本文共 2654 字,大约阅读时间需要 8 分钟。
FP-growth算法
Apriori算法可能受到两种非平凡开销的影响:一方面它可能需要产生大量候选项集;另一方面它可能需要重复的扫描整个数据库,通过模式匹配检查一个很大的候选集合。这样检查数据库中每个事务来确定候选项集支持度的开销很大。
那么是否可以设计一种方法,挖掘全部频繁项集而无须这种代价昂贵的候选产生过程?一种试图这样做的方法称为频繁模式增长(Frequent-Pattern Growth,FP-growth)。它采取如下分治策略:首先,将代表频繁项集的数据库压缩到一颗频繁模式树(FP树),该树仍保留项集的关联信息。然后,把这种压缩后的数据库划分成一组条件数据库,每个数据库关联一个频繁项或模式段,并分别挖掘每个条件数据库。对于每个“模式片段”,只需要考察它相关联数据集。因此,随着被考察的模式的“增长”,这种方法可以显著地压缩被搜索的数据集的大小。
FP-growth算法的基本思路:
- 扫描一次事务数据库,找出频繁1-项集合,记为L,并把它们按支持度计数的降序进行排列。
- 基于L,再扫描一次事务数据库,构造表示事务数据库中项集关联的FP树。
- 在FP树上递归地找出所有频繁项集。
- 最后在所有频繁项集中产生强关联规则。
下面先举例介绍一下FP-grow算法挖掘频繁项集的过程:
事务数据库如下表1:
表1
数据库的第一次扫描与Apriori算法相同,它导出频繁1项集的集合,并得到它们的支持度计数。设最小支持度计数为2.频繁项的集合按支持度计数的递减序排序。结果集或表记为L。这样有L={
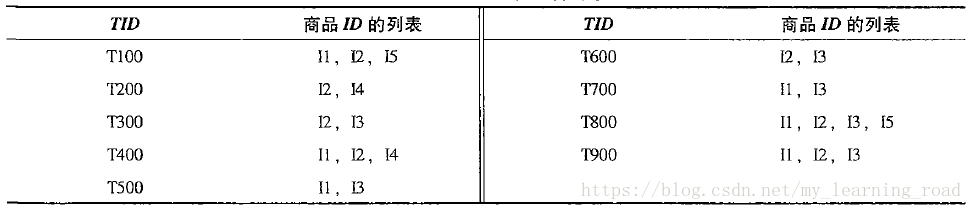
{I2:7}, {I1:6}, {I3:6}, {I4:2}, {I5:2}}。然后,FP树构造如下:首先,创建树的根结点,用“null”标记。第二次扫描数据库D。每个事务中的项都按L中的次序处理(即按递减支持度计数排序),并对每个事务创建一个分支。例如,第一个事务"T100:I1, I2, I5"包含三个项(按L中的次序I2、I1、I5),导致构造树的包含三个结点的第一个分支<I2: 1>,<I1: 1>,<I5:1>,其中I2作为根都子女链接到根,I1链接到I2,I5链接到I1。第二个事务T200按L的次序包含项I2和I4,它导致一个分支,其中I2链接到根,I4链接到I2。然而,该分支应该与T100已存在的路径共享前缀I2。因此结点I2的计数加1,并创建一个新的结点<I4: 1>,它作为子女链接到<I2: 2>。一般地,当为一个事务考虑增加分支时,沿共同前缀上的每个结点的计数增加1,为前缀之后的项创建结点和链接。
为了方便树的遍历,创建一个项头表,使每项通过一个结点链指向它在树中的位置。扫描所有的事务后得到的树显示如图1,带有相关的结点链。这样,数据库频繁模式的挖掘问题就转换成挖掘FP树的问题。
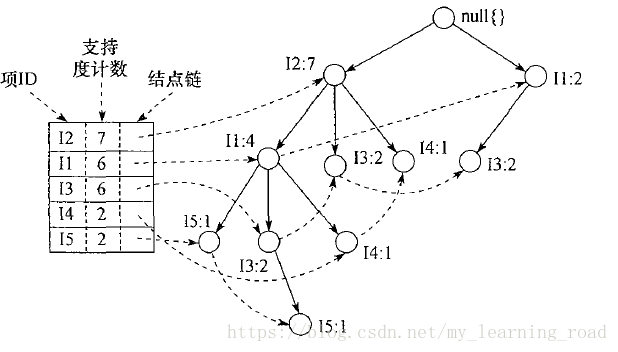
图1 存放压缩的频繁模式信息的FP树
FP树的挖掘过程如下:由长度为1的频繁模式(初始后缀模式)开始,构造它的条件模式基(一个“子数据库”,由FP树中与该后缀模式一起出现的前缀路径集组成)。然后,构造它的(条件)FP树,并递归地在该树上进行挖掘。模式增长通过后缀模式与条件FP树产生的频繁模式连接实现。
该FP树的挖掘过程总结在表2中,细节如下。首先考虑I5,它是L中的最后一项,而不是第一项。从表的后端开始的原因随着解释FP树挖掘过程就会清楚。I5出现在图1的FP树的两个分支中。这些分支形成的路径是<I2, I1, I5: 1>和<I2, I1, I3, I5: 1>。因此,考虑形成I5的条件模式基。使用这些条件模式基作为事务数据库,构造I5的条件FP树,它只包含单个路径<I2: 2, I1: 2>;不包含I3,因为I3的支持度计数为1,小于最小支持度计数。该单个路径产生频繁模式的所有组合:{I2,I5:2}、{I1,I5:2}、{I2,I1,I5:2}。
表2 通过创建条件(子)模式基挖掘FP树

对于I4,它的两个前缀形成条件模式基{{I2,I1:1},{I2:1}},产生一个单结点的条件FP树<I2:2>,并导出一个频繁模式{I2,I4:2}。
类似于以上分析,I3的条件模式基是{{I2,I1:2},{I2:2},{I1:2}}。它的条件FP树有两个分支<I2:4,I1:2>和<I1:2>。它产生模式集:{{I2,I3:4},{I1,I3:4},{I2,I1,I3:2}},如图2所示。最后,I1的条件模式基是{{I2:4}},它的FP树只包含一个结点<I2:4>,只产生一个频繁模式{I2,I1:4}。
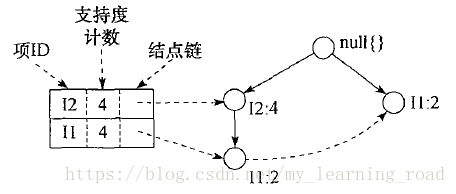
图2 与条件结点I3相关联的FP树
FP-growth方法将发现长频繁模式的问题转换成在较小的条件数据库中递归地搜索一些较短模式,然后连接后缀,它使用最不频繁的项作为后缀,提供了较好的选择性。该方法显著地降低了搜索开销。
FP-growth算法的框架:
输入:事务数据库D,最小支持度阈值min_sup,最小置信度阈值min_conf
输出:强关联规则集合RS 方法:其过程描述如下:扫描D找出频繁1-项集合L;L中的项按支持度计数递减排序;创建FP树的根结点null; //创建FP树for (D中的每个事务t){ 找出t中的频繁1-项集合tt(即删除t中非频繁项得到tt); 将tt中的项按L中的顺序排序; Insert-FP(tt, null); //创建事务tt的分支}LS=Search-FP(FP, null) //找出所有频繁项集 采用前面介绍的产生关联规则算法由LS产生强关联规则集合RS;
构造FP树的算法如下:
算法:Insert-FP算法(tt,root)
输入:已排序频繁1-项集合L,FP(子)树的根结点root 输出:FP树 方法:其描述如下:if (tt不空){ 取出tt中的第1个项i; if (root的某个子结点Node是i) Node.sup_count=Node.sup_count+1; else{ 创建Tr的子结点Node为i; Node.sup_count=1; 将Node加入项表链中; } 从L中删除项i; Insert-FP(L, Node);} 对FP-growth方法的性能研究表明,对于挖掘长的频繁模式和短的频繁模式,它都是有效的和可伸缩的,并且大约比Apriori算法快一个数量级。
转载地址:https://xinzhe.blog.csdn.net/article/details/86632195 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
