本文共 3451 字,大约阅读时间需要 11 分钟。
前几天有位微信读者问我一个爬虫的问题,就是在爬去百度贴吧首页的热门动态下面的图片的时候,爬取的图片总是爬取不完整,比首页看到的少。原因他也大概分析了下,就是后面的图片是动态加载的。他的问题就是这部分动态加载的图片该怎么爬取到。
分析
他的代码比较简单,主要有以下的步骤:使用beautifulsoup库,打开百度贴吧的首页地址,再解析得到id为new_list标签底下的img标签,最后将img标签的图片保存下来。
headers = {
'user-agent':'mozilla/5.0 (windows nt 10.0; win64; x64) applewebkit/537.36 (khtml, like gecko) chrome/51.0.2704.103 safari/537.36'
}
data=requests.get("https://tieba.baidu.com/index.html",headers=headers)
html=beautifulsoup(data.text,'lxml')
前面提到过,有部分图片是动态加载的,那么首先我们得弄清楚,这部分图片是怎么动态加载的。在浏览器中打开百度贴吧的首页,可以明显的看到,在往下滚动滚动条的时候,当滚动到底部的时候,滚动条缩短了,并向上移动了一段距离。这个现象也正是有dom元素动态的添加到了html文档的一个表现。动态加载数据无非就是ajax请求,而ajax本质上就是xmlhttprequest请求(简称xhr)。在谷歌浏览器中,我们可以通过开发者工具的network面板来监测xhr请求。
刚打开首页时的xhr请求,这里的请求都和要爬取的图片无关。
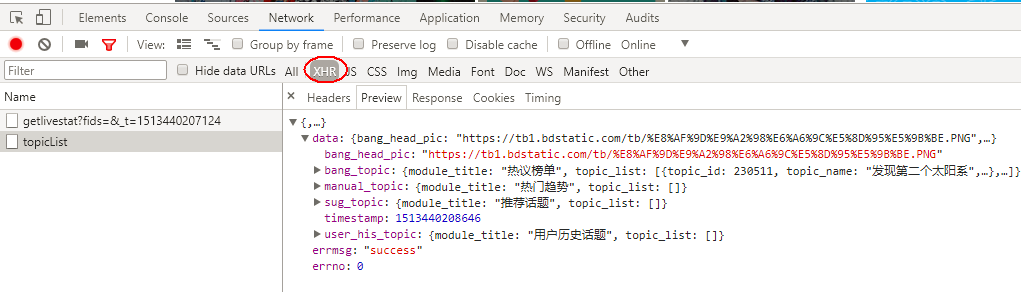
滚动条向下第1次滚动到底部,这里请求的是第20-40条热门动态,包含要爬取图片。
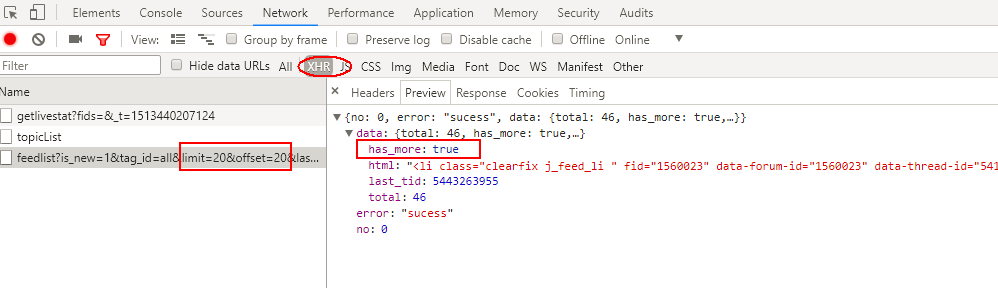
滚动条向下第2次滚动到底部,这里请求的是第40-60条热门动态,包含要爬取图片。并且返回的的has_more:false表明没有跟多数据了。
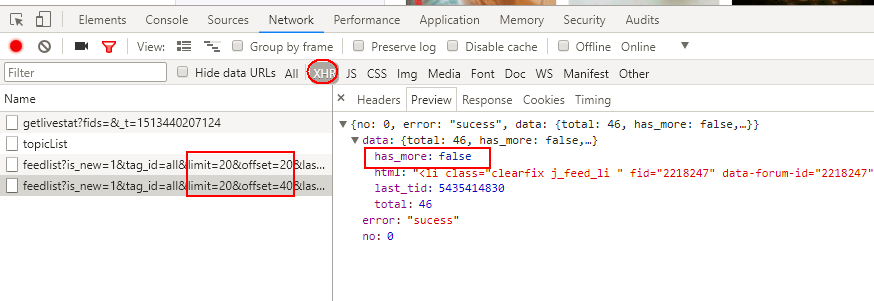
滚动条向下第3次滚动到底部,再无xhr请求。
解决方案
根据上面的分析,我们已经明白,单纯使用beautifulsoup进行爬虫的时候,只能爬取到1-20条热门动态里面的图片。为了爬取到完整的热门动态里面的图片,我们则需要模拟浏览器的滚动条滚动,让网页去触发xhr请求更多的热门动态。
在python中,如果需要模拟浏览器的行为,可以使用selenium库。selenium库是一个自动化测试框架,可以用来模拟测试浏览器的各种行为,这里我们使用它来模拟浏览器打开百度贴吧的首页,并模拟滚动条向下滚动到底部的操作。
安装
pip install selenium
下载浏览器驱动
火狐浏览器驱动,其下载地址是:
谷歌浏览器驱动,其下载地址是:
opera浏览器驱动,其下载地址是:
对照自己电脑安装的浏览器和对应的版本,分别从上面的地址下载驱动文件,也可以从我的github项目中统一下载以上几个驱动(地址:https://github.com/sesshoumaru/attachments/tree/master/selenium%20webdriver)。下载解压后,将所在的目录添加系统的环境变量中。当然你也可以将下载下来的驱动放到python安装目录的lib目录中,因为它本身已经存在于环境变量(我就是这么干的)。
使用python代码模拟浏览器行为
要使用selenium先需要定义一个具体browser对象,这里就定义的时候就看你电脑安装的具体浏览器和安装的哪个浏览器的驱动。这里以火狐浏览器为例:
from selenium import webdriver
browser = webdriver.firefox()
再模拟打开贴吧首页:
browser.get(https://tieba.baidu.com/index.html)
再模拟滚动条滚动到底部
for i in range(1, 5):
browser.execute_script('window.scrollto(0, document.body.scrollheight)')
time.sleep(1)
最后再使用beautifulsoup,解析图片标签:
html = beautifulsoup(browser.page_source, "lxml")
imgs = html.select("#new_list li img")
几个注意点
必须安装浏览器和浏览器驱动,并且浏览器和浏览器驱动要配到
即如果使用谷歌浏览器模拟网页行为,则需要下载谷歌浏览器驱动;
如果使用火狐浏览器模拟网页行为,则需要下载火狐浏览器驱动
浏览器驱动所在的目录要在环境变量中,或者定义浏览器browser的时候指定驱动的路径
selenium更多用法
查找元素
from selenium import webdriver
browser = webdriver.firefox()
browser.get("https://tieba.baidu.com/index.html")
new_list = browser.find_element_by_id('new_list')
user_name = browser.find_element_by_name ('user_name')
active = browser.find_element_by_class_name ('active')
p = browser.find_element_by_tag_name ('p')
# find_element_by_name 通过name查找单个元素
# find_element_by_xpath 通过xpath查找单个元素
# find_element_by_link_text 通过链接查找单个元素
# find_element_by_partial_link_text 通过部分链接查找单个元素
# find_element_by_tag_name 通过标签名称查找单个元素
# find_element_by_class_name 通过类名查找单个元素
# find_element_by_css_selector 通过css选择武器查找单个元素
# find_elements_by_name 通过name查找多个元素
# find_elements_by_xpath 通过xpath查找多个元素
# find_elements_by_link_text 通过链接查找多个元素
# find_elements_by_partial_link_text 通过部分链接查找多个元素
# find_elements_by_tag_name 通过标签名称查找多个元素
# find_elements_by_class_name 通过类名查找多个元素
# find_elements_by_css_selector 通过css选择武器查找多个元素
获取元素信息
btn_more = browser.find_element_by_id('btn_more')
print(btn_more.get_attribute('class')) # 获取属性
print(btn_more.get_attribute('href')) # 获取属性
print(btn_more.text) # 获取文本值
元素交互操作
btn_more = browser.find_element_by_id('btn_more')
btn_more.click() # 模拟点击,可以模拟点击加载更多
input_search = browser.find_element(by.id,'q')
input_search.clear() # 清空输入
执行javascript
# 执行javascript脚本
browser.execute_script('window.scrollto(0, document.body.scrollheight)')
browser.execute_script('alert("to bottom")')
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持萬仟网。
希望与广大网友互动??
点此进行留言吧!
转载地址:https://blog.csdn.net/weixin_32601635/article/details/114919452 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
