本文共 7058 字,大约阅读时间需要 23 分钟。
1.1 爬下12306--爬取信息
1.1爬取信息
对于上图的fetch_sh-bj.sh脚本程序,也许现在你还看得一头雾水。
但请不要着急,熬过了黑夜就可以见到黎明的曙光。 先喝一口24K纯度的凉白开压压惊,下面听我为你娓娓道来关于fetch_sh-bj.sh前世今生。 前文提到fetch_sh-bj.sh一共可以分为三部分。 本小节我们先聊聊和爬取信息相关的那一部分—curl。 curl命令可以分为三段: 第一段: --insecure 选项
insecure选项用于告知curl不对网站的证书做校验。
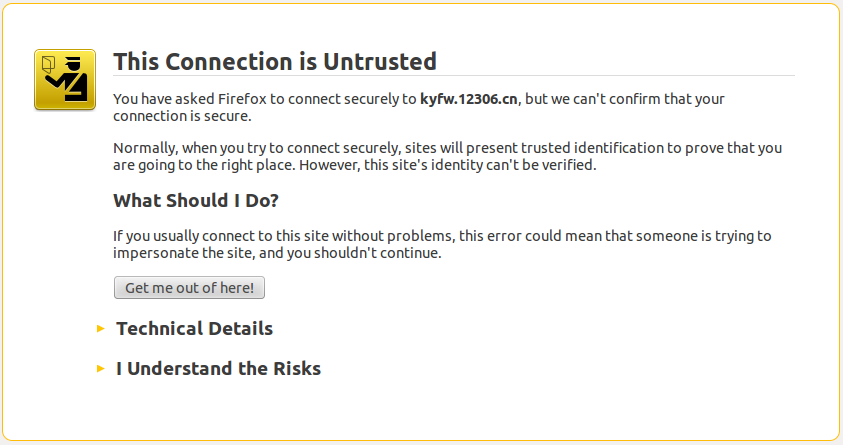
curl在爬取订票信息时,干着和浏览器类似的事。
如果不指明insecure选项,则会显示当前网页认证失败。 读到这里,爱钻牛角尖的读者一定会问:“可不可以不使用insecure选项,并且curl依然可以成功认证?“
嗯,这是个好问题。 关于这个问题,此处先剧透一下结论,在后文会给出详细解释。 结论就是“YES”。 第二段: --user-agent选项
user-agent选项的值为:
"Mozilla/5.0 (X11; Linux i686; rv:38.0) Gecko/20100101 Firefox/38.0" 网页抓取的基本原理就是模拟浏览器向服务器请求数据。
在FireFox中打开网页时,浏览器向服务器发送类似"Mozilla/5.0 (X11; Linux i686; rv:38.0) Gecko/20100101 Firefox/38.0"的user-agent。 不同浏览器版本,该值也许略有差异。 在这个例子中,curl就是模拟浏览器从服务端获取数据,所以我们添加了这段用于欺骗服务器的user-agent声明。 细心的读者也许发现了,在这个例子中,即使不添加user-agent也是可以运行的。
不同版本该值也许略有差异。
那是不是user-agent完全没用呢?
也不尽然,只是在本例中没有体现出来而已。 客户端一般通过user-agent向服务端声明自己。 服务器根据这个user-agent申明,判断客户端浏览器类型。 针对不同的浏览器,服务器给出不同的响应。最简单的例子就是手机上浏览器和笔记本上的浏览器。
不管屏幕尺寸多大的手机,与笔记本相比还是很小的。 所以同一个网页在手机上和在笔记本上的呈现效果绝对是不一样的。 手机也不一定总是处在wifi环境(土豪自行略过)。 所以对相同的网页请求,服务器发给手机的数据量肯定比发给笔记本的数据量少。举例说明,我笔记本上FireFox的user-agent是这样滴:
同时我手机上UCWeb的user-agent是这样滴:
我们分别假装自己是FireFox和UCWeb下载百度首页,并存文件如下图所示。
从文件量可以看出FireFox共下载了96K的数据,而UCWeb下载了40K的数据直接使用浏览器打开ff_baidu.html和uc_baidu.html可以发现两者的展示效果亦不相同。
ff_baidu.html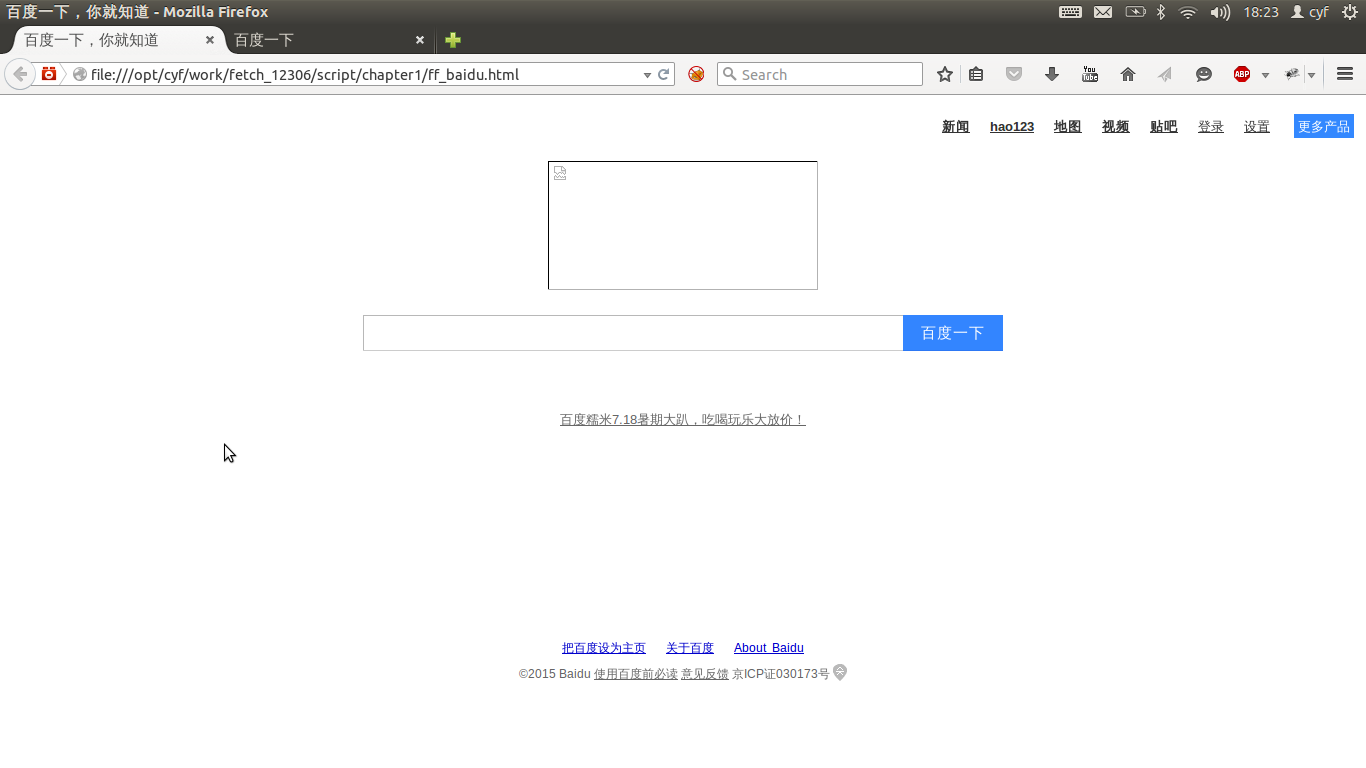 uc_baidu.html
uc_baidu.html 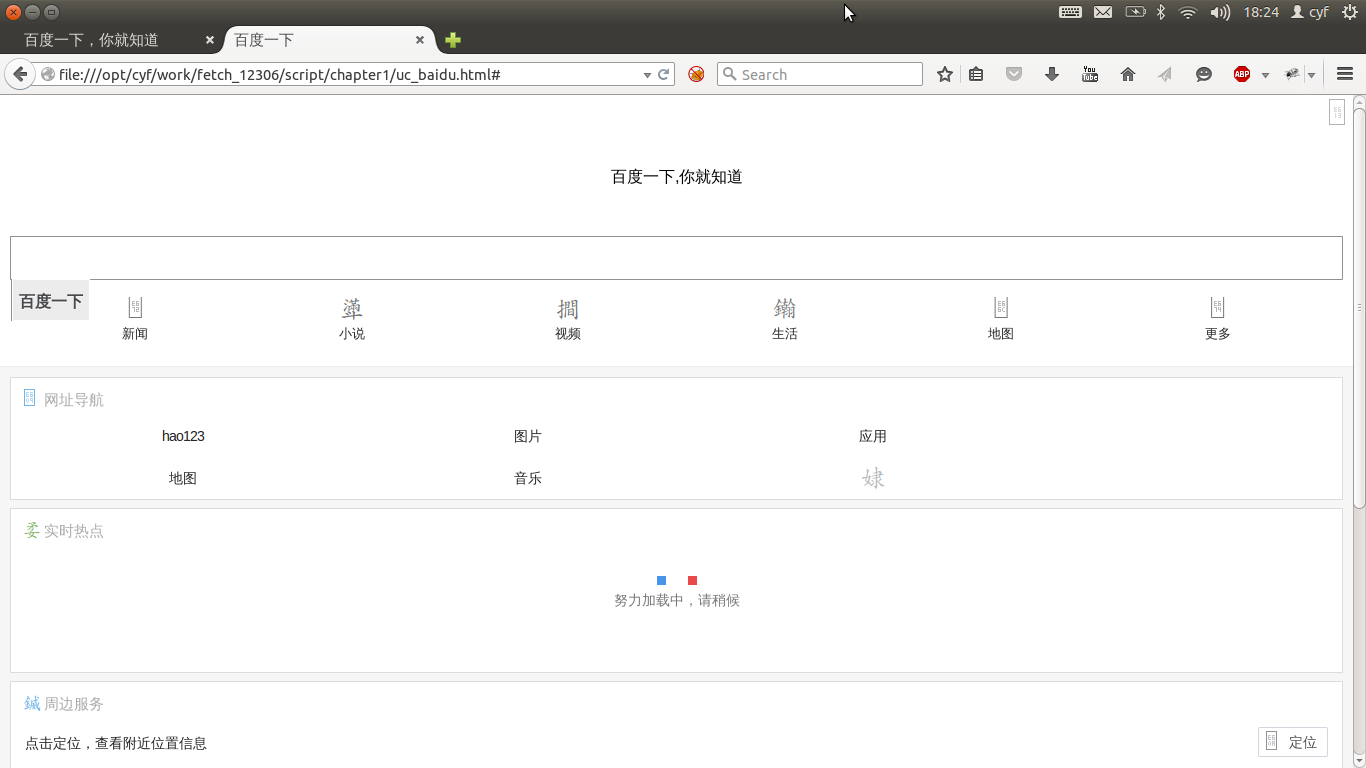
读到这里,也许有些读者会有这样的疑问,既然服务器对不同的user-agent可能给出不同的响应,那么我怎么知道我自己浏览器的user-agent呢?
嗯,这也是个好问题。
此处先给出一种解决方案,后文继续给出其它解决方案。 最简单的方法就是打开。 该网页可显示当前浏览器的user-agent。 该网站同时列出了常用设备的user-agent。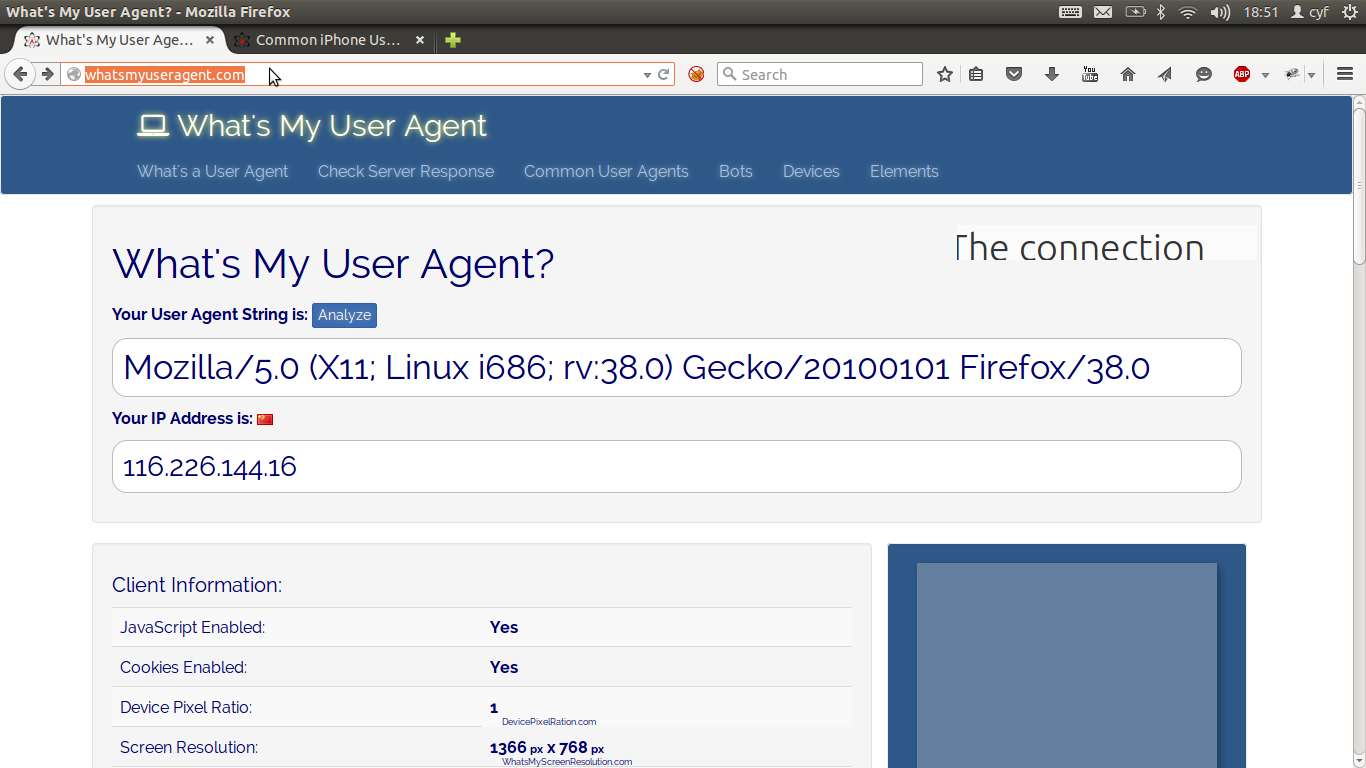
第三段 网站URL
聪明如你的读者一定能猜到第三段其实就是请求订票信息的URL
而且你也一定猜到queryDate=$1,中的$1就是我们手动敲入的日期。但是,你一定有这样几个小小的疑问:
嗯,这些确实是问题,而且这些问题的解决手段是相同的,都是关于如何利用好现有工具的问题。
换位思考一下。
当使用笔记本在浏览器查订票信息时,浏览器也一定向12306网站发送了相应的查票请求,只是浏览器把这些东西放在后台完成,没有对用户展现而已。如果我们有办法把浏览器查票时与服务器交互的所有操作均展示出来,那么我们是否可以解决以上几个疑问呢?
借助FireFox自带的开发者工具或者下载Firebug网页调试插件,可以把浏览器与服务器交互所有信息一览无余的展示给用户。
Chrome、Opera、IE等其它浏览器,也提供类似的网页调试工具。 本文使用FireFox自带的开发者工具来解决上述几个疑问。在Firefox浏览器中打开12306查票页面
1. 点击浏览器右上角的“Open menu” 2. 选择“Developer”选项下的“Network”; 或者点击“Tool”菜单,选择“Web Developer”下的“Network”选项,打开网页调试工具Open menu -> Network
Tools->Web Developer->Network
网页调试工具
随意选择“出发地”、“目的地”和“出发日”,点击查询。
凭借强大的调试工具,Network将上述操作过程中,浏览器和12306服务器之间交互的数据均清晰的呈现出来。聪明的读者一定注意到了,当我们在页面上点击“查询”时,Network立刻多出一条信息:”200 GET query?prupose_codes=ADUILT&query...“。
这条信息就是查询订票信息时,浏览器向服务器发送的数据,点击该条信息,可以在右边的小窗口中得到更为详细的描述,包括Headers、Cookies、Params等信息,如下图所示。
车票查询
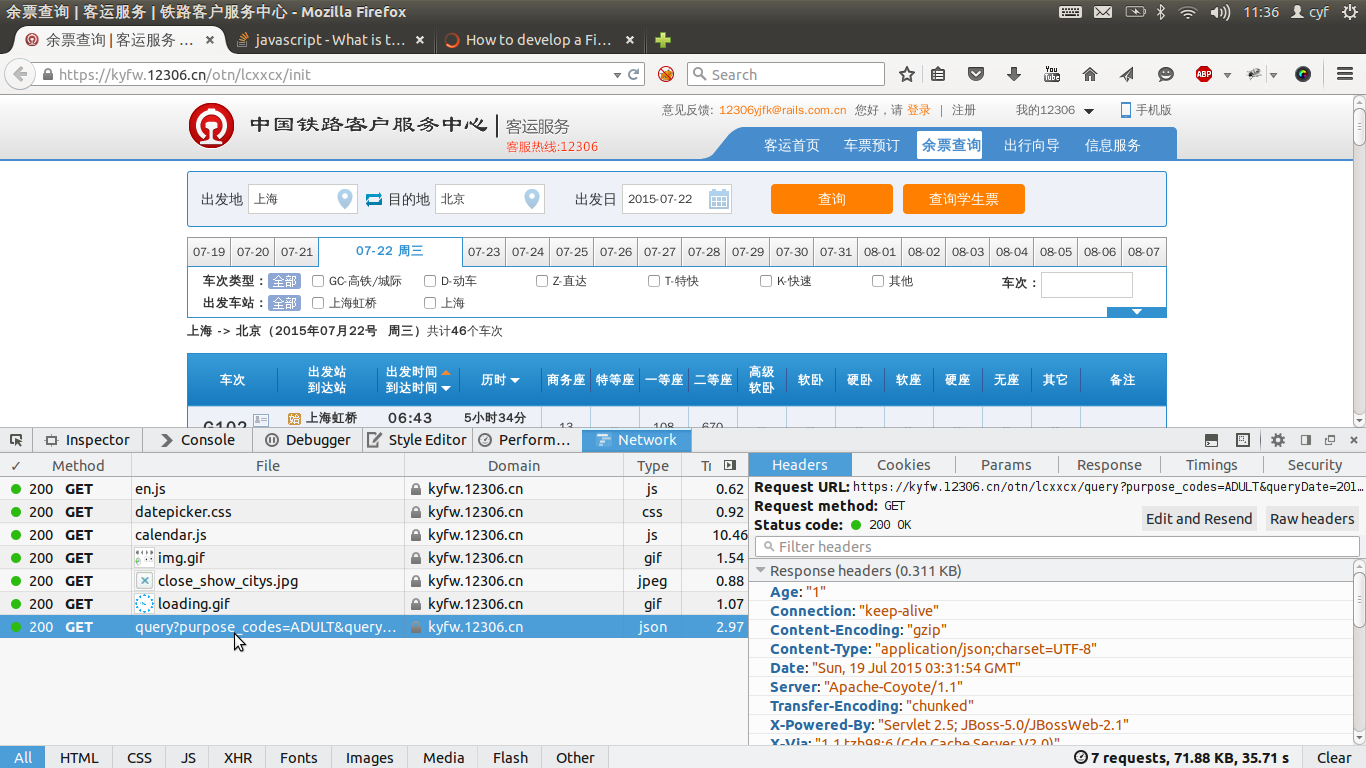
在Headers选项卡下,展开Request Headers,可以查看浏览器向服务器发送查票请求时的Header信息,里面包含User-Agent。
这是获得User-Agent的第二种方法。Headers选项卡中的Request URL即为第1个小疑问的答案。
选择Params选项卡,即可得到请求订票信息时,浏览器向服务器发送的参数。
这些参数放在URL的“?”后面,并使用“&”区分不同参数。浏览器向服务器传递擦参数时,常用的方法有两种:GET和POST。
GET方法传递的参数直接加在URL后面,一般用于传递公开信息。
POST发则由浏览器在后台发送,一般用户传递用户名和密码等非公开信息。 Params选项卡中内容即为第2个和第3个小疑问的答案:SHH代表上海,BJP代表北京。那么如何解答第4个小疑问呢?
也许你会说,打开Network,在页面上分别选择“深圳”和“西安”,点击“查询”,不是可以在Network中显示吗?嗯,这确实是个临时性的方法。
但是12306网站上一共有上千个动车站点,我们总不能每个站点都用这么土的方法获取吧? 这样做即不准确,还浪费时间。 所以一定有更优雅的,更高端的方法让我们一次性获得所有站点名称和代号。让我们再次拿起Network这个调试利器。
可以发现在选“出发地”和“目的地”时,只有第一次操作时,浏览器用GET方法向12306网站请求一个名为“close_show_citys.jpg”的图片。 吐槽一下,city的复数形式是cities不是citys。 之后无论如何修改“出发地”和“目的地”,只要不“查询“,浏览器均不与服务器发生任何数据交互。据此可以断定,站点名称和站点代号对应关系的数据在用户打开查票网站()时传入浏览器。
所以之后更改站点操作就不需要从服务器再次获取站点名称所对应的站点代号了。因此我们需要看看页面打开时,服务器向浏览器发送了哪些数据。
点击Network右下角的clear,再点击刷新。 在Network的一堆数据中,我们注意到有这么一条信息:获取站点名称及代号
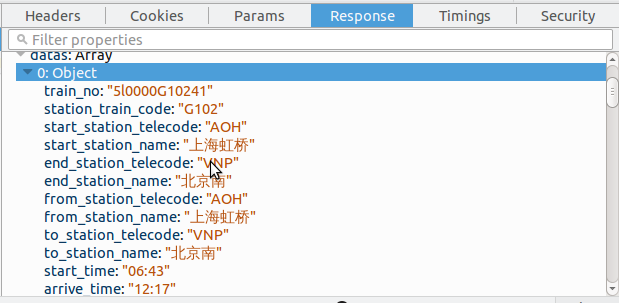
点击这条信息,在右边展开的小窗口中选择“Response”,这里就有我们想要的信息,所有的站点以及站点所对应的代号。

现在,我们差不多解答了第4个小疑问。
为什么是差不多呢? 因为直接在Response里看不舒服。 我们应该把这些信息提取出来,做成一张一一对应的表。 一列是站点名词,一列是站点代号。 此处使用Bash脚本完成此事。fetch_station_name.sh
到此位置,我们完成了对fetch_sh-bj.sh脚本的curl命令的解读。
相信读者可以据此快速修改出fetch_sh-sz.sh和fetch_sh-xa.sh了。 在结束本小节前,我们先看看crul命令的最终输出结果,读者可以在Network的Response查看,或使用文本编辑器打开sh-bj_2016-05-14.txt查看。curl命令响应
转载地址:https://blog.csdn.net/hzp666/article/details/79213641 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
