本文共 3234 字,大约阅读时间需要 10 分钟。
目标:学会利⽤pandas对数据进⾏合并、筛选以及排序等操作
一、数据合并(两种方法)
①concat
import pandas as pdimport numpy as npdf = pd.DataFrame([[2,5, 7, 4,9], [3, np.nan, np.nan,np.nan, 1], [2,1, np.nan, np.nan, 5], [4,2, 3, np.nan, 4]], columns=list('ABCDE'))df1 = pd.DataFrame([[1,2,3,4,5], [3, 0, 0,0, 1], [2,1, 0, 0, 5], [4,2, 3, 0, 4]], columns=list('ABCDE')) pd.concat([df,df1],axis=0,join='outer',ignore_index=True)
各个参数的含义为:
[df,df1]是我们要合并的数据,我们把他放在⼀个列表当中传⼊ axis=0 表示按⾏进⾏合并,如果为1表示按列进⾏合并 join='outer' 表示直接拼接在⼀块,如果为 inner则是按交集处理 ignore_index=True 表示重新⽣成索引
运行结果:
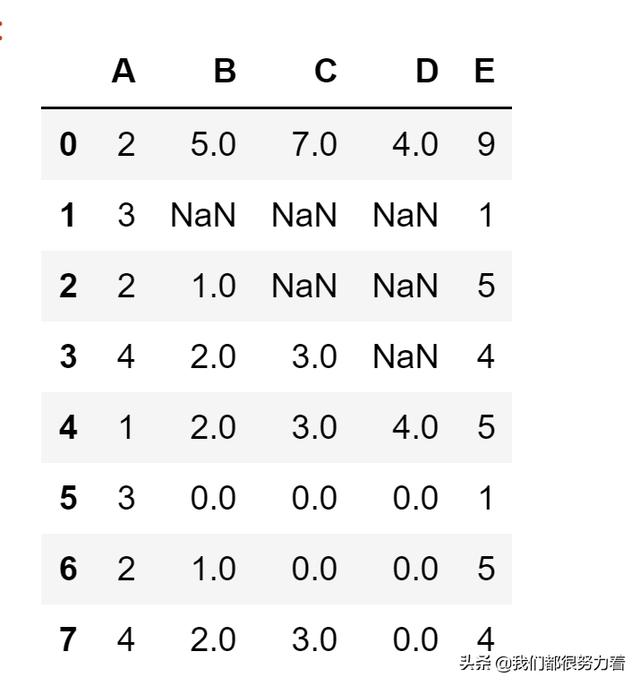
image.png
②merge
格式:merge(left, right, how='inner', on=None,left_on =None,right_on =None,left_index =None,right_index =None)
各参数含义为:
left和right是我们要合并的数据 how则是指定拼接⽅式 inner(默认)表示取交集部分 outer是直接拼接在⼀块,没内容的地⽅⽤ NAN填充 on是指定我们需要按照哪列进⾏拼接 left_on 左侧DataFarme中用作连接键的列 right_on 右侧DataFarme中用作连接键的列 left_index 将左侧的行索引用作其连接键 right_index 将右侧的行索引用作其连接键
1.merge默认按相同字段合并,且取两个都有的。
import pandas as pddf1=pd.DataFrame({'name':['kate','herz','catherine','sally'],'age':[25,28,39,35]})df2=pd.DataFrame({'name':['kate','herz','sally'],'score':[70,60,90]})pd.merge(df1,df2) age name score
0 25 kate 701 28 herz 602 35 sally 902.当左右连接字段不相同时,使用left_on,right_on
import pandas as pddf1=pd.DataFrame({'name':['kate','herz','catherine','sally'],'age':[25,28,39,35]})df2=pd.DataFrame({'call_name':['kate','herz','sally'],'score':[70,60,90]})pd.merge(df1,df2,left_on="name",right_on='call_name' age name call_name score
0 25 kate kate 701 28 herz herz 602 35 sally sally 903.合并后,删除重复的列
pd.merge(df1,df2,left_on='name',right_on='call_name').drop('name',axis=1) age call_name score
0 25 kate 701 28 herz 602 35 sally 904.参数how的使用
- 1)默认:inner 内连接,取交集” pd.merge(df1,df2,on='name',how='inner')
age name score
0 25 kate 701 28 herz 602 35 sally 90”’- 2)outer 外连接,取并集,并用nan填充”
df3=pd.DataFrame({'name':['kate','herz','sally','cristin'],'score':[70,60,90,30]})pd.merge(df1,df3,on='name',how='outer') age name score
0 25 kate 701 28 herz 602 39 catherine NaN3 35 sally 904 NaN cristin 30- 3)left 左连接, 左侧取全部,右侧取部分”
pd.merge(df1,df3,on='name',how='left')
age name score
0 25 kate 701 28 herz 602 39 catherine NaN3 35 sally 90- 4)right 有连接,左侧取部分,右侧取全部”
pd.merge(df1,df3,on='name',how='right')
age name score
0 25 kate 701 28 herz 602 35 sally 903 NaN cristin 30二、数据筛选
首先判断我们筛选的条件,如果条件成立则会返回True,表示该行被标记为True,否则被标 记为False,最后我们根据标记的True或者False来筛选出我们需要的数据,举个栗子
bools= df1['age']>25
df1['age']>25就是我们筛选的条件,我们将标记的结果赋值给bools,那么他是⼀个⼀维 数组Series对象,我们再利用
df = df1[bools]
就可以取到筛选后的数据了 如果有多个筛选条件那么就是⽤逻辑连接符链接起来即可,⽐如
bool1= df['age']>25bool2= df1['age']<30df3 = df1[bool1 & bool2]
& 与 ; | 或者
三、数据排序
数据排序同样是有两个⽅法sort_index()、sort_values(),这个排序跟我们列表排序的sort是 类似的,都是直接修改数据而不会生成一个新的数据。
1、sort_index( )方法是按照行索引进行排序
inplace=True参数和我们之前⻅过的作⽤⼀样,⽤来控制是否直接对原始数据进⾏修改。 ascending可以控制排序的顺序,默认值为True从⼩到⼤排列,当它被设置为False的时候 就可以实现倒序排列。
df1.sort_index(ascending=False,inplace=True)
2、sort_values()可以指定具体列进行排序,它比sort_index( )方法多了一个参数by
by:决定了是按数据中的哪一列进行排序,将需要按照某列排序的列名赋值给by即可 inplace=True参数和我们之前⻅过的作⽤⼀样,⽤来控制是否直接对原始数据进⾏修改。 ascending可以控制排序的顺序,默认值为True从⼩到⼤排列,当它被设置为False的时候 就可以实现倒序排列。
df1.sort_values(by='age',ascending=False,inplace=True)
转载地址:https://blog.csdn.net/weixin_32875295/article/details/112468284 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
