(三) SiamRPN从论文角度介绍
 最终总的损失: l o s s = L c l s + λ L r e g loss = L_{cls}+\lambda L_{reg} loss=Lcls+λLreg
最终总的损失: l o s s = L c l s + λ L r e g loss = L_{cls}+\lambda L_{reg} loss=Lcls+λLreg  接着作者只对正样本的分类结果做了分析,这和SiamFC一样,即奇数通道{1,3,…,2k-1}.即可得分类的值为 C L S ∗ = ( x i c l s , y j c l s , c l c l s ) CLS^*={(x_i^{cls}, y_j^{cls}, c_l^{cls})} CLS∗=(xicls,yjcls,clcls),从而我们可以得到相应的anchor set,
接着作者只对正样本的分类结果做了分析,这和SiamFC一样,即奇数通道{1,3,…,2k-1}.即可得分类的值为 C L S ∗ = ( x i c l s , y j c l s , c l c l s ) CLS^*={(x_i^{cls}, y_j^{cls}, c_l^{cls})} CLS∗=(xicls,yjcls,clcls),从而我们可以得到相应的anchor set, 接着找到了 A N C ∗ ANC^* ANC∗对应的回归框信息 A w ∗ h ∗ 4 k c l s A^{cls}_{w*h*4k} Aw∗h∗4kcls上,得到调整后的 R E G ∗ REG^* REG∗回归信息。
接着找到了 A N C ∗ ANC^* ANC∗对应的回归框信息 A w ∗ h ∗ 4 k c l s A^{cls}_{w*h*4k} Aw∗h∗4kcls上,得到调整后的 R E G ∗ REG^* REG∗回归信息。 之后就可以得到相应的K个推荐框结果了:
之后就可以得到相应的K个推荐框结果了: 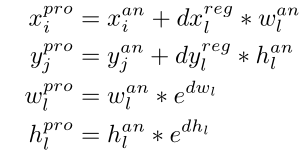 最后采用NMS的方法确定唯一的bbox。
最后采用NMS的方法确定唯一的bbox。
发布日期:2021-06-18 12:11:50
浏览次数:34
分类:技术文章
本文共 3115 字,大约阅读时间需要 10 分钟。
文章:High Performance Visual Tracking with Siamese Region Proposal Network
1.Motivation
尽管之前的目标跟踪器取得了不错的性能,但是他们中的大部分很难在实时性和高性能方面同时存在。从而,作者提出了SiamRPN网络,端到端的离线训练图像pairs。SiamRPN包括一个Siamese subnetwork(类似于SiamFC)用于特征提取,以及一个区域推荐网络RPN,该RPN包括分类和回归分支。与标准的RPN网络不同,作者使用了两个分支的相关特征图进行proposal提取;此外,在跟踪阶段上,作者没有事先定义好的类别标签,从而使用了模板分支将目标的外观信息编码到RPN特征图中,以此区分前景和背景信息。
在推理阶段上,作者将跟踪任务当作一个one-shot检测的框架,在第一帧中的bbox作为唯一的模板帧(模板固定)。作者将模板分支当作去预测检测核的参数,类似于meta-learner。(one-shot可以理解为只有一个训练样本,之后进行推理工作。之前训练过程都有多个样本) 作者认为SiamRPN的成功,一方面是因为训练样本pair足够多,越多的训练样本有越强的性能,另一方面区域推荐网络可以更准确的预测bbox的尺度和长宽比信息。2.Method

- Siamese network运行过程,设 x ∈ R 255 ∗ 255 ∗ 3 x \in R^{255*255*3} x∈R255∗255∗3代表搜索帧图像, z ∈ R 127 ∗ 127 ∗ 3 z \in R^{127*127*3} z∈R127∗127∗3代表模板帧图像,其经过特征提取后可得到特征: φ ( z ) \varphi(z) φ(z)和 φ ( x ) \varphi(x) φ(x)。其中特征提取方法采用了AlexNet。
- 区域推荐RPN网络的运行过程,RPN包括2个部分,一个是pair-wise correlation section,另外一个是supervision section。其中supervision 是由前景-背景分类分支和proposal回归分支构成。pair-wise correlation section是首先经过conv的操作,将 φ ( z ) \varphi(z) φ(z)模板分支的通道提升到 φ ( z ) c l s \varphi(z)_{cls} φ(z)cls和 φ ( z ) r e g \varphi(z)_{reg} φ(z)reg通道大小。而后经过conv的操作将 φ ( x ) \varphi(x) φ(x)分成 φ ( x ) c l s \varphi(x)_{cls} φ(x)cls和 φ ( x ) r e g \varphi(x)_{reg} φ(x)reg。接着KaTeX parse error: Expected 'EOF', got '}' at position 11: \varphi(z)}̲充当卷积核操作 φ ( x ) \varphi(x) φ(x)可得分类分支与模板分支的结果: A w ∗ h ∗ 2 k c l s = φ ( x ) c l s ⋆ φ ( z ) c l s A w ∗ h ∗ 4 k r e g = φ ( x ) r e g ⋆ φ ( z ) r e g A_{w*h*2k}^{cls} = \varphi(x)_{cls} \star \varphi(z)_{cls} \\ A_{w*h*4k}^{reg} = \varphi(x)_{reg} \star \varphi(z)_{reg} Aw∗h∗2kcls=φ(x)cls⋆φ(z)clsAw∗h∗4kreg=φ(x)reg⋆φ(z)reg
3.Train
训练过程:上图的前向推理过程,与groundtruth之间会产生loss,通过该loss反向传播调整参数,那么Loss如何求呢?Loss 分为2个部分,第一是分类Loss,第二是回归loss。
分类Loss:采用和SiamFC一样的交叉熵loss; 回归Loss:设 A x , A y , A w , A h A_x,A_y,A_w,A_h Ax,Ay,Aw,Ah分别代表Anchor的中心点和长款信息, T x , T y , T w , T h T_x,T_y,T_w,T_h Tx,Ty,Tw,Th代表该帧的groundtruth box,从而可以计算得到标准化的距离。其损失如下: 最终总的损失: l o s s = L c l s + λ L r e g loss = L_{cls}+\lambda L_{reg} loss=Lcls+λLreg 训练细节:
(1)作者只采用了一组anchor用于训练和跟踪,由于相邻帧之间变化不大,其anchor比例=[0.33,0.5,1,2,3]。 (2)如何挑选正样本和负样本,如果 I o U ( G T , A n c h o r s i ) > t h h i IoU(GT,Anchors_i) > th_{hi} IoU(GT,Anchorsi)>thhi,则认为是正样本;如果 I o U ( G T , A n c h o r s i ) < t h l o IoU(GT,Anchors_i) < th_{lo} IoU(GT,Anchorsi)<thlo则认为是负样本。是验证作者设置 t h l o = 0.3 th_{lo}=0.3 thlo=0.3, t h h i = 0.6 th_{hi}=0.6 thhi=0.6,作者认为最多仅有16个正样本和N个负样本(N=64-正样本个数)。anchor是在最后的特征图上的每个点出处都生成不同比例的框。具体锚框介绍可参考:4.Test
跟踪过程的inference阶段和训练过程一样,这样最终我们就可以得到2个特征图:
接着作者只对正样本的分类结果做了分析,这和SiamFC一样,即奇数通道{1,3,…,2k-1}.即可得分类的值为 C L S ∗ = ( x i c l s , y j c l s , c l c l s ) CLS^*={(x_i^{cls}, y_j^{cls}, c_l^{cls})} CLS∗=(xicls,yjcls,clcls),从而我们可以得到相应的anchor set, 接着找到了 A N C ∗ ANC^* ANC∗对应的回归框信息 A w ∗ h ∗ 4 k c l s A^{cls}_{w*h*4k} Aw∗h∗4kcls上,得到调整后的 R E G ∗ REG^* REG∗回归信息。 之后就可以得到相应的K个推荐框结果了: 最后采用NMS的方法确定唯一的bbox。 5.Experiment
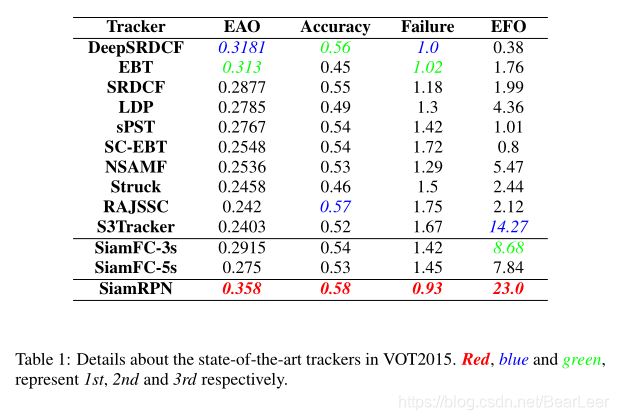
6.Conclusion
采用了RPN区域推荐网络,通过分类和回归的方式极大的提升了运行的准确性,并提升了实时性。实际是通过RPN预测出多个推荐框,然后采用非极大值抑制的方法获得最终的框结果。但是模板依然没有更新。
https://openaccess.thecvf.com/content_cvpr_2018/papers/Li_High_Performance_Visual_CVPR_2018_paper.pdf
转载地址:https://blog.csdn.net/BearLeer/article/details/115145989 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
路过,博主的博客真漂亮。。
[***.116.15.85]2024年04月18日 23时01分30秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
js爬虫拿到的字符串数据转化成数组再转化成json对象
2019-05-06
html5如何利用rem实现自适应布局
2019-05-06
如何在vue中使用sass
2019-05-06
两道前端面试题目:1.变量作用域,2.利用hash将数组去重
2019-05-06
h5绚丽的边框-border渐变和字体颜色渐变
2019-05-06
vue利用axios处理开发环境和生成环境的跨域问题
2019-05-06
仿响应式html:JS来判断页面是在手机端还是在PC端打开的方法
2019-05-06
基于zepto的motion库-移动端页面无缝循环滑动效果
2019-05-06
h5锁屏提醒-锁横屏和锁竖屏
2019-05-06
Canvas的事件处理,监听点击的位置
2019-05-06
es6对象的解构赋值和对象的拓展
2019-05-06
nodejs 利用对mysql数据库进行查询和插入数据
2019-05-06
Javascript 严格模式有什么限制
2019-05-06
es6参考了Airbnb 公司的 JavaScript 风格规范
2019-05-06
Iconfont使用方法的详细教程,html怎样引入iconfont
2019-05-06
vue中本地静态图片的路径应该如何写
2019-05-06
es6 promise对象回调处理详解
2019-05-06
vue-router懒加载解决首次加载时资源过多导致的速度缓慢问题
2019-05-06
vue2.0 资源文件assets和static的区别
2019-05-06
Vue2.0 探索之路——生命周期和钩子函数的一些理解
2019-05-06
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 312075132 位访客
访问时间: 2024-05-08 19:39:54
访问IP: 3.138.141.202
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版