日常记录:抓取某条网页端关键词搜索结果
发布日期:2022-07-08 02:55:48
浏览次数:27
分类:技术文章
本文共 2118 字,大约阅读时间需要 7 分钟。
最近受别人所托抓取。。。。的新闻,看了下网页也是静态的,感觉应该跟某度差不多,结果做起来发现还是会有问题,在这留个记录。抓取结果仅用于研究分析,不用于其他商业目的。
一、问题描述
在利用python写爬虫时,一般会遇到各种问题,这次主要问题是request的headers的填写,如果没有这个,或者只是写个User-Agent,那即使请求成功,也获取不到任何信息,得到的只是status_code为200或者400,所以在这里我尝试了N多方法,最后发现是cookies的问题。
其实这也就是一种反爬措施,网站建设者为了避免被爬,造成太多无效访问,会设置很多反扒措施,这次遇到的就是其中一种方式,而我们这样写就是为了把自己模拟成正常的浏览器访问。
二、解决办法
那如何进行headers配置,直接看图,我用的是火狐浏览器,其他浏览器也差不多。
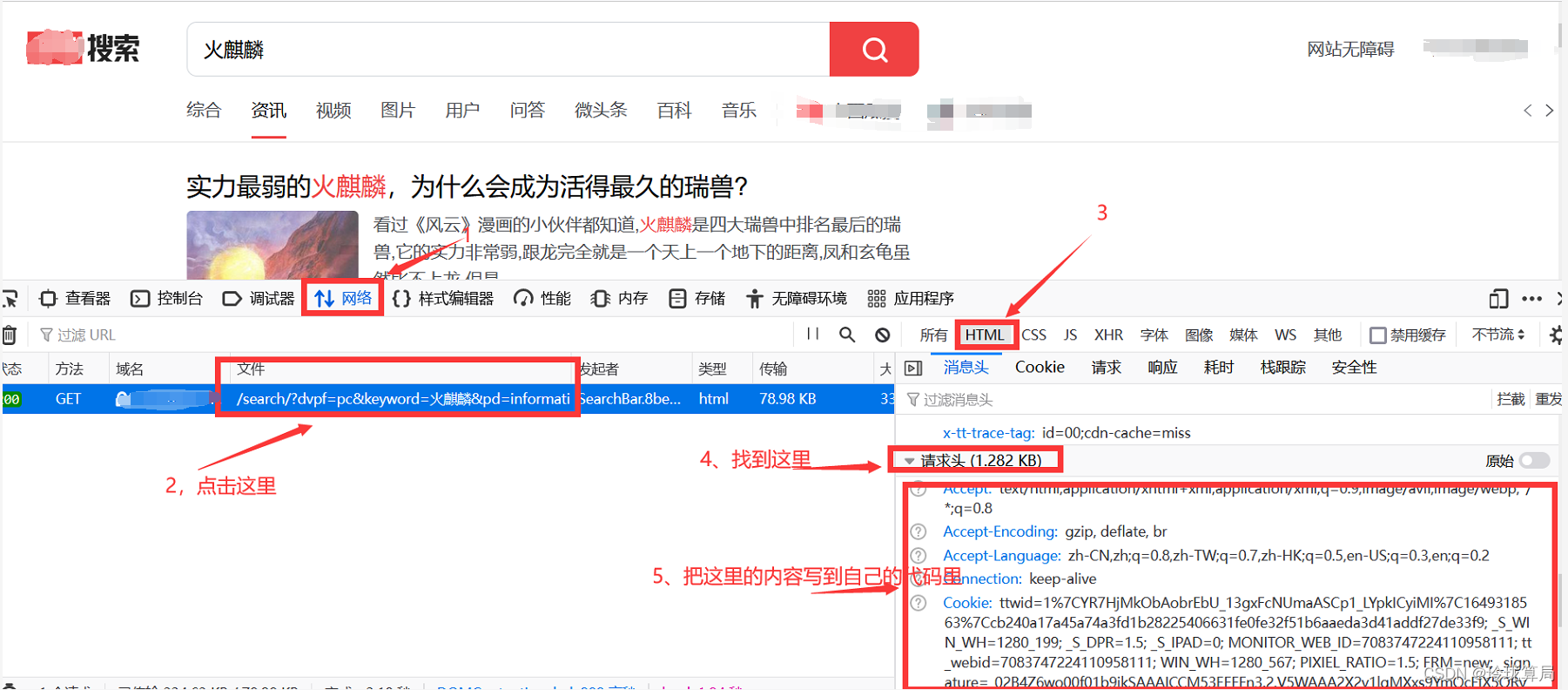
抓取的代码倒是很简单,这里只是写到了抓取,后续保存及其他处理,如保存,加工或者分析啊,就根据个人需要往上加就行了。
from bs4 import BeautifulSoup as bsimport requestsif __name__ == '__main__': headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:99.0) Gecko/20100101 Firefox/99.0", "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8", "Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2", "Upgrade-Insecure-Requests": "1", "Sec-Fetch-Dest": "document", "Sec-Fetch-Mode": "navigate", "Sec-Fetch-Site": "none", "Sec-Fetch-User": "?1", 'Cookie':'ttwid=1%7CYR7HjMkObAobrEbU_13gxFcNUmaASCp1_LYpkICyiMI%7C1649318563%7Ccb240a17a45a74a3fd1b28225406631fe0fe32f51b6aaeda3d41addf27de33f9; _S_WIN_WH=1280_103; _S_DPR=1.5; _S_IPAD=0; MONITOR_WEB_ID=7083747224110958111; tt_webid=7083747224110958111; WIN_WH=1280_567; PIXIEL_RATIO=1.5; FRM=new; _signature=_02B4Z6wo00f01b9ikSAAAICCM53EEEFn3.2.V5WAAA2X2y1lgMXxs9YmQcFIX5QRy0Y1lk7O7ZGsAfjqVAiNksDbrlZb452nOXNmXbMxUpEWsnn4xMYtokVceq2AzDL4cSApENTM8mIAqFWW69; ttcid=fa05cdd22db64fcc87516160fe59bf4f41; tt_scid=lYCB8u8JkQnzgbmd.Cmstpnh.MbfE2.LWzD-o0vB75dua9iDjmqzZs2F3mcYl8Iq8b75', "Cache-Control": "max-age=0"} for num in range(0,3): #只抓前三页内容 targeturl = 'https://so.XXXX.com/search?keyword=火麒麟 &pd=information&source=pagination&dvpf=pc&page_num='+str(num) response = requests.get(targeturl, headers=headers) r = response.content soup = bs(r, "html.parser") #利用Beautifulsoup进行解析 urls = soup.find_all("a",class_='text-ellipsis text-underline-hover') for item in urls: print(item.text) 代码里so.XXXX.com,换成对应的网站地址(合规问题),不出问题应该能抓取到结果,,可以去进行分词做更多分析。
转载地址:https://blog.csdn.net/lukaishilong/article/details/124040534 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
很好
[***.229.124.182]2024年03月26日 02时32分45秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
Linux上安装jdk1.8和配置环境变量
2019-04-26
A表中存有B表的多个主键,逗号隔开,B表进行删除时,要判断B表是否绑定A,怎么实现?
2019-04-26
centos环境下docker安装redis并挂载外部配置和数据
2019-04-26
maven中的setting.xml 配置文件
2019-04-26
MySQL的Limit详解
2019-04-26
java \t,\n,\r,\b,\f 的作用
2019-04-26
java8 LocalDate 根据时间获取星期几
2019-04-26
Base64 加密解密
2019-04-26
Excel表格身份证号显示不完整问题
2019-04-26
今日份实操——(HTML+CSS)浮动布局练习
2019-04-26
2011年下半年信息系统项目管理师上午试卷试题及参考答案,考试真题
2019-04-26
2011年下半年信息系统项目管理师考试下午案例分析试题及参考答案,考试真题
2019-04-26
2019年上半年信息系统项目管理师考试真题及答案(包含综合知识,案例分析,论文真题)
2019-04-26
理财启蒙必读书籍《小钱狗狗》心得
2019-04-26
《巴比伦最富有的人》精髓:学会储蓄、谨慎投资,从而走上致富之路
2019-04-26
《不可不知的经济真相》精髓:普通老百姓如何进行楼市和股市的投资
2019-04-26
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 306202941 位访客
访问时间: 2024-04-19 12:37:33
访问IP: 18.217.144.32
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版