神经网络中矩阵稀疏性的编码方式
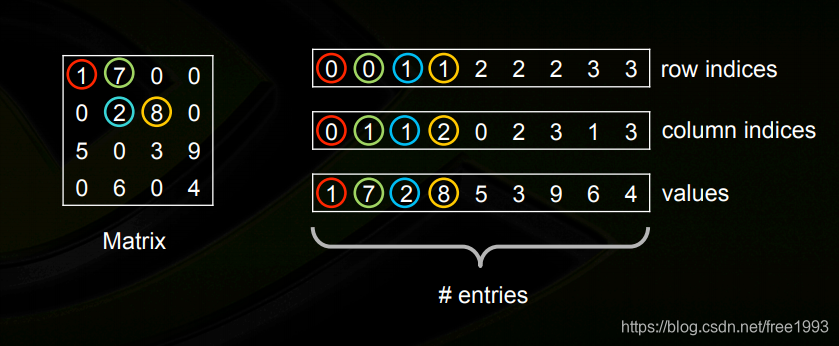 对应的scipy的定义是
对应的scipy的定义是 




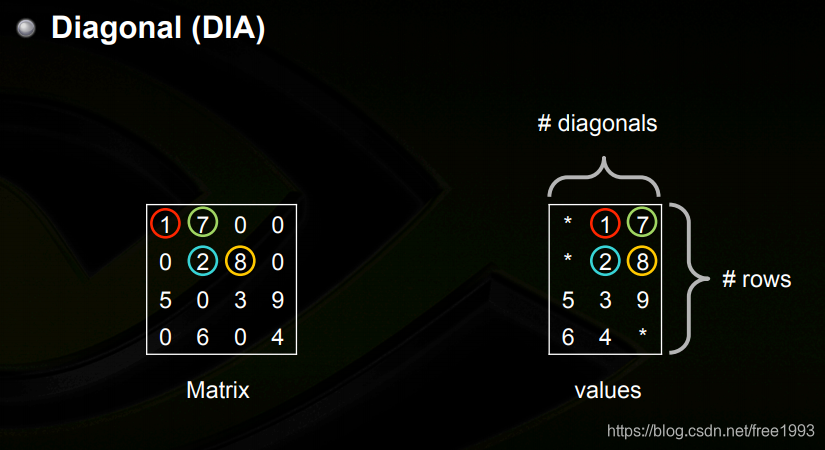 他是按照对角线来存储的,在scipy中是两个数组data和offset。data数组的每一行存的是每条对角线上的元素,offset存的是这一行 相对于主对角线的偏移值。
他是按照对角线来存储的,在scipy中是两个数组data和offset。data数组的每一行存的是每条对角线上的元素,offset存的是这一行 相对于主对角线的偏移值。 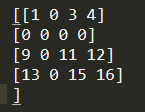
 翻译成scipy的表示形式是
翻译成scipy的表示形式是 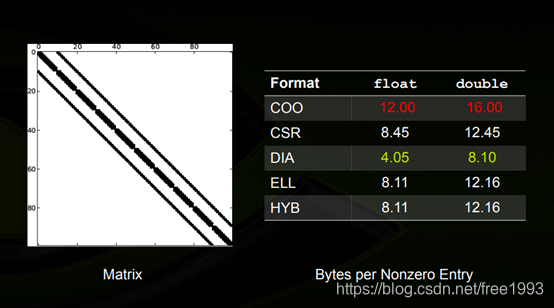 对于非结构化的
对于非结构化的 

发布日期:2021-06-20 02:50:11
浏览次数:6
分类:技术文章
本文共 1449 字,大约阅读时间需要 4 分钟。
背景
神经网络的计算基本上是以高维Tensor的形式存在的。高维Tensor如何利用各种稀疏性来计算,因此问题就归结成如何编码这些稀疏性。
稀疏性编码的方式
在英伟达的这个pdf中,我认为最重要的一个结论是:一个稀疏编码方式的效率(存储空间)和稀疏的分布是息息相关的。COO
COO用三个(row, col, data)数组来存储稀疏矩阵。这个就很简单了。
对应的scipy的定义是 CSR

CSR使用三个(row, col,value),row数组的大小等于原矩阵的行+1.这有点像前缀和的感觉,也就是在row数组中row[i+1]-row[i]的数值是原矩阵matrix中第i行的non-zeros的数量。同时row[i+1]也是i+1行第一个非零元素在value数组中的偏移位置。
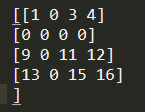
CSR对应的scipy的方式是: COO和CSR这两种编码方式只有当稀疏度很大,也就是原matrix中的0值元素很多的时候,编码方式才是有效果的。对于比较有结构的,而且比较稠密的,存储真滴拉跨。例如我们数组里面存的是int8,然后我们用一个4*4数组为例,数组是这个样子的:
然后CSR的表示形式是
indptr = np.array([0, 3, 3, 6, 9])indices = np.array([0, 2, 3, 0, 2, 3, 0, 2, 3])data = np.array([1, 3, 4, 9, 11, 12, 13, 15, 16])
需要的存储空间是原来的(5+9+9)/16=1.43倍。如果这个矩阵里面只有一个元素,那么存储空间(2+1+1)/16=0.25.所以就对稀疏性要求很高了。
想要跑的筒子们,这个是源代码:
import numpy as npimport mathfrom scipy.sparse import dia_matrix, csr_matrixindptr = np.array([0, 3, 3, 6, 9])indices = np.array([0, 2, 3, 0, 2, 3, 0, 2, 3])data = np.array([1, 3, 4, 9, 11, 12, 13, 15, 16])arr = csr_matrix((data, indices, indptr), shape=(4, 4)).toarray()print(arr)
DIA
对角线的存储方式。
他是按照对角线来存储的,在scipy中是两个数组data和offset。data数组的每一行存的是每条对角线上的元素,offset存的是这一行 相对于主对角线的偏移值。 
我们还是那上面的数组举个例子,记住上面这个数组:
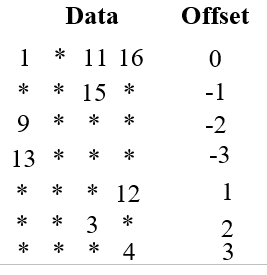
那么用DIA的表示形式是下面这样,*表示任意值,但是在scipy解析的时候全部解析成0
翻译成scipy的表示形式是 data = np.array([[1,0,11,16],[0,0,15,0],[9,0,0,0],[13,0,0,0],[0,0,0,12],[0,0,3,0],[0,0,0,4]])offsets = np.array([0,-1,-2,-3,1,2,3])data = dia_matrix((data, offsets), shape=(4, 4)).toarray()
所以,DIA比较适合对角矩阵,稀疏性千万别乱分布,要不真滴orz.
各种编码形式的对比
对于对角矩阵来说,平均编码字节
对于非结构化的 对于随机的
转载地址:https://blog.csdn.net/free1993/article/details/114455405 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
能坚持,总会有不一样的收获!
[***.219.124.196]2024年04月26日 05时09分19秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
【青少年编程】【二级】寻找宝石
2019-04-27
【组队学习】【26期】Linux教程
2019-04-27
LeetCode-LCP 18. 早餐组合(Goland实现)
2019-04-27
C++从入门到进阶近100本书推荐电子书pdf
2019-04-28
蓝桥杯 - [2014年第五届真题]分糖果(模拟)
2019-04-28
蓝桥杯 - [2013年第四届真题]大臣的旅费(DFS)
2019-04-28
蓝桥杯 - [2013年第四届真题]带分数(全排列)
2019-04-28
蓝桥杯 - [2013年第四届真题]幸运数(模拟)
2019-04-28
蓝桥杯 - [2013年第四届真题]横向打印二叉树(排序二叉树)
2019-04-28
蓝桥杯 - [历届试题]网络寻路(枚举)
2019-04-28
牛客网 - [中南林业科技大学第十一届程序设计大赛]兑换零钱(背包问题)
2019-04-28
HDU - Robberies(01背包)
2019-04-28
HDU - 最大报销额(01背包|贪心)
2019-04-28
HDU - Coins(完全背包)
2019-04-28
JXFCZX — 砝码称重1(DFS+背包)
2019-04-28
JXFCZX — 质数和分解(完全背包)
2019-04-28
JXFCZX — 花店橱窗(动态规划)
2019-04-28
JXFCZX — 逃亡的准备(多重背包)
2019-04-28
JXFCZX — 庆功会(多重背包)
2019-04-28
AcWing - 扩展欧几里得算法(扩欧)
2019-04-28
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 308312760 位访客
访问时间: 2024-04-27 09:57:19
访问IP: 3.16.147.124
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版