本文共 2255 字,大约阅读时间需要 7 分钟。
最近遇到一些情况需要对文本进行预处理,目的是从文本中提取特征。文本内容是不同病人的脾脏B超体检结果。内容格式如下:
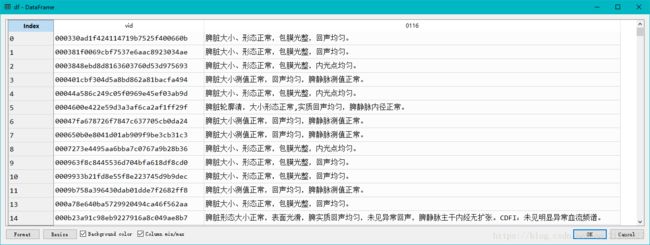
其中有一部分内容还含有数字,例如这样:
df_with_num=df[df['0116'].str.contains(r"\d")]
df_with_num.head()
Out[82]:
vid \
67 00514cc6a2c229618b763ad30bf3ce5b
353 0192c4d2609f04826421606571d59a64
519 0266554b4a165b54fefd1dd8dc90379d
594 02b18cbdbef9e70593370357b89cd14f
625 02dbf6bd8c66b433a4716cfdf34aa09d
0116
67 脾脏形态正常,包膜光整,实质回声均匀,脾厚度约52mm。
353 脾脏形态饱满,包膜光整,实质回声均匀,脾厚度约41mm 。
519 脾脏形态正常,包膜光整,实质回声均匀,脾门周围可见一类圆形低回声区,大小约17 mm× 13...
594 脾脏大小、形态正常,包膜光整,回声均匀。脾门区见大小13x11mm等回声,界清规则。
625 脾脏厚度约45mm ,长径约129mm,包膜光整,实质回声尚均匀。
在这种情况下想要提取特征,感觉有点不太容易,事实上我到现在也没提取出什么有用的东西,但是,我还是把我目前为止经历过一系列试错之后的总结写一下,等到有了进度再更新。
这是目前想到的步骤:
##1去除数值型数据:
##2tf-idf
##3查找top,总结pos词
##4去除pos句子
##5再次tf-idf,查看分析
##6总结neg的几种主要形式
##7提取特征
为什么要这这样呢?因为经过观察发现大部分数据都是描述正常情况的,只有少部分是描述体检结果异常的,而有具体数值的绝大多数都是体检异常的。事实上体检异常的种类也是可以列举的,如脾脏大小问题会直接描述脾脏厚度,宽度等,回声区问题会描述回声区大小等。所以就像将描述正常情况的全部删除,只保留描述异常情况的,又由于异常情况可以列举完,正常情况就是异常情况的反面。而正常情况由于是大多数,我希望利用分词后的tf-idf得到topK的高频词,然后利用词性等,将描述如“脾脏大小、形态正常,包膜光整,回声均匀。”的分句去除掉。之后再在源数据基础上去除掉这些之后,将数值部分提取出来作为数据(还需要周全考虑,因为数值部分有描述脾脏大小和回声大小的,主语不同),基于这个思想,就有了上面的步骤。
但是我如果直接对数据使用jieba进行分词,会得到一大堆的数字,再去做tf-idf效果更差,所以必须先将每行数据中的数字部分都全部去除掉,再进行分词,然后再进行处理。过程如下:
首先我需要将数据的全角全部转换成半角,这点是从这里抄来的:python中半角与全角互相转换
def strQ2B(ustring):
#"""全角转半角"""
rstring = ""
for uchar in ustring:
inside_code=ord(uchar)
if inside_code == 12288: #全角空格直接转换
inside_code = 32
elif (inside_code >= 65281 and inside_code <= 65374): #全角字符(除空格)根据关系转化
inside_code -= 65248
rstring += chr(inside_code)##注意这里要是前面加一个tab,就不会将if里的内容加进来了
return rstring##注意这里要是前面加一个tab,就变成第一次就return了
##对str字段进行全角半角的转换
df['0116']=df['0116'].map(strQ2B)
#len(df[df['0116'].str.contains(r'\d')])##查看一下目前含有数字的有多少行
#Out[67]: 716
关于tab的注释是我加上去的...当时只是无脑抄,后来才发现有很大问题。
我为什么要进行这一步呢,事实上文本中基本都是全角,在我经历过下面两轮操作之后我怀疑是全角半角的问题,可惜不是,而是㎝,特殊字符,这是单位字符而非半角,我当成了半角,也是够坑的,后来我在正则中加入了这个就解决了。
接下来是要删除掉含有数值的分句,也是经过一段时间的学习,我知道了应该用正则来做,可惜我的正则学的并不好,又是经过了n久的试错之后,终于总结出了这个文本中该如何匹配还有数值的部分。主要是利用re.sub()函数将匹配的数值分句替换为空串,具体代码如下:
import re
def resub(str):
return re.sub(r"(,|,|。|,)*?([^(,|,)]*?)(\d|(|)|\(|\)|\*|x)+( )*(mm|MM|cm|CM|㎜|㎝)(,|,|。|,)*?",'',str)
df['0116']=df['0116'].map(resub)
len(df[df['0116'].str.contains(r'\d')])
Out[125]: 0
看到这个正则我就觉得不容易,这个B超数据录入的太随性了,有特殊字符,有*,x,mm,MM,㎜,简直心累。还有发现全角的(不需要转义,而半角的(就需要加\转义,还有*也是。
目前就做到了这里有时间再写。
转载地址:https://blog.csdn.net/weixin_35172279/article/details/116575737 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
