本文共 2729 字,大约阅读时间需要 9 分钟。
原标题:高效Java第九条覆盖equals时总要覆盖hashCode
高效Java第九条覆盖equals时总要覆盖hashCode
在每个覆盖了equals方法的类中,也必须覆盖hashCode方法。否则会导致该类无法与基于散列的集合一起正常运作。 hashCode约定
在应用程序的执行期间,只要对象的equals方法所用到的信息没有被修改,那么对着同一个对象调用多次,hashCode方法都必须始终如一地返回同一个整数。
如果两个对象equals(Object)方法比较是相等的,那么调用这两个对象的hashCode方法必须产生同样的整数结果。
如果两个对象equals(Object)比较是不相等的,那么调用这两个对象中的hashCode方法,则不一定要产生不同的整数结果。但是给不相等的对象产生截然不同的整数结果,有可能提高散列表的性能。 没有覆盖hashCode违反第二条约定
因没有覆盖hashCode而违反的关键约定是第二条:相等的对象必须具有相等的散列码。 PhoneNumber例子——没有覆盖hashCode


该类无法与HashMap一起正常工作:

m.get(new PhoneNumber(408, 867, 5309))返回null。由于PhoneNumber类没有覆盖hashCode方法,从而导致两个相等的实例具有不相等的散列码,违反了hashCode的约定。因此,put方法把电话号码对象存放在一个散列桶中,get方法却在另一个散列桶中查找这个电话号码。即使这两个实例正好被放到同一个散列桶中,get方法也必定会返回null,因为HahsMsap有一项优化,可以将每个项相关联的散列码缓存起来,如果散列码不匹配,也不必检验对象的等同性。
给PhoneNumber类提供一个适当的hashCode方法。下面的hashCode方法是错误的:

虽然上面的hashCode方法确保了相等的对象总是具有同样的散列码。但是它使得每个对象都具有同样的散列码。因此,每个对象都被映射到同一个散列桶中,使散列表退化为链表。它使得本该线性时间运行的程序变成了以平方级时间在运行。对于规模很大的散列表而言,这关系到散列表能否正常工作。 如何编写好的散列函数
一个好的散列函数倾向于为不相等的对象产生不相等的散列码。散列函数应该把集合中不相等的实例均匀地分布到所有可能的散列值上。
1.把某个非零的常数值,比如17,保存在一个名为result的int类型的变量中。2.对于对象中每个关键域f(指equals方法涉及的每个域),完成以下步骤:a。为该域计算int类型的散列码c:i.如果该域是boolean类型,则计算(f?1:0)。ii.如果该域是byte、char、short或者int类型,则计算(int)f。iii.如果该域是long类型,则计算(int)(f ^ (f >>> 32))。iv.如果该域是float类型,则计算Float.floatToIntBits(f)。v.如果该域是double类型,则计算Double.doubleToLongBits(f),然后按照步骤2.a.iii,为得到的long类型值计算散列值。vi.如果该域是一个对象引用,并且该类的equals方法通过递归地调用equals方法来比较这个域,则同样为这个域递归地调用hashCode。如果需要更复杂的比较,则为这个域计算一个范式,然后针对这个范式调用hashCode。如果这个域的值为null,则返回0(或者其他某个常数,但通常是0)。
vii.如果该域是一个数组,则要把每一个元素当做单独的域来处理。递归地应用上述规则,对每个重要的元素计算一个散列码,然后根据步骤2.b中的做法把这些散列值组合起来。如果数组域中的每个元素都很重要,建议使用Arrays.hashCode方法。b.把步骤2.a中计算得到的散列码c合并到result中:result = 31 * result + c;3.返回result。
4.写完了hashCode方法之后,问问自己“相等的实例是否都具有相等的散列码”。建议编写单元测试。
计算散列码可以把冗余域排除在外。如果一个域的值可以根据参与计算的其他域的值计算出来,则可以把这样的域排除在外。必须排除equals比较计算中没有用到的任何域,否则很有可能违反hashCode约定的第二条。
值17是任选的。步骤2.b中的乘法部分使得散列值依赖于域的顺序,如果一个类中包含多个相似的域,这样的乘法运算就会产生一个更好的散列函数。String的散列函数省略了乘法部分,那么只是字母顺序不同的所有字符串就会有相同的散列码。选择31是因为它是一个奇素数。如果乘数是偶数,并且乘法溢出的话,信息就会丢失,因为与2相乘等价于移位运算。使用素数的好处并不很明显,但习惯上都使用素数来计算散列结果。31可以利用移位和减法来代替乘法,可以得到更好的性能:31 * i == (i << 5) -i。JVM可以自动完成这种优化。 给PhoneNumber编写好的hashCode
PhoneNumber类的hashCode:
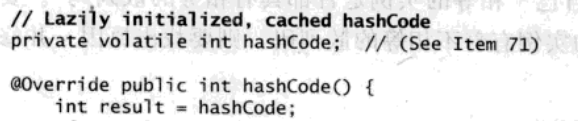
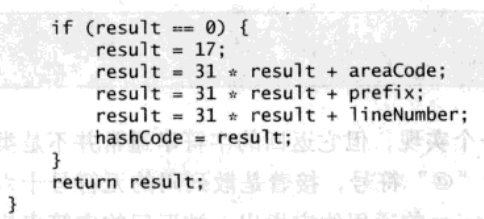
 缓存散列码
缓存散列码
不可变类如果计算散列码的开销比较大,就应该考虑把散列码缓存在对象内部,而不是每次请求的时候都重新计算散列码。如果类的大多数对象都会被用做散列键,就应该在创建实例的时候计算散列码。否则,可以选择“延迟初始化”散列码,一直到hashCode被第一次调用的时候才初始化。PhoneNumber类的对象有可能会经常被作为散列键:
 不要排除对象的关键部分
不要排除对象的关键部分
不要试图从散列码计算中排除掉一个对象的关键部分来提高性能。即使这样得到的散列函数运行起来更快,但是它的效果不见得会好,可能会导致散列表慢到根本无法使用。在实践中,散列函数可能面临大量的实例,在选择忽略的区域之中,这些实例区别非常大。散列函数会把所有这些实例映射到极少数的散列码上,基于散列的集合将会显示出平方级的性能指标。JDK2之前的String散列函数至多只检查16个字符,从第一个字符开始,在整个字符串中均匀选取。对于大型集合,该散列函数表现出了病态行为。 不要规定散列函数的细节
Java平台类库中的许多类,String、Integer、Date等都可以把hashCode方法返回的确切值规定为该实例值的一个函数。但是这并不是一个好注意,这会严格地限制了在将来的版本中改进散列函数的能力。如果没有规定散列函数的细节,那么当你发现了它的内部缺陷时,就可以在后面的发行版本中修正它,确信没有任何客户端会依赖于散列函数返回的确切值。返回搜狐,查看更多
责任编辑:
转载地址:https://blog.csdn.net/weixin_30679649/article/details/114785046 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
