Discovering Word Senses from Text
第一章 简介
使用词形的词义在很多应用中具有重要的作用,这些应用包含信息检索、机器翻译、问答系统。在之前的方法中,词义通常使用人工构建的词典建立。这种做法使词义有一些不利之处。首先,人工建立的词典通常包含罕见的词义。第二,这些词典缺失许多领域限定的词义。
一个未知词的意思通常可以从它的上下文中推断出来,这种想法是源于不同的词出现在相同的上下文中更趋向于具有相似的词义。这就是Distributional Hypothesis。
本论文介绍一种叫做CBC(Clustering By Committee)的聚类算法。在这种聚类算法中,聚类的几何中心是聚类成员的子集的特征向量的平均数。这个子集被看作是committee,committee其他的元素是否属于这个聚集。通过仔细选择committee成员,几何中心的特征趋向于成为典型的目标类的特征。
论文中也提出一种自动评估词义发现的聚类算法。使用WordNet来度量准确率和召回率。
第二章 相关工作
聚类算法通常被划分为两类:层次聚类和划分聚类。在层次聚类算法中,聚类是通过反复合并最相似的聚类建立的。这类算法根据度量聚类相似度的不同又分为不同的算法。在单链路聚类(single-link clustering)算法中,两个聚类的相似度是它们最相似成员的相似度。在完整的链路聚类(complete-link clustering)算法中,两个聚类的相似度是它们最不相似成员的相似度。在平均链路聚类(average-link clustering)算法中,两个聚类的相似度是两个聚类中所有pair相似度的平均数。这些算法的复杂度是O(n2logn),n是待聚类元素的个数。
Chameleon是采用动态模型(dynamic modeling)的层次聚类算法。当合并两个聚类时,需要考虑两个聚类的所有pair相似度的和(类似平均链路聚类)。这种方法的一个缺点是非常相似的单pair元素可能造成两个聚类的不恰当合并。一种代替的想法是考虑考虑pair相似度数量超过一个阈值。然而,当有很多相似度恰好超过阈值一点点的时候,这种方法可能造成不可取的合并。Chameleon结合两种方法。
K-means聚类通常使用在大量的数据集合上,因为它的复杂度是n的线性函数,n是待聚类的元素数量。K-means是划分聚类的一种。K-means算法迭代过程:1.计算每个元素到K个聚类几何中心的相似度,选择相似度最高的作为它的类别,2.重新计算各个聚类的几何中心。K-means算法的复杂度是O(K×T×n),因为初始的几何中心是随机选择的,聚类结果可能在质量上不同。一些初始几何中心可能导致慢的收敛速度或者差的聚类质量。二等分K-means,是K-means的一个变种。初始时只有一个包含所有元素的聚类,迭代选择最大的聚类,并把它划分为两个聚类。二等分聚类算法可以看做是对数据使用α次K=2的K-means。
混合聚类(Hybrid clustering)算法集合层次聚类和划分聚类。试图得到具有层次聚类的高质量和划分聚类的高效率。
CBC是UNICON的一个派生。
第三章 词的相似度
使用特征向量来表示每个词。每个特征关联到一个该词出现的上下文。特征的值是点式互信息(pointwise mutual information,PMI)。点式互信息是一种广泛用于分析事件相关的方法,具有针对离散随机变量中相对稀疏的数据分布进行分析的特点。PMI的定义公式如下:
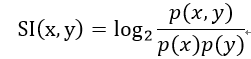
公式体现了二元关系,反应了x和y的共现频度。
令c是一个context,Fc(w)是词w出现在上下文c中的频次。上下文c和词w的点式互信息miw,c定义为:

其中![]() ,是所有词和它上下文出现频次的和。显然,mi越大,说明w和c共现的可能性越大。互信息的一个出名的问题是它偏袒出现频次少的词和特征。这里给mi乘一个折扣因子。
,是所有词和它上下文出现频次的和。显然,mi越大,说明w和c共现的可能性越大。互信息的一个出名的问题是它偏袒出现频次少的词和特征。这里给mi乘一个折扣因子。

计算两个词wi和wj的相似性使用互信息向量的余弦协同系数(cosine coefficient):
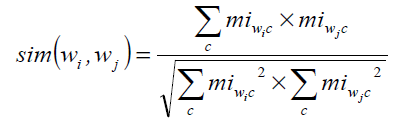
第四章 算法
CBC由3个阶段组成。在阶段1,计算每个元素的最相似的k个元素。在本论文的实验中,采用k=10。在阶段2,构建一些紧密的聚类,每个聚类的元素构成一个committee。算法试图构建尽可能多的committee,满足的条件是新构建的committee和已经存在的committee不是很相似。如果不满足这个条件,新committee简单的被抛弃。在阶段3,每个元素e被分配给和它最相似的聚类。
4.1 阶段1:寻找最相似的元素
计算为每对元素计算相似度,构建完全的相似度矩阵明显是二次方的。然而,事实上特征向量是稀疏的,通过索引特征,可以通过特征检索到具有这个特征的元素。为了计算元素e的最相似的K个元素,首先,对元素e的特征按照点式互信息排序,其次,只考虑特征的一个子集,子集中的特征具有最高的互信息,最后,计算元素e和具有子集中特征的其他元素的相似度。因为,大的互信息特征趋向于不在很多元素中出现,我们只需要计算元素对组合的一小部分。使用这种启发,相似词具有低互信息的特征才会被忽略。然而,在实验中,这个并没有对聚类质量造成显著影响。
4.2 阶段2:寻找committees
在阶段2中,递归寻找紧密的聚类,这些聚类在相似空间中是分散的。在每个递归的步骤中,算法寻找一个紧密聚类集,叫做committee,并且识别没有被任何committee覆盖的剩余元素。这里的覆盖(cover)是指,一个元素到一个committee的几何中心的相似度超过一个阈值。算法递归的在剩余元素寻找更多的committee。算法的输出是所有递归步骤中寻找到的committee的并集。算法的详细步骤如图。
输入:待聚类元素的列表E,通过阶段1计算得到的数据库S,阈值θ1和θ2。
Step1:对每个元素e∈E
使用平均链路聚类算法对在S中与e最相似的元素聚类。
对每个被发现的聚类c,计算得分函数:|c|×avgsim(c),其中|c|是聚类c中元素的数量,avgsim(c)是c中每对元素相似度的平均数。
保存具有最高得分的聚类到列表L中。
Step2:对L中的聚类根据得分降序排列。
Step3:令C是
对每个聚类c∈L按照排序的顺序
计算c的几何中心,几何中心的计算方法是对元素的频次向量取平均数,并计算几何中心的互信息向量,计算方法和计算单个元素的相同。
如果c的几何中心的相似度和已经加入到C中的committee的几何中心的相似度低于一个阈值θ1,那么把c加入到C中。
Step4:如果C为空,完成,返回C。 //为了递归的终止
Step5:对每个元素e∈E
如果e和在C中的每个committee的相似度低于阈值θ2,把e加到剩余列表R中
Step6:如果R为空,完成,返回C。
否则,返回C和递归调用阶段2返回值的并集。递归调用使用的参数是R,S,θ1,θ2。
输出:committee的列表。

在步骤1中,得分函数反应更大更紧凑的聚类。步骤2为步骤3提供高质量的聚类。步骤3中,只有和其他committee相似度低于θ1的聚类才被加入到committee中,我们把θ1设置为0.35,步骤4结束递归当在之前的步骤中没有发现committee。步骤5中发现剩余元素,如果没有发现剩余元素那么结束算法,否则进行递归。
4.3 阶段3:把元素分配到聚类
在阶段3,每个元素e被分配到和它最相似的聚类中(有多个),使用下面的步骤:
令C是聚类的列表,初始为空。
令S是和元素e相似度排前200的聚类。
While S 不为空{
令c∈S是和e最相似的聚类
如果similarity(e,c)<σ
退出循环
如果c和C中的其他聚类不相似{
把e分配给c
删除e的和c重叠的特征
}
从S中删除c。
}

当计算聚类和元素(或者其他聚类)的相似度,使用committee成员的几何中心(觉得计算方法应该和阶段2中一样)。这个阶段类似于K-means,每个元素被分配给和它最近的中心。与K-means不同的是,聚类的数量不是固定的,聚类中心不变。
这个算法发现词义的关键是,当一个元素分配到一个聚类c时,e和c特征的交集将从e中删除。这使得CBC发现低频的词义并避免发现重叠词义。
4.4 和UNICON对比
UNICON也是使用相似元素的小集合构建中心,与CBC中的committee相似。
CBC和UNICON第一个不同点是UNICON只保证committee之间没有重叠的成员,committee之间的中心可能仍然很近。UNICON通过合并这样的聚类来解决这个问题。
CBC和UNICON另一个主要的不同点是CBC的阶段3。当某个词有主要词义时,UNICON难发现词的其他词义。
5.1 WordNet
WordNet是组织成图的电子词典。每个节点称为一个同义词集(synset),表示一个同义词的集合。在synset之间的边表达下位词/上位词关系。如图,为一个synset分配的数,代表,随机选择一个名词,名词属于这个synset或者这个synset之下的synset的概率。这个概率并不在WordNet中,需要使用语料来构建。在统计synset频次时,在WordNet低层的频次很稀疏。使用平滑的方法是,假设给定父节点,兄弟节点时等可能的。
Lin定义的在WordNet中,两个synset的相似性。
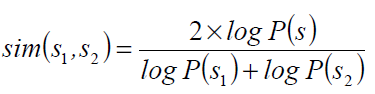
其中s是s1和s2的共同最近祖先。

5.2 准确率
对每个词,CBC输出一个聚类的列表。每个聚类应当关联到一个词义。准确率是输出聚类实际表征词义的比例。
为了计算准确率,需要定义怎么聚类才算关联到词义。为了自动决策,把聚类映射到WordNet词义。
令S(w)是词w在WordNet中的词义(每个词义是包含w的synset)。定义simW(s,u)为一个synset和词u的相似度。
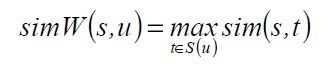
令ck是聚类c的前k个成员,排名是按照和committee中心的相似度。定义s和c的相似度。
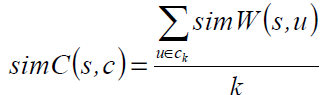
假设聚类算法把一个词w分配到一个聚类c,我们说c关联到一个正确的词义当

在实验中,取k=4,θ为变量。词w在WordNet中的关联到c词义是:

多个聚类可能分配到同一个词义,这种情况只计算他们其中的一个作为正确的。
5.3 Recall
Recall表述的是正确的词义和实际正确词义的比例。显然,没有方法知道词的全部词义。为了解决这问题,集合了多个算法的结果作为目标词义集。对于一个词w,对有所算法得到的正确词义取并集作为w的词义。
总Recall是计算每个词的recall的平均数得到的。
5.4 F-值
F值为:

