python dataframe 取一列中的前3个字符_Python入门 数据分析
发布日期:2021-10-30 18:55:33
浏览次数:7
分类:技术文章
本文共 5713 字,大约阅读时间需要 19 分钟。
Python适合做哪种数据分析?①数据指的是 结构化数据,即:“一维数组或二维数组”,也可以这样理解:“二维数组是1个表格,一维数组是它的某1列”;②分析指的是对微观数据进行 数学统计,获得宏观的结果;python使用pandas库做数据分析。 pandas给数据分析提供了哪些支持?①针对数据,提供了2种 数据类型: Series和 DataFrame,分别描述列和表格;②针对分析,提供了 sql统计查询、以及 链式调用函数,它们基于Series和DataFrame做运算 pandas支持读写哪些类型的存储介质?在数据分析之前,我们要 读取数据,并转换成pandas提供的数据类型:Series或DataFrame;在数据分析之后,我们要 存储结果,将Series或DataFrame数据写入存储介质。基础库中提供的数据 读写方法比较繁琐,pandas提供了更简洁的方式,本文关注下面3种常用的存储介质:①内存中的list和dic② excel文件③ sqlite3数据库
相关python库
①基础库是 pandas
②读写excel需要 openpyxl
pip install pandas openpyxl 安装数据分析用到的库
1.pandas数据读写
①在内存中,二维数据有2种组织方式:按行组织的字典列表、按列组织的列表字典,它们都可以与DataFrame相互转换。
import pandas as pd# 1)按行组织data1 = [{ 'name': 'test1', 'age': 30, 'sex': 1}, { 'name': 'test2', 'age': 25, 'sex': 0}, { 'name': 'test3', 'age': 40, 'sex': 1}, { 'name': 'test3', 'age': 50, 'sex': 0}]# 2)按列组织data2 = { 'name': ['test1', 'test2', 'test3', 'test3'], 'age': [30, 25, 40, 50], 'sex': [1, 0, 1, 0]}# 读 df1 = pd.DataFrame(data1)df2 = pd.DataFrame(data2)print('读(按行组织的)字典:')print(df1)print('读(按列组织的)字典:')print(df2)# 写 data1 = df1.to_dict(orient='records')data2 = df2.to_dict(orient='list')print('写(按行组织的)字典:')print(data1)print('写(按列组织的)字典:')print(data2)②在excel文件中,有多个标签页sheet;每个sheet对应一个DataFrame;通常,sheet中的第一行是 标题行,它表明了列结构。 import pandas as pd# 读excel文件# 1个excel由多个sheet组成# 每个sheet中有1个标题行,它说明了数据的列结构sheet = pd.read_excel(r'C:\Users\Administrator\Desktop\readExcelDemo.xlsx', header=0, sheet_name=[0, 1])df1 = sheet[0]df2 = sheet[1]print('读excel文件:')print(df1)print(df2)# 写入Excel的多个sheet中excelWriter = pd.ExcelWriter( r'C:\Users\Administrator\Desktop\writeExcelDemo.xlsx')df1.to_excel(excelWriter, sheet_name='csv标签页', index=False)df2.to_excel(excelWriter, sheet_name='sqlite标签页', index=False)excelWriter.save()③在sqlite3种,我们放弃写sql的方式,直接用函数读写DataFrame,相当方便。 import pandas as pdimport sqlite3db = 'pandasDemo.db'with sqlite3.connect(db) as conn: records = [("张三", 25, 1), ("李四", 26, 0), ("王五", 35, 1), ("刘七", 40, 1)] df1 = pd.DataFrame(records) # 写数据库 # 如果表不存在,就自动创建 # replace:替换 append:新增 df1.to_sql('user', conn, if_exists='append') # 读数据库 df2 = pd.read_sql_query('select * from user', conn) print('读数据库:') print(df2) 2.sql统计查询
pandas用函数实现了sql统计查询:import pandas as pddata = [{ 'name': 'test1', 'age': 30, 'sex': 1, 'power': 90}, { 'name': 'test2', 'age': 25, 'sex': 0, 'power': 60}, { 'name': 'test3', 'age': 40, 'sex': 1, 'power': 80}, { 'name': 'test3', 'age': 50, 'sex': 0, 'power': 50}]df = pd.DataFrame(data)# 取某一列Seriesprint('取一列:')print(df['name'])# select name, age from dfprint('1.投影:')print(df[['name', 'age', 'sex']])# select * from df where age<30 and sex!=1 or name in ('test1','test2')print('2.筛选:')print(df.loc[(df['age'] > 20) & (~df['sex']) | (df['name'].isin(['test1', 'test2']))])# select * from df order by age descprint('3.排序:')print(df.sort_values(by='age', ascending=False))# select * from df limit 2 skip 1print('4.分页:')print(df.iloc[1:3])# 分组聚合print('5.分组聚合:')print(df.groupby('sex').agg({ 'age': ['mean', 'min'], 'power': ['sum']}))# 去重,保留第一个print('6.去重:')print(df.drop_duplicates('name', keep='first'))# join水平连接# pd.merge(df1, df2 , on='关联字段', how='left/right/outer/inner')# union垂直连接# pd.concat([df1, df2]) 3.链式调用函数
jQuery有链式操作、java有流式编程、linux有管道命令,殊途同归:都是将数据放到“生产线”上,分多个步骤依次处理。它使得代码更简洁、可读性更好,python自然也要赶上潮流。
pandas针对不同的计算粒度,给DataFrame提供了3个链式函数:
①applymap(元素函数, 参数):对每个元素 进行函数计算
②apply(数组函数, 参数):对每一列 进行函数计算
③pipe(矩阵函数, 参数):对整个矩阵 进行函数计算
我们在拿到数据后,只需选择合适的数学函数(numpy和scipy库里有很多),按次序加到“生产线”(applymap/apply/pipe)上就行。
下面的例子,演示了链式函数的用法:
import pandas as pdimport numpy as npdata = [{ 'name': 'test1', 'age': 30, 'sex': 1, 'power': 90}, { 'name': 'test2', 'age': 25, 'sex': 0, 'power': 60}, { 'name': 'test3', 'age': 40, 'sex': 1, 'power': 80}, { 'name': 'test3', 'age': 50, 'sex': 0, 'power': 50}]df = pd.DataFrame(data)# 1)演示applymap(元素函数, 参数)# 65岁退休,还要交多少社保?insurance = df[['age']].applymap(lambda x: 65 - x).applymap(lambda x: 4000 * x)print('65岁退休,还要交社保:')print(insurance)# 2)演示apply(数组函数, 参数)# 不同性别的:平均年龄和力量average = df.groupby('sex')[['age', 'power']].apply(np.mean)print('不同性别的:平均年龄和力量:')print(average)# 3)演示pipe(矩阵函数, 参数)# 年龄代表经验,力量代表活力,权重分别是2和1,计算每个人的战斗力score = df[['age', 'power']].pipe(np.dot, np.array([2, 1]))print('每个人的综合实力:')print(pd.Series(score, index=['test1', 'test2', 'test3', 'test3'])) 4.示例:软考合格人员分析
数据来源:宁夏人事考试中心公布的《2019年下半年软考合格人员名单》目标:哪些单位在本次软考中收获较大思路:①用pandas直接读取下载到的名单②取“工作单位”、“报考级别”这两列③ 量化每个人的成绩:高级3分、中级2分、初级1分 ④按“工作单位”分组,计算每个单位的总分 ⑤按总分给“工作单位”排序 ⑥将排序结果写入新的excel文件 代码如下:http://www.nxpta.com/hgry/2019hgry/202004/t20200417_4799264.html
《2019年下半年软考合格人员名单》
import pandas as pdimport numpy as npexcelPath = r'E:\迅雷下载\W020200417550914075528.xls'resultPath = r'E:\迅雷下载\软考参与单位排名.xlsx'def eveluateScore(level): if level == '高级': return 3 elif level == '中级': return 2 else: return 1# ①用pandas直接读取下载到的名单# 标题行是第3行,索引为2sheet = pd.read_excel(excelPath, header=2, sheet_name=[0])df1 = sheet[0]# ②筛选“工作单位”、“报考级别”这两列df = df1[['工作单位', '报考级别']]# ③量化每个人的成绩:高级3分、中级2分、初级1分# 将工作单位作为索引列,不参与计算df.set_index(["工作单位"], inplace=True)df = df.applymap(eveluateScore)# ④按“工作单位”分组,计算每个单位的总分df = df.groupby('工作单位').apply(np.sum)# ⑤按总分给“工作单位”排序df2 = df.sort_values(by='报考级别', ascending=False)print(df2)# ⑥将排序结果写入新的excel文件excelWriter = pd.ExcelWriter(resultPath)df2.to_excel(excelWriter, sheet_name='得分排序', index=True)excelWriter.save() VSCode运行结果: 
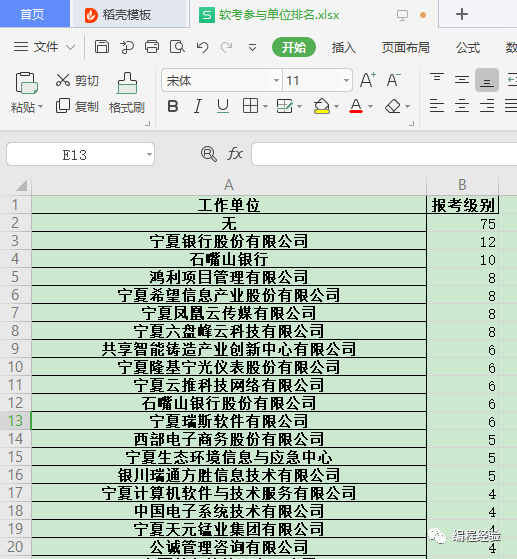
总结:
①数据库能做的统计查询,pandas都能干,而且更快 ②链式操作是pandas的特色,就像对一盘蔬菜进行多个环节的深加工;每次加工调用一个数学函数,而python能调用的数学函数远远超过任何数据库转载地址:https://blog.csdn.net/weixin_39849239/article/details/111639437 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关注你微信了!
[***.104.42.241]2024年04月09日 10时58分10秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
vue 之动画
2019-04-30
js的基础语法
2019-04-30
vue使用iconfont
2019-04-30
linux 查看文件夹权限
2019-04-30
linux tar 备份
2019-04-30
ubuntu中配置任意应用的快捷键
2019-04-30
ln 命令 硬链接
2019-04-30
使用鼠标中键在vim下赋值文本到其它编辑器
2019-04-30
chkconfig使用和级别介绍
2019-04-30
ubuntu 快捷键
2019-04-30
linux 根目录下文件夹分析
2019-04-30
ubuntu tar备份
2019-04-30
My notes about backup to ubuntu
2019-04-30
linux 查看分区和文件大小
2019-04-30
Not using PCAP_FRAMES 解释(snort中)
2019-04-30
数字信号处理——FIR滤波器设计
2019-04-30
技术转管理?这些“坑”你要绕道走
2019-04-30
领域驱动设计(DDD)前夜:面向对象思想
2019-04-30
Ubuntu 14.04 安装TM2009/QQ
2019-04-30
Ubuntu 14.04 安装VMware
2019-04-30
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 311196963 位访客
访问时间: 2024-05-05 21:17:22
访问IP: 3.138.174.174
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版