本文共 8699 字,大约阅读时间需要 28 分钟。

本文主要讲解golang程序的性能测评,包括pprof、火焰图和trace图的使用,进而通过测评结果指导调优方向。本文篇幅比较长,建议大家使用电脑观看,手机不太方便,超大屏手机除外。
runtime/pprof
pprof是golang官方提供的性能测评工具,包含在net/http/pprof和runtime/pprof两个包中,分别用于不同场景。
runtime/pprof主要用于可结束的代码块,如一次编解码操作等; net/http/pprof是对runtime/pprof的二次封装,主要用于不可结束的代码块,如web应用等。
首先利用runtime/pprof进行性能测评,下列代码主要实现循环向一个列表中append一个元素,只要导入runtime/pprof并添加2段测评代码就可以实现cpu和mem的性能评测。
package mainimport ( "flag" "log" "os" "runtime/pprof" "sync")func counter() { slice := make([]int, 0) c := 1 for i := 0; i < 100000; i++ { c = i + 1 + 2 + 3 + 4 + 5 slice = append(slice, c) }}func workOnce(wg *sync.WaitGroup) { counter() wg.Done()}func main() { var cpuProfile = flag.String("cpuprofile", "", "write cpu profile to file") var memProfile = flag.String("memprofile", "", "write mem profile to file") flag.Parse() //采样cpu运行状态 if *cpuProfile != "" { f, err := os.Create(*cpuProfile) if err != nil { log.Fatal(err) } pprof.StartCPUProfile(f) defer pprof.StopCPUProfile() } var wg sync.WaitGroup wg.Add(100) for i := 0; i < 100; i++ { go workOnce(&wg) } wg.Wait() //采样memory状态 if *memProfile != "" { f, err := os.Create(*memProfile) if err != nil { log.Fatal(err) } pprof.WriteHeapProfile(f) f.Close() }} 通过编译、执行后获得pprof的采样数据,然后就可以利用相关工具进行分析。
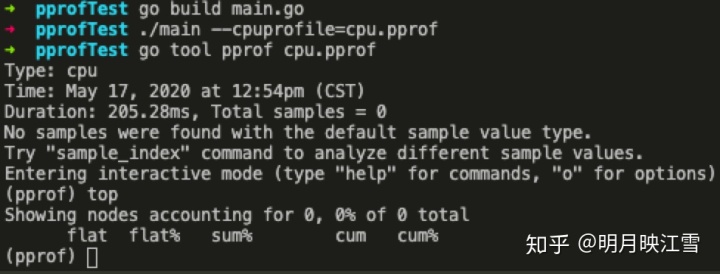
$:go build main.go$:./main --cpuprofile=cpu.pprof$:./main --memprofile=mem.pprof$:go tool pprof cpu.pprof
至此就可以获得cpu.pprof和mem.pprof两个采样文件,然后利用go tool pprof工具进行分析,见下方详情图。
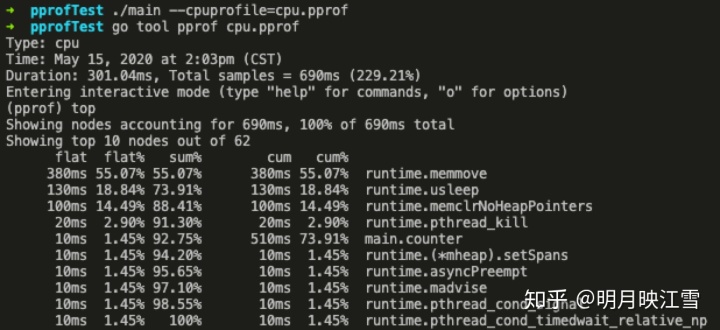
如上图所示,分别有Type和Time字段就不过多解释了。下面解释一下其他字段:
Duration:程序执行时间。在本例中golang自动分配任务给多个核执行程序,总计耗时301.04ms,而采样时间为690ms;也就是说假设有10核执行程序,平均每个核采样69ms的数据。
(pprof):命令行提示。表示当前在go tool 的pprof工具命令行中,go tool还包括cgo、doc、pprof、test2json、trace等多种命令
top:pprof的指令之一,显示pprof文件中的前10项数据,可以通过top 20等方式显示20行数据;当然pprof下有很多指令,例如list,pdf、eog等等
flat/flat%:分别表示在当前层级cpu的占用时间和百分比。例如runtime.memmove在当前层级占用cpu时间380ms,占比本次采集时间的55.07%。
cum/cum%:分别表示截止到当前层级累积的cpu时间和占比。例如main.counter累积占用时间510ms,占本次采集时间的73.91%。
sum%:所有层级的cpu时间累积占用,从小到大一直累积到100%,即690ms。
从上图中的cum数据可以看到,counter函数的cpu占用时间最多,那就利用list命令查看占用的主要因素。
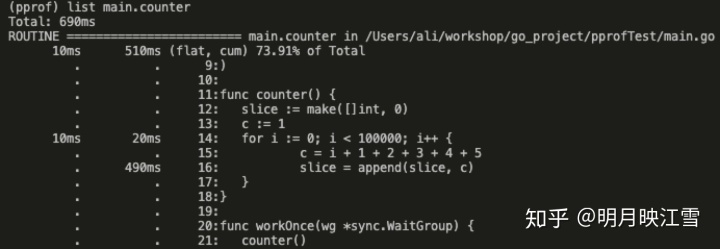
从上图中看到,程序的16行和14行分别占用490ms和20ms,这就是我们优化的主要方向。通过分析程序发现,由于slice的初始容量为0,导致在循环中append时将发生多次扩容。slice的扩容方式是:申请2倍或者1.25倍的原来长度的新slice,再将原来的slice拷贝进去。
相信大家也注意到runtime.usleep了,占用CPU时间将近20%,但是程序中明明没有任何sleep相关的代码,那为什么会出现,并且还占用这么高呢?大家可以先思考一下,后文将揭晓。
当然,也可以使用web指令获得更加直观的信息,MacOS下通过如下命令安装渲染工具。
brew install graphviz
安装完成后在pprof的命令行中输入web即可生成一个svg格式的文件,将其用浏览器打开即可得到如下所示:
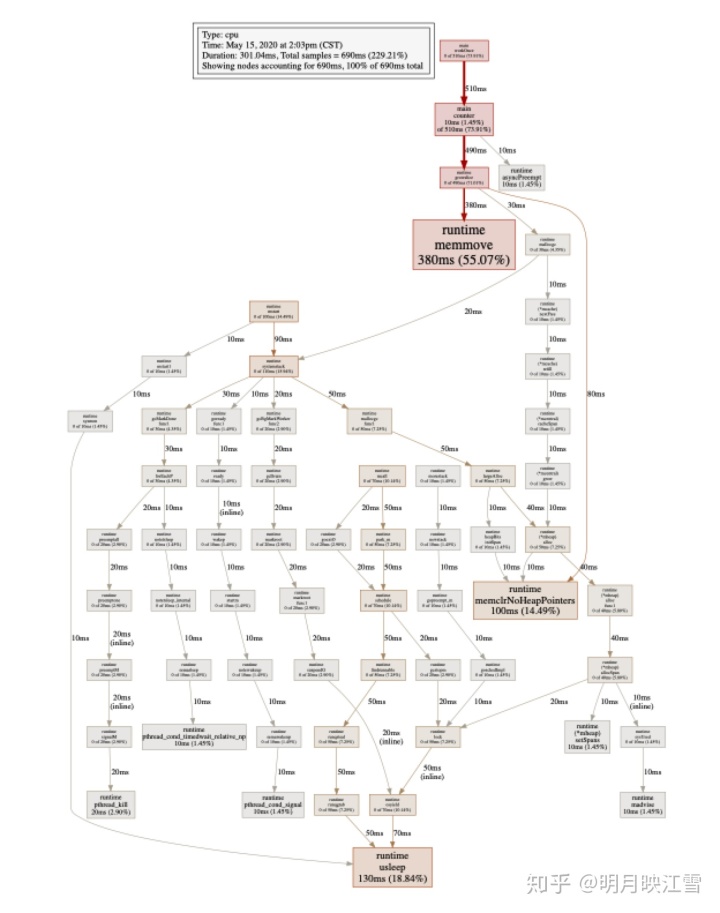
由于文件过大,我们只截取部分重要内容如下图所示。可以看出其基本信息和命令行下的信息相同,但是可以明显看出runtime.memmove耗时380ms,由图逆向推断main.counter是主要的优化方向。图中各个方块的大小也代表cpu占用的情况,方块越大说明占用cpu时间越长。
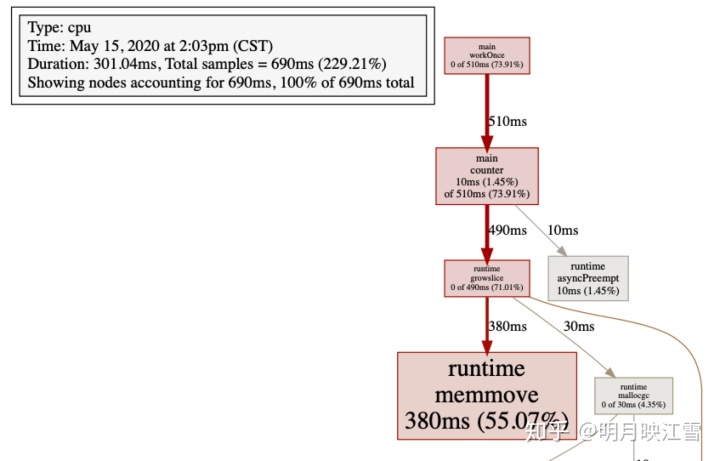
同理,我们可以分析mem.pprof文件,从而得出内存消耗的主要原因进一步进行改进。
上述main.counter占用cpu时间过多的问题,实际上是append函数中内存的重新分配造成的,那简单的做法就是事先申请一个大的内存,避免频繁的进行内存分配。所以将counter函数进行改造:
func counter() { slice := [100000]int{ 0} c := 1 for i := 0; i < 100000; i++ { c = i + 1 + 2 + 3 + 4 + 5 slice[i] = c }} 通过编译、运行、采集pprof信息后如下图所示,发现已经采集不到占用cpu比较多的函数,即已经完成优化。同学们可以试试如果在counter中添加一个fmt.Println函数后,对cpu占用会有什么影响呢?
net/http/pprof
针对后台服务型应用,服务一般不能停止,我们需要使用net/http/pprof包。类似上述代码,我们编写如下代码:
package mainimport ( "time" "net/http" _ "net/http/pprof")func counter() { slice := make([]int, 0) c := 1 for i := 0; i < 100000; i++ { c = i + 1 + 2 + 3 + 4 + 5 slice = append(slice, c) }}func workForever() { for { go counter() time.Sleep(1 * time.Second) }}func httpGet(w http.ResponseWriter, r *http.Request) { counter()}func main() { go workForever() http.HandleFunc("/get", httpGet) http.ListenAndServe("localhost:8000", nil)} 首先导入net/http/pprof包,注意该包利用下划线"_"导入,意味着我们只需要该包运行其init()函数即可,如此该包将自动完成信息采集并保存在内存中。所以在服务上线时需要将net/http/pprof包移除,其不仅影响服务的性能,更重要的是会造成内存的不断上涨。
通过编译、运行,我们便可以访问:http://localhost:8000/debug/pprof/查看服务的运行情况,本文给出如下示例,大家可以自行探究查看,同时不断刷新网页可以发现采样结果也在不断更新中。

当然我们也可以利用web形式查看,现在以查看memory为例,在服务程序运行时,执行下列命令采集内存信息。
go tool pprof main http://localhost:8000/debug/pprof/heap
采集完成后利用web指令得到svg文件
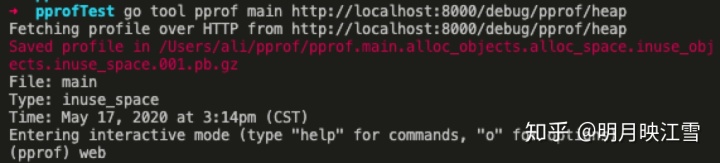
通过浏览器查看svg文件,如下图所示。该图表明所有的heap空间均由counter产生;同时我们可以生成cpu的svg文件同步进行分析优化方向。

上述方法在工具型应用中可以使用,然而在服务型应用时,仅仅只是采样了部分代码段;而只有当有大量请求时才能看到应用服务的主要优化信息,同时Uber开源的火焰图工具go-torch能够辅助我们直观的完成测评。要想实现火焰图的效果,需要安装如下3个工具:
go get -v github.com/uber/go-torchgit clone https://github.com/brendangregg/FlameGraph.gitgit clone https://github.com/wg/wrk
其中下载FlameGraph和wrk后需要进行编译,如果需要长期使用,需要将二者的可执行文件路径放到系统环境变量中。FlameGraph是画图需要的工具,而wrk是模拟并发访问的工具。通过如下命令进行模拟并发操作:500个线程并发,每秒保持2000个连接,持续时间30s
./wrk -t500 -c2000 -d30s http://localhost:8000/get
同时开启go-torch工具对http://localhost:8000采集30s信息,采集完毕后会生成svg的文件,用浏览器打开就是火焰图,如下所示:
go-torch -u http://localhost:8000 -t 30
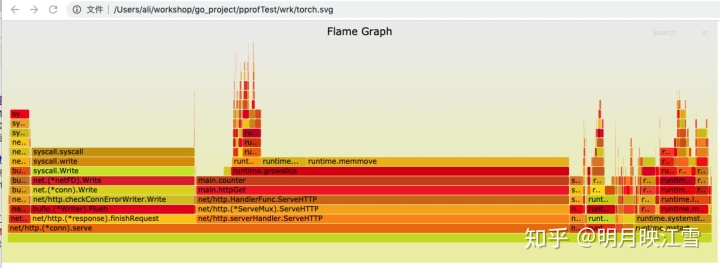
火焰图形似火焰,故此得名,其横轴是CPU占用时间,纵轴是调用顺序。由上图可以看出main.counter占用将近50%的CPU时间。通过wrk的压测后,我们可以再查看内存等信息,
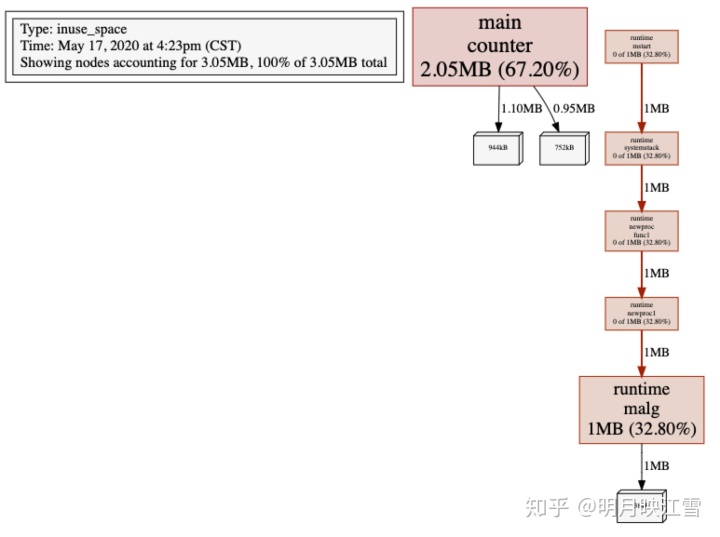
go tool pprof main http://localhost:8000/debug/pprof/heap //采集内存信息go tool pprof main http://localhost:8000/debug/pprof/profile //采集cpu信息
利用web指令看到内存的使用情况如下。其中counter函数占用67.20%,且包含2部分,因为我们的代码中有2处调用counter函数。如果大家觉得web框图更加清晰,完全可以摒弃火焰图,直接使用go tool pprof工具。
针对上述分析,我们同样通过分配初始内存,降低内存扩容次数方法进行优化。即将counter函数修改成与上文所示,再次进行cpu和内存的性能评测,火焰图和web框图分别如下:
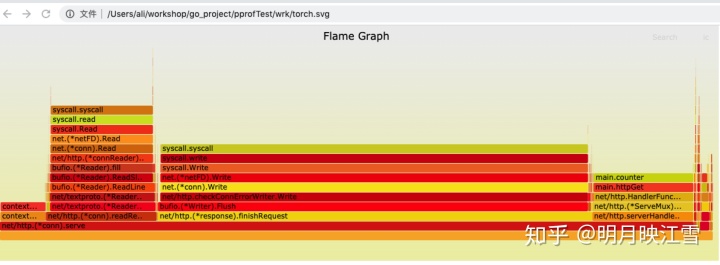
从上面的两幅图中可以看到,cpu和堆空间的使用大大降低;同时在web框图中看到pprof也会使用堆空间,所以在服务上线时应该将pprof关闭。
trace
trace工具也是golang支持的go tool工具之一,能够辅助我们跟踪程序的执行情况,进一步方便我们排查问题,往往配合pprof使用。trace的使用和pprof类似,为了简化分析,我们首先利用下列代码进行讲解,只是用1核运行程序:
package mainimport ( "os" "runtime" "runtime/trace" "sync" "flag" "log")func counter(wg *sync.WaitGroup) { wg.Done() slice := []int{ 0} c := 1 for i := 0; i < 100000; i++ { c = i + 1 + 2 + 3 + 4 + 5 slice = append(slice, c) }}func main(){ runtime.GOMAXPROCS(1) var traceProfile = flag.String("traceprofile", "", "write trace profile to file") flag.Parse() if *traceProfile != "" { f, err := os.Create(*traceProfile) if err != nil { log.Fatal(err) } trace.Start(f) defer f.Close() defer trace.Stop() } var wg sync.WaitGroup wg.Add(3) for i := 0; i < 3; i ++ { go counter(&wg) } wg.Wait()} 同样,通过编译、执行和如下指令得到trace图:
go tool trace -http=127.0.0.1:8000 trace.pprof

如果大家从浏览器上看不到上述图像,首先请更换chrome浏览器,因为目前官方只适配了chrome;如果依旧无法查看改图像,MacOS请按照下述方法进行操作。 1、登录google账号,访问https://developers.chrome.com/origintrials/#/register_trial/2431943798780067841,其中web Origin字段为此后你需要访问的web网址,例如我使用的127.0.0.1:8000。如此你将获得一个Active Token并复制下来。 2、在你的go的安装目录{$GOROOT}/src/cmd/trace/trace.go文件中,找到元素范围,并添加 3、在该目录下分别执行 go build和go install,此后重启Chrome浏览器即可查看上图。
在上图中有几个关键字段,下面进行讲解:
Goroutines:运行中的协程数量;通过点击图中颜色标识可查看相关信息,可以看到在大部分情况下可执行的协程会很多,但是运行中的只有0个或1个,因为我们只用了1核。 Heap:运行中使用的总堆内存;因为此段代码是有内存分配缺陷的,所以heap字段的颜色标识显示堆内存在不断增长中。 Threads:运行中系统进程数量;很显然只有1个。 GC:系统垃圾回收;在程序的末端开始回收资源。 syscalls:系统调用;由上图看到在GC开始只有很微少的一段。 Proc0:系统进程,与使用的处理器的核数有关,1个。
另外我们从图中可以看到程序的总运行时间不到3ms。进一步我们可以进行放大颜色区域,查看详细信息,以下图为例:

可以看到在Proc0轨道上,不同颜色代表不同协程,各个协程都是串行的,执行counter函数的有G7、G8和G9协程,同时Goroutines轨道上的协程数量也相应再减少。伴随着协程的结束,GC也会将内存回收,另外在GC过程中出现了STW(stop the world)过程,这对程序的执行效率会有极大的影响。STW过程会将整个程序通过sleep停止下来,所以在前文中出现的runtime.usleep就是此时由GC调用的。
下面我们使用多个核来运行,只需要改动GOMAXPROCS即可,例如修改成5并获得trace图:
runtime.GOMAXPROCS(5)

从上图可以看到,3个counter协程再0、2、3核上执行,同时程序的运行时间为0.28ms,运行时间大大降低,可见提高cpu核数是可以提高效率的,但是也不是所有场景都适合提高核数,还是需要具体分析。同时为了减少内存的扩容,同样可以预先分配内存,获得trace图如下所示:
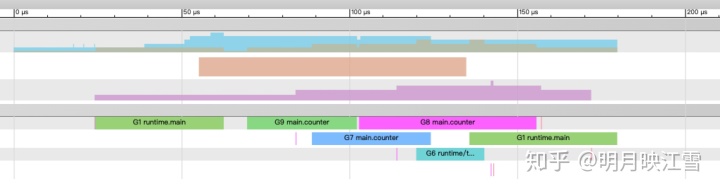
由上图看到,由于我们提前分配好足够的内存,系统不需要进行多次扩容,进而进一步减小开销。从slice的源码中看到其实现中包含指针,即其内存是堆内存,而不是C/C++中类似数组的栈空间的分配方式。另外也能看到程序的运行时间为0.18ms,进一步提高运行速度。
另外,trace图还有很多功能,例如查看事件的关联信息等等,通过点击All connected即可生成箭头表示相互关系,大家可以自己探究一下其他功能。
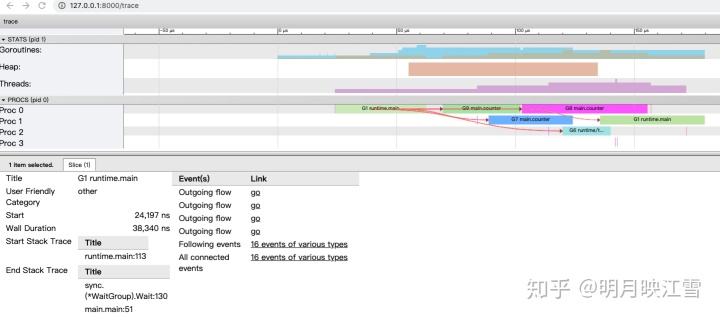
如果我们对counter函数的循环中加上锁会发生什么呢?
func counter(wg *sync.WaitGroup, m *sync.Mutex) { wg.Done() slice := [100000]int{ 0} c := 1 for i := 0; i < 100000; i++ { mutex.Lock() c = i + 1 + 2 + 3 + 4 + 5 slice[i] = c mutex.Unlock() }} 生成trace图如下:
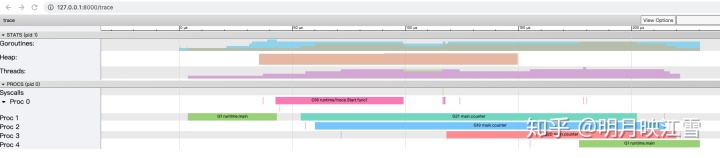
可以看到程序运行的时间又增加了,主要是由于加/放锁使得counter协程的执行时间变长。但是并没有看到不同协程对cpu占有权的切换呀?这是为什么呢?主要是这个协程运行时间太短,而相对而言采样的频率低、粒度大,导致采样数据比较少。如果在程序中人为sleep一段时间,提高采样数量就可以真实反映cpu占有权的切换。例如在main函数中sleep 1秒则出现下图所示的trace图:

如果对go协程加锁呢?
for i := 0; i < 3; i ++ { mutex.Lock() go counter(&wg) time.Sleep(time.Millisecond) mutex.Unlock() } 从得到的trace图可以看出,其cpu主要时间都是在睡眠等待中,所以在程序中应该减少此类sleep操作。
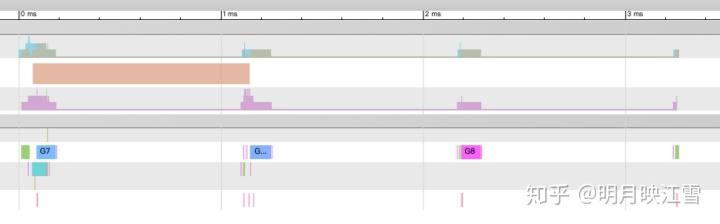
trace图可以非常完整的跟踪程序的整个执行周期,所以大家可以从整体到局部分析优化程序。我们可以先使用pprof完成初步的检查和优化,主要是CPU和内存,而trace主要是用于各个协程的执行关系的分析,从而优化结构。
本文主要讲解了一些性能评测和trace的方法,仍然比较浅显,更多用法大家可以自己去探索。
更新:
这几天又研究了下trace的相关功能,很强大,希望大家好好研究。因为分析trace图需要动态操作,不易在知乎上用图片说明,就不继续发文详述了,只要大家花1-2天时间研究研究,一定会获益匪浅的。参考:
https://golang.org/src/ https://blog.csdn.net/u013474436/article/details/105232768/ https://studygolang.com/articles/28298?fr=sidebar https://blog.csdn.net/u013474436/article/details/105232768/ https://www.cnblogs.com/nickchen121/p/11517452.html https://segmentfault.com/a/1190000018161588
转载地址:https://blog.csdn.net/weixin_33303537/article/details/112099068 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
