深度学习基础上篇(3)神经网络案例实战
https://www.bilibili.com/video/av27935126/?p=1
第一课:开发环境的配置
Anaconda的安装
库的安装
Windows下TensorFlow的安装
Jupyternotebook 可视化方便,但不能debug
第二课:IDE的使用
PyCharm
Eclipce的下载安装环境配置
第三课:一个简单的神经网络的代码实现
使用jupyternotebook演示敲代码的过程
例子:只有一个隐藏层的神经网络
不懂:
1.正常传播和反向传播的计算 ,为什么反向计算是x*(1-x)
2.反向:传播时,delta 和 error计算时表示的意义。
第四课:对比一下神将网络和softmax区别(说明神经网络的强大)
Softmax分类器的表现:
将一个平面线性(直线)分类为3个区域
神经网络的表现:可以表现出非线性(曲线)分类
容易过拟合,体现在训练时表现很好,测试时就表现不理想了。
少量的异常点将严重影响,导致过拟合。
第五课:图片分类,多分类问题
5000张训练图片,用来找到最好的w和b的值;
500张测试图片
十种分类,用softmax分类函数解决多分类问题。
视频老师的QQ:474241623
还有第六课课也没有看完
2018年8月12日星期日
深度学习基础下篇
第一课:卷积神经网络的应用
分类
推荐(像是图片推荐)
检测(在哪里,是什么)
语义分割(图像分割)
自动驾驶
人脸检测(找关键点)
人的姿势判断,找人的关节
医学疾病识别
汉字识别
路标识别
读图片内容 语义
图片合成(CVPR) app是Prisma
(内容加风格 产生新的图片)
第二课:卷积神经网络
复习神经网络的概念:
全连接层
激活函数
反向传播 loss值 w2 w1 w0
梯度计算 梯度的反向传播
第三课:卷积神经网络(激活之前需要卷积,激活之后需要池化)
组成:
input输入层
conv卷积层(增加了)
Relu激活函数
pool池化层(增加了) 西瓜书称之为 采样层
FC全连接层
什么是卷积?特征提取的过程
Filter 过滤器/核函数:提取特征(视频老师称filter为提取特征的 小助手)
卷积操作的作用:用来提取特征;卷积次数少时提取的特征称为低微特征,多次之后就称为高维特征(一种说法)
对图像的相同区域提取多次不同的特征,得到多个特征图,作为一次卷积的结果。
卷积的计算过程,图片是一个三维的数据,一张原始图分解成有RGB的三张图,卷积计算的过程中每张图之间是单独处理的;图片中的像素点就是输入x;
感受野(每次处理的一小块区域)
卷积之后图片的大小
感受野是一个小区域。
特征图的大小计算公式(需要其保持不变):(w-f)/s +1
w:原始图片的宽度
f:感受野的宽度
S:感受野右移的步长
第四课:特征图的生成过程,pad的设置和使用
增加pad(在原始图片周围增加一圈或者多圈0值,相当于增加原始图片的宽度和高度),保证多次卷积之后,特征图的大小保持不变。
注意:设置的感受野大小和步长必须合理,即使计算公式结果是整数;
通常的取值:感受野的大小 周围0圈的大小对应关系
F=3时,pad=1
F=5时,pad=2
F=7时,pad=3
卷积中的参数共享原则:提取每一层特征图时的权重w和b都是相同的。w的个数是感受野中点的个数*3(RGB三层都需要设置权重w)*特征图的层数;
一次卷积操作时,会将RGB三层原始图片,转成多层特征图。对于同一个感受野,不同的RGB层和不同的特征层,对应不同的权重;但对同一个感受野,不同的RGB使用相同的b,不同的特征图使用不同的b;
目的是减少参数w和b的数量,如果每一个感受野计算的每一个特征成参数全部不相同的话,参数太多,计算难度急剧增加,且容易过拟合。
第五课:池化层
卷积层不改变图片的大小;改变图片的深度(将RGB3层,转正多层特征层)
池化层改变图片的大小;不改变图片的深度;
例如:
maxpooling:提取其中最大那个特征作为新的特征(通常是将4个中提取一个最大的)。
Avgpooling:(提取平均的特征值),基本会使用这种方法了。
整体的神经网络过程通常是:
多次循环conv relu conv relu pool之后再全连接处理
第六课:case study 论文举例讲解 卷积 池化 全连接
AlexNet Krizheskuu et al.2012
感受野大小:11*11 5*5
池化的大小:
VGGNet Simonyan and Zisserman,2014
感受野大小:3*3 更小提取的特征更加细腻
池化的大小:2*2中提取一个
深度残差网络(深度学习的趋势,他的层数越多,效果越好,计算量却不会明显增加) 可以达到120层
全连接层的参数远多于前面卷积时的参数。池化使不使用参数的。
第七章:卷积神经网络 应用实例
分类和定位(classification and location )
应用在:
对图片分类
对图片中的对象分类并定位
目标检测(detection) faster CNN
分割
用回归来定位,通过不断找到更加合适的区域(方框)来定位;
实现分类和定位的过程:
最后是两个全连接层, 用来分类、回归定位
步骤1:训练一个分类模型(alexNet, VGG , GoogleNet)
参数初始化:第一种是高斯初始化,自己训练,通常很慢;第二种是fine tune 直接使用别人训练好的参数,只需要改变最后的全连接层的参数。
步骤2:更具自己的实际需求更改全连接层。
步骤3:训练,使用SGD随机梯度下降 和L2 loss值的计算(如使用欧式距离)来评估训练效果。
步骤4:测试,同时得到分类和定位。
回归模块添加在哪里?卷积层之后还是全连接层之后,效果通常差别较大,试了才知道效果。
应用在人体关键点检测 pose estimation
概念:滑动窗口Sliding window 。特点:思路简单,计算量大
取不同的scale 大小变换,进行滑动窗口测试。因为在不同图中的大小会不同,所以需要使用不容的窗口大小来滑动。
不同的卷积神经网络在imageNet 中的表现:
AlexNet2012 < overFeat 2013 < VGG < resNet(2015深度残差网络)(有一个经典的例子是134和152层)
第八章:物体检测
RCNN
Region proposals 区域建议, RCNN的处理方法是一张图提取2K个框再处理。
实现的方法:Selective serach,将相邻的相似的区域归为一种,最后就将一张图分割层多个对象。
RCNN 2014是 物体检测的开篇之作
套用RCNN的步骤:
步骤1:fine tune ,使用别人的卷积参数
步骤2:更改最后的全连接层(改成我们自己要的分类数量,改成20个分类)
步骤3:卷积提取特征,将池化处理后的数据存储在磁盘上,
步骤4:从磁盘上提取特征,再使用分类方法。使用SVM分类20个种类。
步骤5:从磁盘上提取特征,再使用回归定位。
数据集:data set
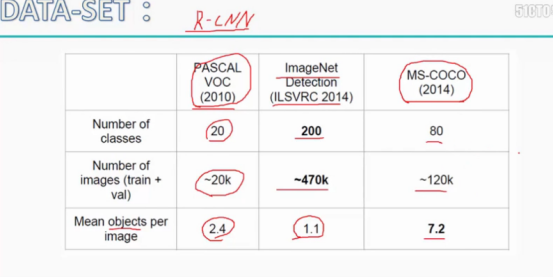
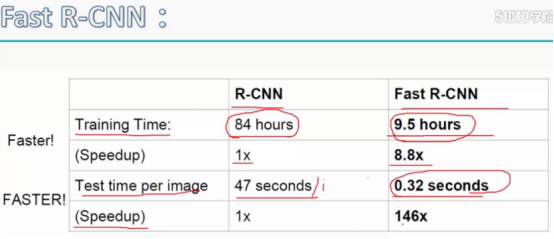
RCNN 的缺点:
测试时间慢
特征先存储后提取来分类和定位
Fast R-CNN 改进:1.卷积共享 2.将所有操作整合在一起(end to end),使用两个全连接层,分别在实现分类和定位(集成在了神经网络中,CNN是分成两段实现的);
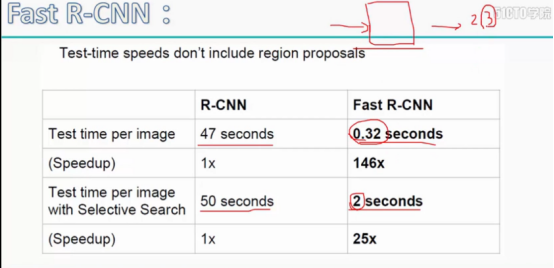
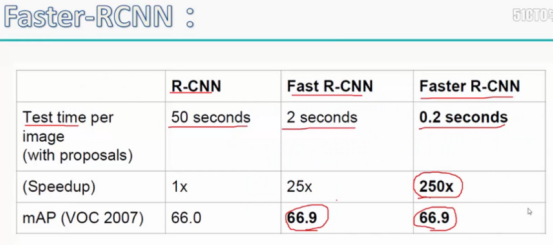
测试一张图片需要2.3秒。
Fater RCNN https://www.bilibili.com/video/av28005781/?p=8
将分类的特征框提取Selective serach改进
Fast cnn 是将Selective serach和卷积网络 单独处理
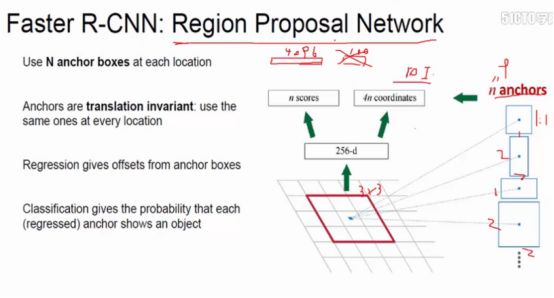
Faster cnn 将特征提取Region proposals和卷积集成在一起,之后再分类处理,更快。
Faster RCNN : region Proposal network 在CNN之后,利用卷积层数据提取候区域。 将每一个框变换成9种不同大小的框来处理。

第九课:技巧:设计神经网络的技巧,注意事项
2018年8月13日星期一
感受野大小的变化
连续的多次卷积之后,图层的大小不会改变,但是每一个像素点能表示的原始图片的信息更多。
得到一个7*7的感受野的方法(一个点表示原始图像的49个像素点)
第一种模型:直接卷积一次,用7*7的感受野(卷积一次),7*7=49个参数
第二种模型:用三次3*3的卷积(连续卷积3次),3*3*3=27个参数
第二种模型的优势:参数更少,非线性更强(3个激活函数ReLU)
深度残差网络:先1*1卷积,再3*3,再1*1。
Pooling之后图片会变小,可能会丢失一些信息,通常会通过增加pool之后的层数来弥补可能造成的不必要的信息丢失。(常见的的层数翻倍)
第十课:技巧:数据增加,扩展数据
原因:深度学习,数据越多越好;数据越多,模型越不容易过拟合。
图片处理方法:
- 图片翻转(左右镜像变化)
- Random crops/scales 图片随机裁剪/大小变换,模拟对面出现遮挡的情况
- 平移
- 旋转
- 拉升
- 压缩
- ……
图片处理是将多种方法混合处理,随机选择做种方法,随机选择多种具体的处理参数(如左右平移的距离大小,旋转角度)
第十一课:技巧:transfer learning
目的/原因:节约大量训练时间,别人通常都是训练一两天的到的;
模型:数据量不够时。使用公认的比较好的模型(要求别人的训练数据集和自己的相识,如人脸识别)来使用,
步长:Transfer learning 时,自己只需要微调,步长的设置通常是正常设置时的0.1倍,或者更小,因为只需要在别人的基础上微调参数。
自己的数据越大,借用的模型越匹配越好,只需要Finetune a few layers 更改一点;
数据足够,但模型不相似,就大改别人的模型 finetune a larger number of layers;
模型刚好,但数据不够时,use liner classifter on top layer;
模型在哪里找?
Model zoo
第十二课:框架 caffe
caffe.berkeleyvision.org
