本文共 9676 字,大约阅读时间需要 32 分钟。
前言
通过《》的通讯模型和数据结构,redis为我们提供了以下几种功能。
Redis协议
RESP 是redis客户端和服务端之前使用的一种通讯协议《》。
public static void main(String[] args) throws IOException { Socket socket = new Socket("localhost",6379); OutputStream os = socket.getOutputStream(); // *2 表示2个参数 // $4 表示第一个参数长度为4, keys // $1 表示第二个参数长度为1, * os.write("*2\r\n$4\r\nkeys\r\n$1\r\n*\r\n".getBytes()); os.flush(); InputStream is = socket.getInputStream(); BufferedReader br = new BufferedReader(new InputStreamReader(is)); String info = null; while((info = br.readLine())!=null){ System.out.println("我是客户端,服务器返回信息:"+info); } }// 控制台输出: // 我是客户端,服务器返回信息:*2// 我是客户端,服务器返回信息:$4// 我是客户端,服务器返回信息:list// 我是客户端,服务器返回信息:$3// 我是客户端,服务器返回信息:foo 管道Pipelining
pipeline原理就是将命令“批量提交”。其通过减少客户端与 redis 的通信次数来实现降低往返延时时间,而且 Pipeline 实现的原理是队列,而队列的原理是时先进先出,这样就保证数据的顺序性。但不保证原子性。
需要注意到是用 pipeline 方式打包命令发送,redis必须在处理完所有命令前先缓存起所有命令的处理结果。打包的命令越多,缓存消耗内存也越多。所以并不是打包的命令越多越好。
public static void main(String[] args) throws IOException { Socket socket = new Socket("localhost",6379); OutputStream os = socket.getOutputStream(); // 使用pipeline分别发送keys * 和 get foo命令 os.write("*2\r\n$4\r\nkeys\r\n$1\r\n*\r\n".getBytes()); os.write("*2\r\n$3\r\nget\r\n$3\r\nfoo\r\n".getBytes()); os.flush(); InputStream is = socket.getInputStream(); BufferedReader br = new BufferedReader(new InputStreamReader(is)); String info = null; while((info = br.readLine())!=null){ System.out.println("我是客户端,服务器返回信息:"+info); } } // redis对2命令的处理结果统一返回,控制台输出: // 我是客户端,服务器返回信息:*2// 我是客户端,服务器返回信息:$4// 我是客户端,服务器返回信息:list// 我是客户端,服务器返回信息:$3// 我是客户端,服务器返回信息:foo// 我是客户端,服务器返回信息:$4// 我是客户端,服务器返回信息:yoyo 事务
- MULTI命令,将打开事务标识,。除EXEC,DISCARD,WATCH命令服务器不会立即执行,而是将这些命令放入到一个事务队列里面,然后向客户端返回一个QUEUED回复。
注意:事务是客户端维度的,如果多个用户使用一个Socket进行事务混用,将失败
typedef struct multiState { multiCmd *commands; //存放MULTI commands的数组 int count; //命令数量} multiState;typedef struct multiCmd { robj **argv; //参数 int argc; //参数数量 struct redisCommand *cmd; //命令指针} multiCmd; - EXEC 命令负责触发并执行事务中的所有命令
void execCommand(client *c) { int j; robj **orig_argv; int orig_argc; struct redisCommand *orig_cmd; int must_propagate = 0; //同步持久化,同步主从节点 //如果客户端没有开启事务标识 if (!(c->flags & CLIENT_MULTI)) { addReplyError(c,"EXEC without MULTI"); return; } //检查是否需要放弃EXEC //如果某些被watch的key被修改了就放弃执行 if (c->flags & (CLIENT_DIRTY_CAS|CLIENT_DIRTY_EXEC)) { addReply(c, c->flags & CLIENT_DIRTY_EXEC ? shared.execaborterr : shared.nullmultibulk); discardTransaction(c); goto handle_monitor; } //执行事务队列里的命令 unwatchAllKeys(c); //因为redis是单线程的所以这里,当检测watch的key没有被修改后就统一clear掉所有的watch orig_argv = c->argv; orig_argc = c->argc; orig_cmd = c->cmd; addReplyMultiBulkLen(c,c->mstate.count); for (j = 0; j < c->mstate.count; j++) { c->argc = c->mstate.commands[j].argc; c->argv = c->mstate.commands[j].argv; c->cmd = c->mstate.commands[j].cmd; //同步主从节点,和持久化 if (!must_propagate && !(c->cmd->flags & CMD_READONLY)) { execCommandPropagateMulti(c); must_propagate = 1; } //执行命令 call(c,CMD_CALL_FULL); c->mstate.commands[j].argc = c->argc; c->mstate.commands[j].argv = c->argv; c->mstate.commands[j].cmd = c->cmd; } c->argv = orig_argv; c->argc = orig_argc; c->cmd = orig_cmd; //取消客户端的事务标识 discardTransaction(c); if (must_propagate) server.dirty++;handle_monitor: if (listLength(server.monitors) && !server.loading) replicationFeedMonitors(c,server.monitors,c->db->id,c->argv,c->argc);} - watch/unwatch/discard命令,请参考《》
redis事务的ACID特性
- 原子性(Atomicity):单个 Redis 命令的执行是原子性的,但 Redis 没有在事务上增加任何维持原子性的机制,所以Redis 事务的执行并不是原子性的。 如果一个事务队列中的所有命令都被成功地执行,那么称这个事务执行成功。另一方面,如果 Redis 服务器进程在执行事务的过程中被停止——比如接到 KILL 信号、宿主 机器停机,等等,那么事务执行失败。当事务失败时,Redis 也不会进行任何的重试或者回滚动作。
- 一致性(Consistency):Redis 的一致性问题可以分为三部分来讨论:入队错误、执行错误、Redis 进程被终结。
- 入队错误,在命令入队的过程中,如果客户端向服务器发送了错误的命令,比如命令的参数数量 不对,等等,那么服务器将向客户端返回一个出错信息,并且将客户端的事务状态设为 REDIS_DIRTY_EXEC
- 执行错误,如果命令在事务执行的过程中发生错误,比如说,对一个不同类型的 key 执行了错误的操作, 那么 Redis 只会将错误包含在事务的结果中,这不会引起事务中断或整个失败,不会影响已执行事务命令的结果,也不会影响后面要执行的事务命令,所以它对事务的一致性也没有影响。
- Redis 进程被终结,如果 Redis 服务器进程在执行事务的过程中被其他进程终结,或者被管理员强制杀死,那么根据 Redis 所使用的持久化模式.
- 内存模式:如果 Redis没有采取任何持久化机制,那么重启之后的数据库总是空白的,所以数据总是一致的。
- RDB 模式:在执行事务时,Redis 不会中断事务去执行保存 RDB 的工作,只有在事务执 行之后,保存 RDB 的工作才有可能开始。所以当进程在事务中途被杀死,事务内执行的命令不管成功了多少,都不会被保存到 RDB 文件里。那么还原后的数据库就是一致的。
- AOF 模式:如果事务语句未写入到 AOF 文件,或 AOF 未被 SYNC 调用保存到磁盘,那么当进 程被杀死之后,Redis 可以根据最近一次成功保存到磁盘的 AOF 文件来还原数据库。如果事务的部分语句被写入到 AOF 文件,并且 AOF 文件被成功保存,那么不完整的事务执行信息就会遗留在 AOF 文件里,当重启 Redis 时,程序会检测到 AOF 文件并 完整,Redis 会退出,并报告错误。需要使用 redis-check-aof 工具将部分成功的事务命令移除之后,才能再次启动服务器。还原之后的数据总是一致的
- 隔离性(Isolation):Redis 是单进程程序,并且它保证在执行事务时,不会对事务进行中断,事务可以运行直到执行完所有事务队列中的命令为止。因此,Redis 的事务是总是带有隔离性的。
- 持久性(Durability):因为事务不过是用队列包裹起了一组 Redis 命令,并没有提供任何额外的持久性功能,所以事 务的持久性由 Redis 所使用的持久化模式决定
- 在单纯的内存模式下,事务肯定是不持久的。
- 在 RDB 模式下,服务器可能在事务执行之后、RDB 文件更新之前的这段时间失败,所以 RDB 模式下的 Redis 事务也是不持久的。
- 在 AOF 的“总是 SYNC ”模式下,事务的每条命令在执行成功之后,都会立即调用 fsync或 fdatasync 将事务数据写入到 AOF 文件。但是,这种保存是由后台线程进行的,线程不会阻塞直到保存成功,所以从命令执行成功到数据保存到硬盘之间,还是有一段非常小的间隔,所以这种模式下的事务也是不持久的。
- 其他 AOF 模式也和“总是 SYNC ”模式类似,所以它们都是不持久的。
Lua 脚本
redis通过内嵌对 Lua 环境的方式,其原子执行的特性,解决了长久以来不能高效地处理 CAS (check-and-set)命令的缺点。其原理如下
 例子1:
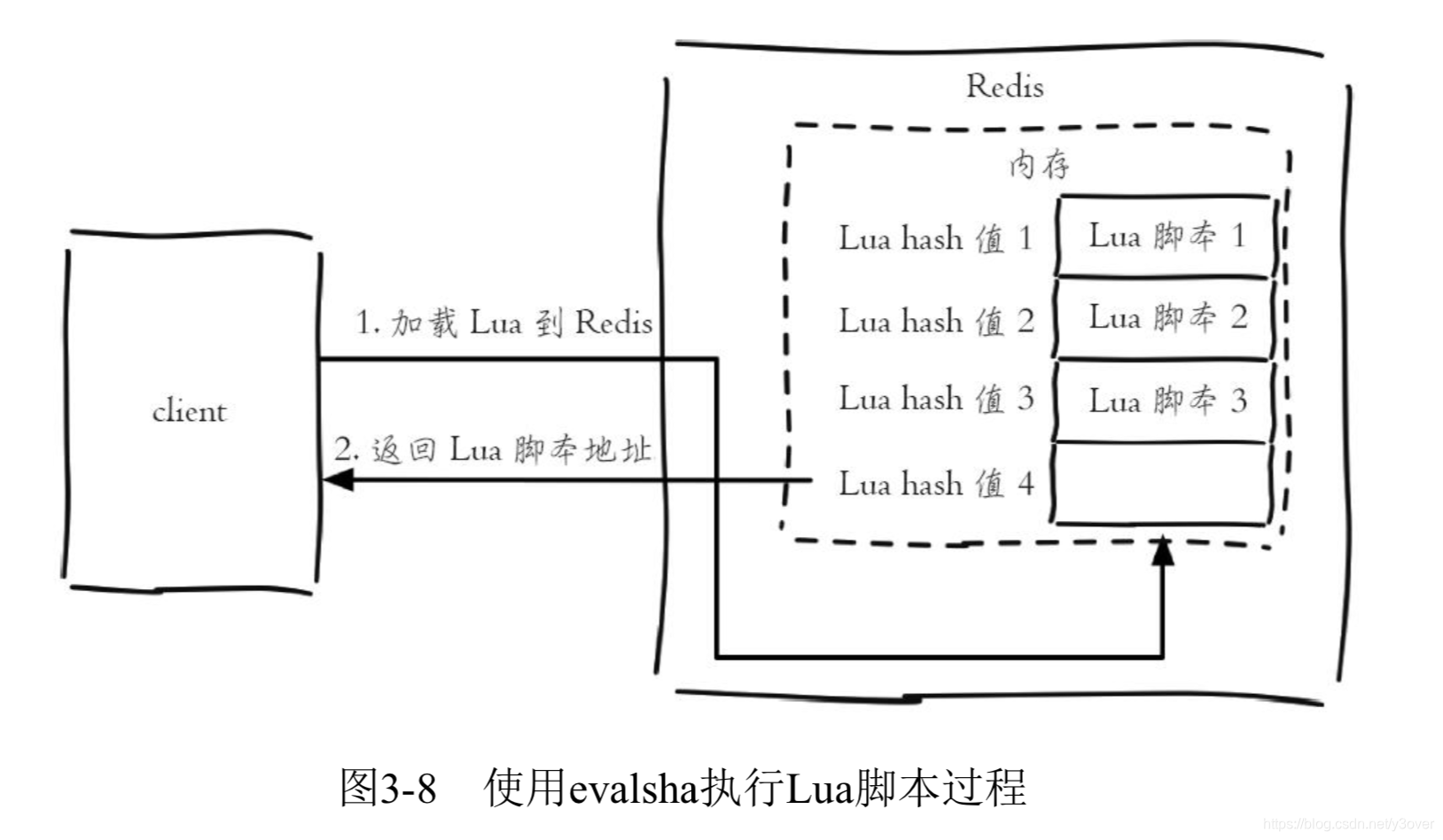
例子1: eval 'return redis.call("get", KEYS[1])' 1 foo # 与以下命令相同 get foo 当然,redis时也可以先上传lua脚本,然后用sha调用
 例子2:
例子2: #上传脚本,并返回sha: a5260dd66ce02462c5b5231c727b3f7772c0bcc5script load 'return redis.call("get", KEYS[1])'evalsha a5260dd66ce02462c5b5231c727b3f7772c0bcc5 1 foo # 与以下命令相同 get foo 更多命令请参考《》
从定义上来说, Redis 中的脚本本身就是一种事务, 所以任何在事务里可以完成的事, 在脚本里面也能完成。 并且使用脚本要来得更简单,并且速度更快。但由于eval每次要上传脚本会占用大量的io,脚本质量不行也会造成阻塞。
Redis 发布/订阅(Pub/Sub)
每个 Redis 服务器进程都维持着一个表示服务器状态的redis.h/redisServer 结构.
struct redisServer { // ... dict *pubsub_channels; /* Map channels to list of subscribed clients */ list *pubsub_patterns; /* A dict of pubsub_patterns */ // ...};typedef struct pubsubPattern { redisClient *client; robj *pattern;} pubsubPattern; 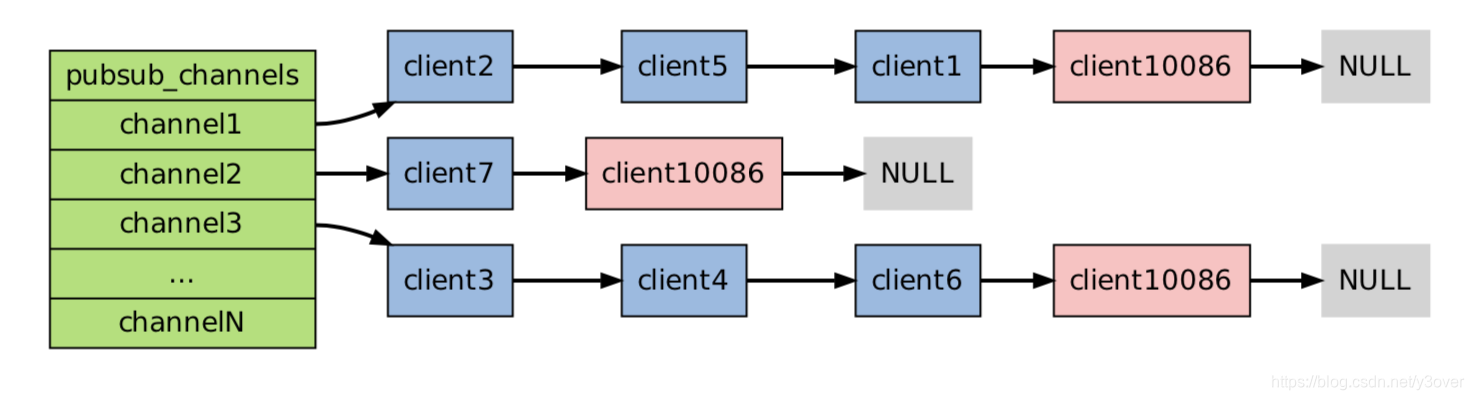
def SUBSCRIBE(client, channels): // 遍历所有输入频道 for channel in channels: // 将客户端添加到链表的末尾 redisServer.pubsub_channels[channel].append(client)
当发送PUBLISH信息到channel2频道时,client10086就能收到
def PUBLISH(channel, message): // 遍历所有订阅频道 channel 的客户端 for client in server.pubsub_channels[channel]: // 将信息发送给它们 send_message(client, message)
当client10086退订UNSUBSCRIBE频道的时候,我删除的对应信息就行.
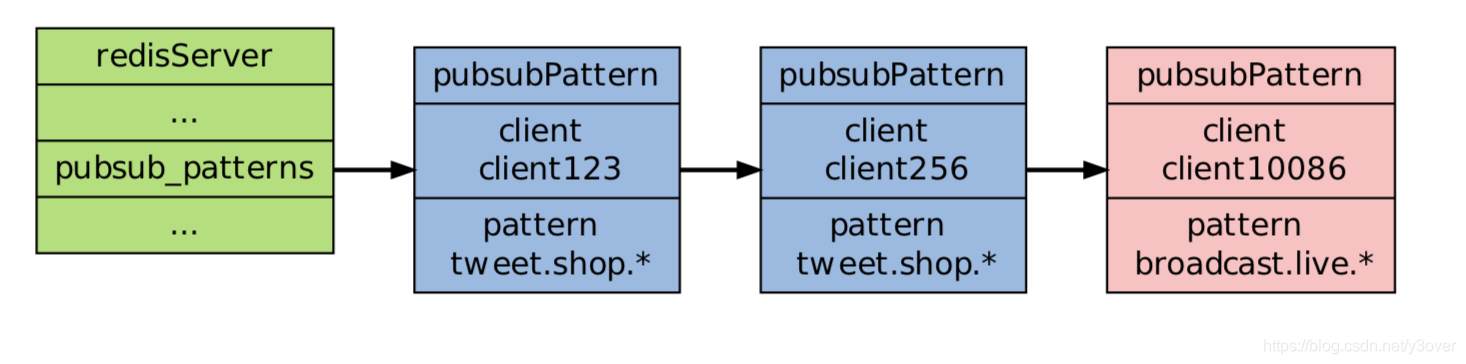 这时客户端 client10086 执行 PSUBSCRIBE broadcast.list.* 同样的通过遍历整个 pubsub_patterns 链表,程序可以检查所有正在被订阅的模式,以及订阅这些模式的客户端。
这时客户端 client10086 执行 PSUBSCRIBE broadcast.list.* 同样的通过遍历整个 pubsub_patterns 链表,程序可以检查所有正在被订阅的模式,以及订阅这些模式的客户端。 当发送PUBLISH信息到broadcast.live.aa模式时,client10086就能收到
def PUBLISH(channel, message): // 遍历所有订阅频道 channel 的客户端 for client in server.pubsub_channels[channel]: // 将信息发送给它们 send_message(client, message) // 取出所有模式,以及订阅模式的客户端 for pattern, client in server.pubsub_patterns: // 如果 channel 和模式匹配 if match(channel, pattern): // 那么也将信息发给订阅这个模式的客户端 send_message(client, message)
当client10086退订PUNSUBSCRIBE 模式的时候,我删除的对应信息就行.
持久化的发布和订阅Stream
为了解决Pub/Sub没有ack机制及消息不能持久化的问题,redis作者参考mq《》引入了新数据Stream
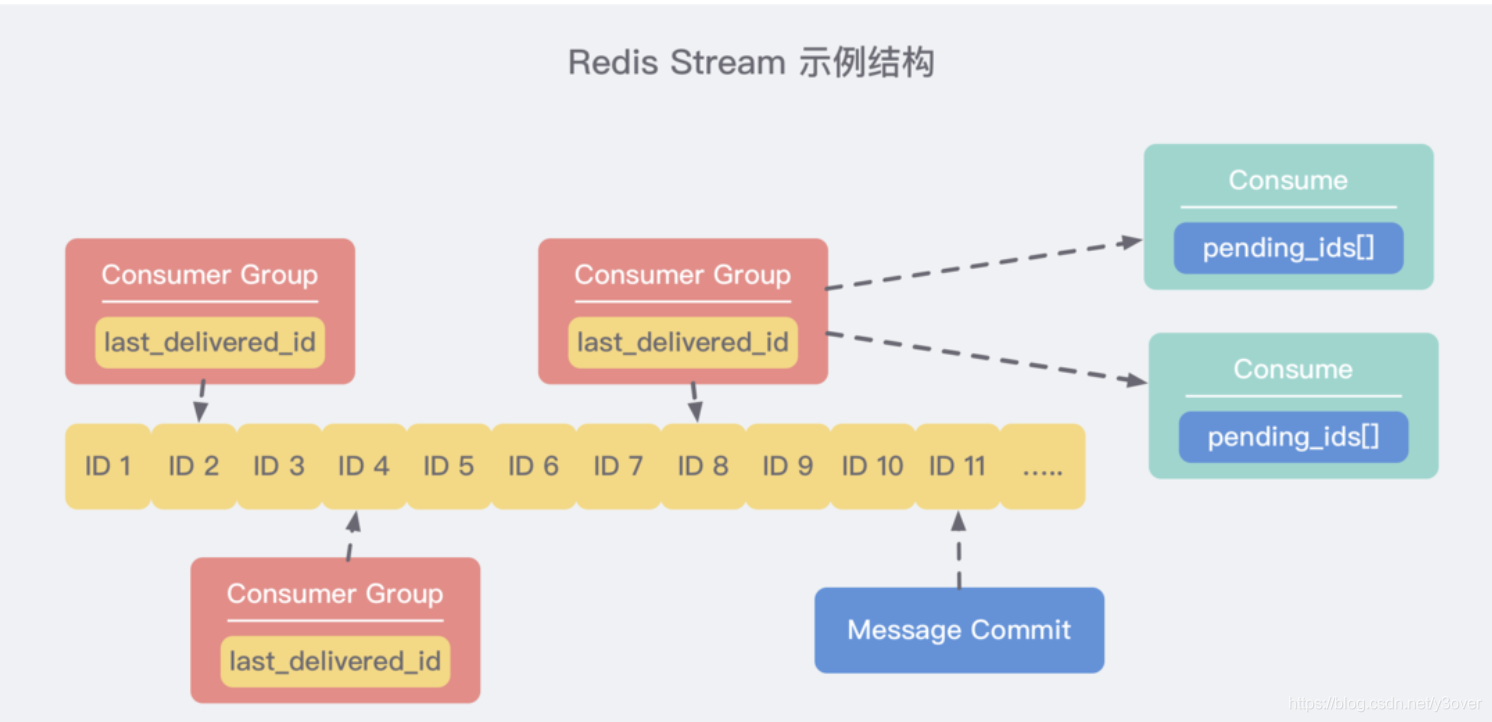
- Consumer Group:消费组,可由多个消息者组成
- last_delivered_id:消费组所表示的消费进度
- message Commit: PUBLISH所提交的消息
- pending_ids:表示消费者,正在消费记录的
Stream相比于mq,适合处理少量,但性能要求比较高的数据。
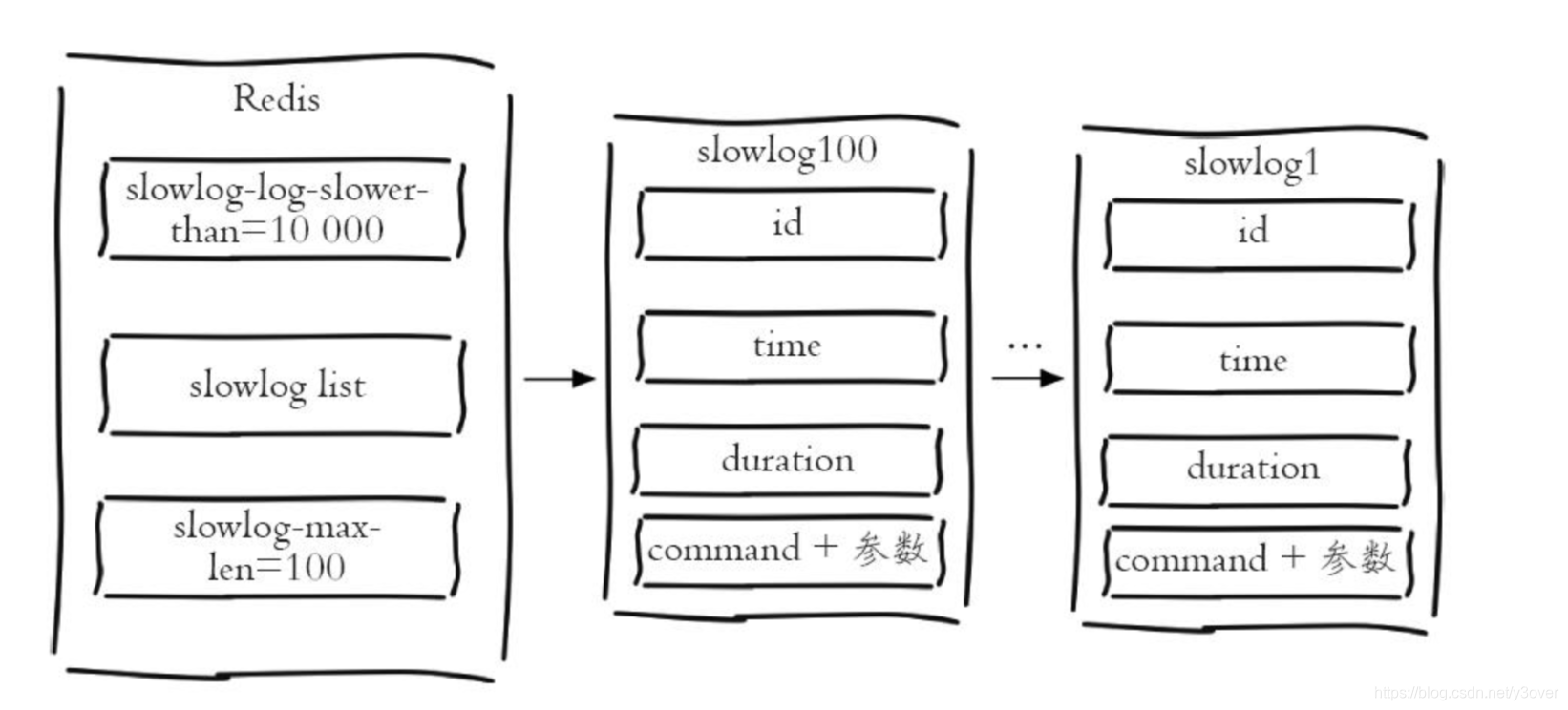
redis慢日志
在Redis中,关于慢查询有两个设置–慢查询最大超时时间和慢查询最大日志数。
# 慢查询最大超时, 20000毫秒config set slowlog-log-slower-than 20000# 慢查询最大日志数, 默认慢查询日志的记录数量为128条config set slowlog-max-len 1000# 将配置持久化到本地配置文件config rewrite# 慢查询条数slowlog len# 清空日志slowlog reset# 获取慢查询列表SLOWLOG GET 1) 1) (integer) 666 // id 2) (integer) 1456786500 // 执行时间 3) (integer) 11615 // 执行耗时 4) 1) "BGREWRITEAOF" // 命令 2) 1) (integer) 665 // id 2) (integer) 1456718400 // 执行时间 3) (integer) 12006 // 执行耗时 4) 1) "SETEX" // 命令 2) "video_info_200" 3) "300" 4) "2"
分布式锁
redis主要利用set命令去实现分布式锁
# 从 Redis 2.6.12 版本开始, SET 命令格式SET key value [EX seconds] [PX milliseconds] [NX|XX]- EX second :设置键的过期时间为 second 秒。 SET key value EX second 效果等同于 SETEX key second value 。- PX millisecond :设置键的过期时间为 millisecond 毫秒。 SET key value PX millisecond 效果等同于 PSETEX key millisecond value 。- NX :只在键不存在时,才对键进行设置操作。 SET key value NX 效果等同于 SETNX key value 。- XX :只在键已经存在时,才对键进行设置操作。
如果是老板本的redis,为了保证“键存在判断“ + ”过期时间“ 两操作的原子性,可以使用上述提到的lua脚本方式
布隆过滤器bitmap
Bitmap在Redis中并不是一个单独的数据类型,而是由字符串类型(SDS)之上定义的与比特相关的操作实现的。
# 字符串"meow"的二进制表示:01101101 01100101 01101111 01110111set bitmap_cat "meow"# 最低位下标为0。取得第3位的比特(0)getbit bitmap_cat 3# 将第7位设为0setbit bitmap_cat 7 0# 修改过后的字符串变成了"leow"get bitmap_cat
布隆过滤器是由一个长度为m比特的位数组(bit array)与哈希函数k(hash function)组成的数据结构。
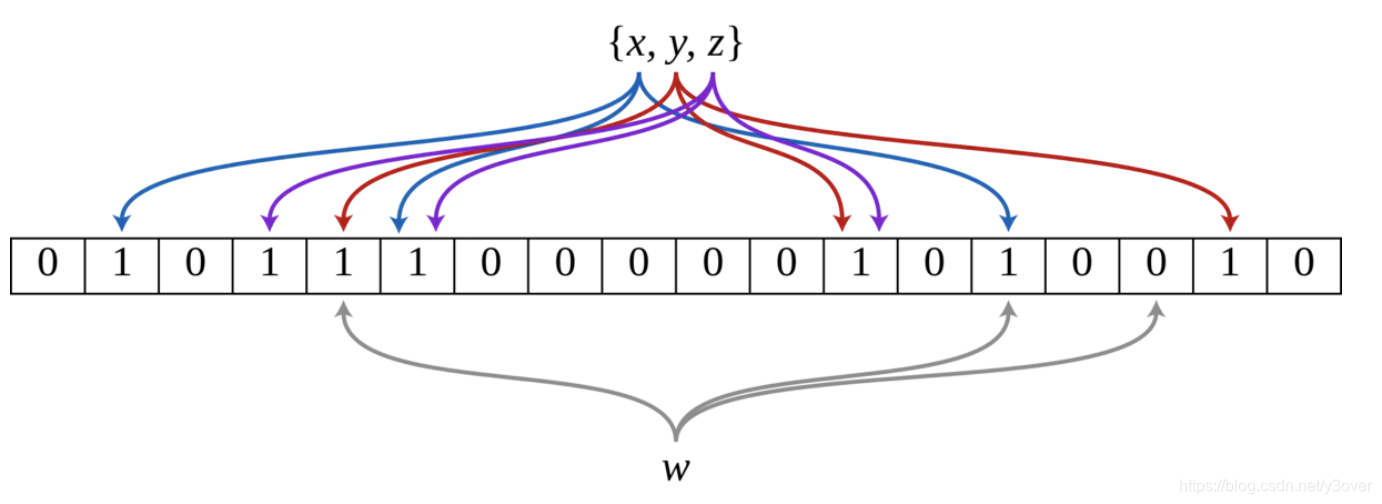
- 当要插入一个元素时,将输入数据使用用哈希函数(k)产生哈希值。以哈希值作为位数组中的下标,将所有k个对应的比特置为1。
- 当要查询(即判断是否存在)一个元素时,同样将输入数据通过哈希函数得到哈希值,然后将哈希值作为位数组中的下标于位数组对应位置进行比较。如果有任意一个比特为0,表明该元素一定不在集合中。如果所有比特均为1,表明该集合有(较大的)可能性在集合中。
- 哈希函数可借鉴了Guava的BloomFilterStrategies实现,采用MurmurHash和双重哈希进行散列
- 确定过滤器数组长度的话要两个参数:预估的元素数量,以及可接受的最大误差(即假阳性率),也可借鉴Guava;
- 插入时,使用setbit保存哈希值
- 查询时,使用getbit获取对应位置比较
HyperLogLog
使用数学工式进行统计方式。解决统计变量到达一点数量级空间,cpu资源损耗的问题。
- 《》
- 《》
- 《Redis深度历险:核心原理和应用实践》
# 加入元素PFADD# 获取统计数值PFCOUNT# 将多个 HyperLogLog 合并(merge)为一个 HyperLogLogPFMERGE
GeoHash
Redis 在 3.2 版本以后,增加用于存储 地图位置的二维经纬度GEO数据结棍。
- 《Redis深度历险:核心原理和应用实践》
# 加入 juejin 的经纬度到company中geoadd company 116.48105 39.996794 juejin# 计算两公司的距离,返回kmgeodist company juejin juejin km # 获取 juejin 的经纬度geopos company juejin# 范围 20 公里以内最多 3 个元素按距离正排,它不会排除自身 georadiusbymember company ireader 20 km count 3 asc
主要参考
《》
《》 《》 《Redis 设计与实现》 《Redis开发与运维》 《Redis深度历险:核心原理和应用实践》 《》 《》 《》转载地址:https://blog.csdn.net/y3over/article/details/116228089 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
