,而不能引用列名称。以下语句中的第一个语句可以运行,但是第二个会运行失败,出现在’order clause’中有未知列’a’的错误:其实这个很好理解:我们是将选出的结果进行合并,而合集的列名是由第一个结果集来确定的,当然order by 的时候要用其对应的列名,如果列有别名当然也应该用别名。
(SELECT a AS b FROM t) UNION (SELECT ...) ORDER BY b;(SELECT a AS b FROM t) UNION (SELECT ...) ORDER BY a;
To apply ORDER BY or LIMIT to an individual SELECT, place the clause inside the parentheses that enclose the SELECT: 为了对单个SELECT使用ORDER BY或LIMIT,应把子句放入圆括号中。圆括号包含了SELECT:
(SELECT a FROM tbl_name WHERE a=10 AND B=1 ORDER BY a LIMIT 10)UNION(SELECT a FROM tbl_name WHERE a=11 AND B=2 ORDER BY a LIMIT 10);
圆括号中用于单个SELECT语句的ORDER BY只有当与LIMIT结合后,才起作用。否则,ORDER BY被优化去除。(如果最后要排序的话,其实在单个查询中往往也没有必要排序,最后一次性来处理就好;当然limit放在单个查询中还是可以过滤很多结果的)
UNION结果集合中的列的类型和长度考虑了被所有SELECT语句恢复的数值。例如,考虑如下语句:
mysql> SELECT REPEAT('a',1) UNION SELECT REPEAT('b',10);+---------------+| REPEAT('a',1) |+---------------+| a || bbbbbbbbbb |+---------------+ (在部分早期版本的MySQL中,第二行已被删节到长度为1。)
转载地址:https://blog.csdn.net/qingqing7/article/details/78472382 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
