Sed和AWK入门教程之AWK篇
又见cat,呵呵. 更有意义一点的:
awk能识别文本的结构,还能格式化输出.
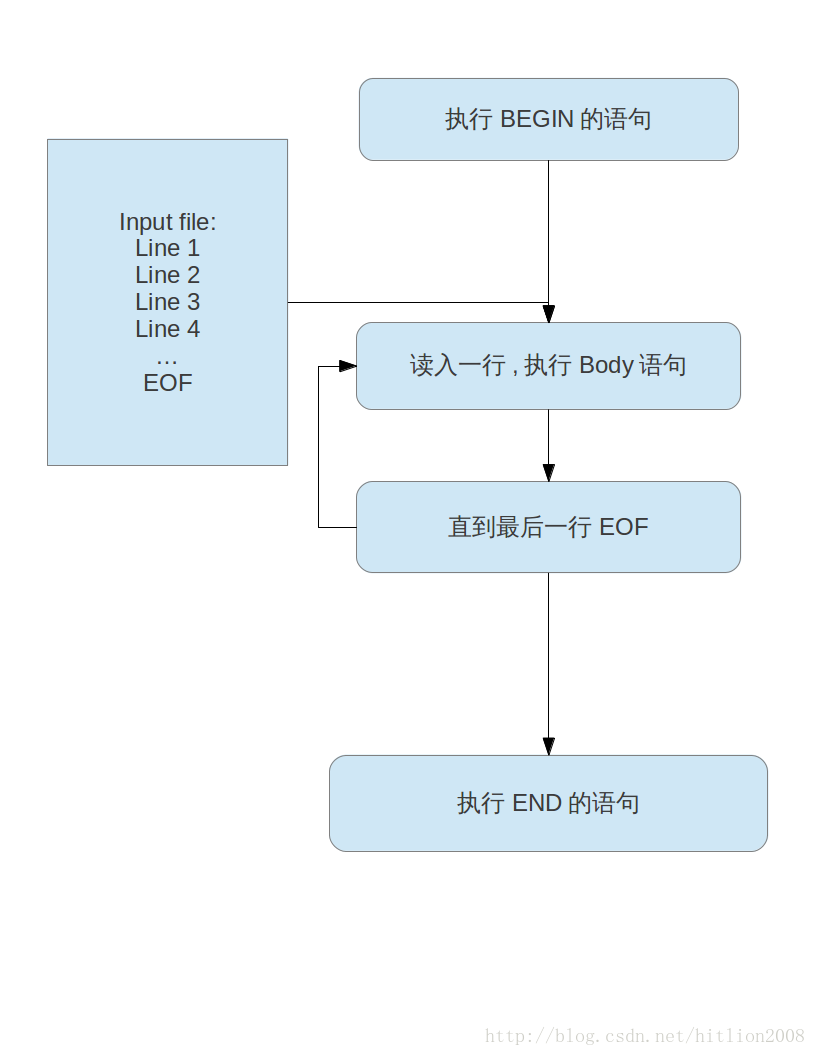 AWK的执行方式,先执行BEGIN段内的内容,然后对文件的每一行,执行body,所有行都处理完后,执行END段.也就是说BEGIN和END都只执行一次,而Body loop要执行很多次,视行数和模式匹配而定,因为要执行多次,所以它叫Body loop. print不跟参数时,输出当前的记录.
AWK的执行方式,先执行BEGIN段内的内容,然后对文件的每一行,执行body,所有行都处理完后,执行END段.也就是说BEGIN和END都只执行一次,而Body loop要执行很多次,视行数和模式匹配而定,因为要执行多次,所以它叫Body loop. print不跟参数时,输出当前的记录.
发布日期:2021-07-29 10:44:37
浏览次数:17
分类:技术文章
本文共 3162 字,大约阅读时间需要 10 分钟。
AWK是一门专门用于文本处理的编程语言.是的,它是编程语言,它的目的仅有文本处理,所以你不能用它写系统软件,或者做科学计算(当然,它也能做数学计算),它只能用于文本处理.与sed不同,AWK具有编程语言的特性,有内置函数,有逻辑语句,有输入输出语句,其实它看起来很像C语言,只不过所有功能集中于文本处理. 与Sed不同,AWK最强大的功能在于处理结构化的文本,也就是说文本有一定的组织结构的.
命令格式
awk [-F value] [-v var=value] 'program text' [files....] awk [-F value] [-v var=value] -f program-file [files....]例如:
- [alex@alexon:~]$awk '{print}' persons.txt
- 1011, Alex Perkins, Product, Software Developer
- 3923, Jimmey Mills, Operation, COO
- 23934, Kevin Kim, Management, CEO
- 2321, Chris Paul, UI, Designer
- [alex@alexon:~]$awk -F , -v OFS=: '{print $1, $2, $3, $4}' persons.txt
- 1011: Alex Perkins: Product: Software Developer
- 3923: Jimmey Mills: Operation: COO
- 23934: Kevin Kim: Management: CEO
- 2321: Chris Paul: UI: Designer
程序的格式
也就是'program text'或者program file中的内容:BEGIN {actions} /pattern/ {actions} END {actions}BEGIN是处理文件之前执行的. 中间的叫Body loop.后面的END是处理完结束后执行. 可以用\来实现分行输入:
BEGIN {action} \ /pattern {action} \ END {action}如果写在文件中,则可以像写C语言那样写
program-file.awk: BEGIN { actions; } /pattern/ { actions; } END { actions;}
AWK的执行方式,先执行BEGIN段内的内容,然后对文件的每一行,执行body,所有行都处理完后,执行END段.也就是说BEGIN和END都只执行一次,而Body loop要执行很多次,视行数和模式匹配而定,因为要执行多次,所以它叫Body loop. 内置变量
AWK会假定输入的文本是一个结构化文本,也即是一个表格形式的,每一行是一个记录(Record),每一列是一个域(Field).AWK读入时会以结构化方式对文本进行处理,这时就用到了一些内置变量:FS -- Field Separator 域的分隔符,默认的是以空白符分隔 RS -- Record Separator 记录的分隔符,默认是以换行符来分隔 FILENAME -- current filename NF -- Number of Feilds in current record NR -- Number of Record 输入的记录数,相当于行号一样,多个文件时会接着递增. FNR -- File Number of Record 输入的当前记录数,每个文件单独计算 $0 -- the whole record 当前整个记录 $n -- the nth field of the current record 当前记录和第n个域利用这些内置变量,AWK读入文本后就可以对文本进行处理,以达到分解结构化文本的目的:把输入变成一个Table形式的结构化信息. 对就的,输出的时候也有对应的变量来控制输出的格式:
OFS -- Ouput Field Separator 输出时的域分隔符 ORS -- Output Record Separator 输出时的记录分隔符
语句(actions)
print语句
以字串形式输出,后面的每个变量都当成是字串.当以逗号分隔时,就用OFS来分隔域,如果以空格分隔时,就以空格来作为OFS:
- [alex@alexon:~]$awk -F, 'BEGIN {OFS=";"} {print $1,$2,$3,$4}' persons.txt
- 1011; Alex Perkins; Product; Software Developer
- 3923; Jimmey Mills; Operation; COO
- 23934; Kevin Kim; Management; CEO
- 2321; Chris Paul; UI; Designer
- [alex@alexon:~]$awk -F, 'BEGIN {OFS=";"} {print $1 $2 $3 $4}' persons.txt
- 1011 Alex Perkins Product Software Developer
- 3923 Jimmey Mills Operation COO
- 23934 Kevin Kim Management CEO
- 2321 Chris Paul UI Designer
printf语句
可以进行与C语言十分类似的格式化输出.
- [alex@alexon:~]$awk -F, 'BEGIN {OFS=";"} {printf "%d: ", NR; print $1,$2,$3,$4}' persons.txt
- 1: 1011; Alex Perkins; Product; Software Developer
- 2: 3923; Jimmey Mills; Operation; COO
- 3: 23934; Kevin Kim; Management; CEO
- 4: 2321; Chris Paul; UI; Designer
程序语言
与C语言十分类似.有运算符,有内置函数,有变量,可以实现十分强大的功能,这部分通常用不到,也不是一篇文章能讲的清的,可以参考awk的man文档或者书籍.推荐<Sed & Awk><Sed and Awk 101 Hacks>正则表达式
元字符有: ^ $ . [ ] | ( ) * + ? AWK中的与标准的正则表达式一样:位置符:
^ --- 行首 $ ----行尾 . ----任意非换行符'\n'符 \b ---- 一个单词结尾,单词定义为一连串的字母或数字,可以单独放在一端,也可放二端.
限量符
* --- 0或1个或多个 + --- 1个或多个 ? --- 0或1 {m} --- 出现m次 {m,n} --- 出现m次到n次,如{1,5}表示出现1次到5次不等(1,2,3,4,5次)
转义符
\ --- 可以转义特殊字符
字符集
[] ---其内的任意字符 [^] --- 匹配任何不在此字符集中的字符
操作符
| ---- 或操作,abc\|123匹配123或者abc (...) ----组合,形成一个组,主要用于索引 \n ---- 前面第n个组合, /\(123\)\1/ 则匹配123123
转载地址:https://blog.csdn.net/thinkinwm/article/details/9307441 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
不错!
[***.144.177.141]2024年04月10日 18时50分57秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
木兰编程语言入门教程之二——控制走向
2019-04-26
基于「木兰」编译器,加十行代码实现 ∈ (属于集合)语法
2019-04-26
创建安卓键盘演示——“好不”
2019-04-26
木兰编程语言入门教程之三——函数和类型
2019-04-26
基于「木兰」逆向工程用 pyinstaller 生成可执行文件
2019-04-26
从微盟事件看商业数据公开化的必然趋势
2019-04-26
为新语言编写Visual Studio Code语法高亮插件
2019-04-26
手机编程环境初尝试-用AIDE开发Android应用
2019-04-26
Java关键字的汉化用词探讨
2019-04-26
程序员面试时用中文命名写白板代码的好处
2019-04-26
1992年日本对母语编程的可读性比较实验
2019-04-26
[转] 用python编写控制网络设备的自动化脚本3:启动
2019-04-26
扩展Python控制台实现中文反馈信息
2019-04-26
扩展Python控制台实现中文反馈信息之二-正则替换
2019-04-26
在PyPI测试平台发布Python包
2019-04-26
中文代码示例之Electron桌面应用开发初体验
2019-04-26
中文代码示例之NW.js桌面应用开发初体验
2019-04-26
为《 两周自制脚本语言 》添加中文测试代码
2019-04-26
将《 两周自制脚本语言 》测试中使用的接口中文化
2019-04-26
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 306352779 位访客
访问时间: 2024-04-20 03:29:21
访问IP: 18.119.125.135
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版