hive 中文字符过滤_0650-6.2.0-通过UDF实现Hive&Impala的中文拼音排序



发布日期:2021-06-24 17:53:55
浏览次数:2
分类:技术文章
本文共 1849 字,大约阅读时间需要 6 分钟。
作者:余枫
1.问题重现
- 测试环境:
1.RedHat7.2
2.CDH6.2.0
3.使用root进行操作
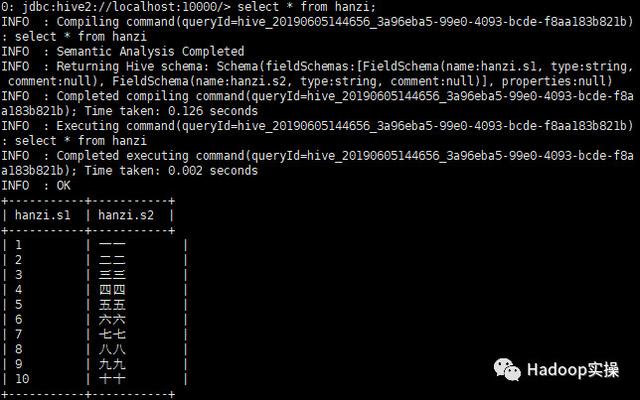
1.在Hive中创建一个表,并导入数据如下
2.对s2字段进行排序
select * from hanzi order by s2;
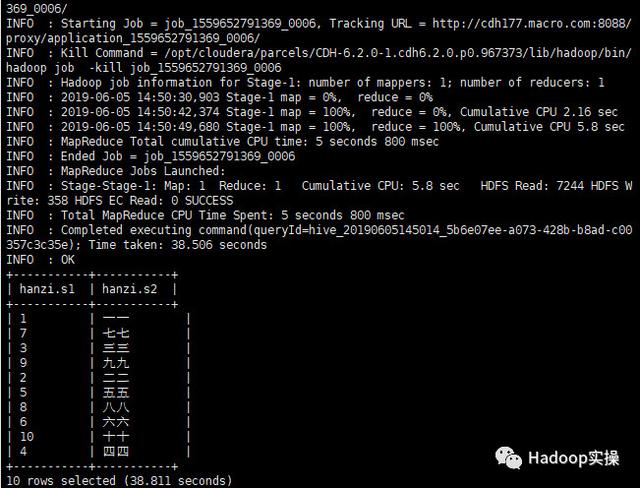
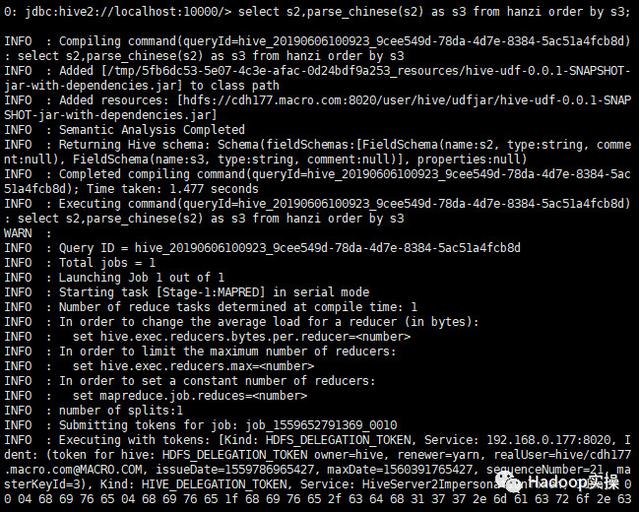
在Hive中:
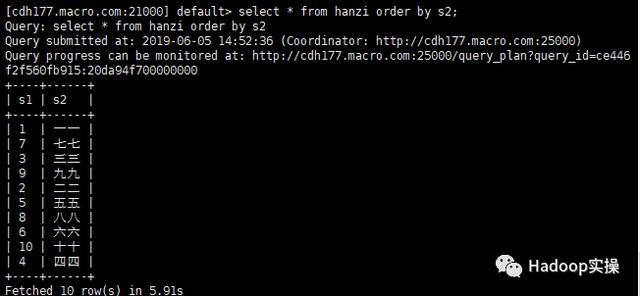
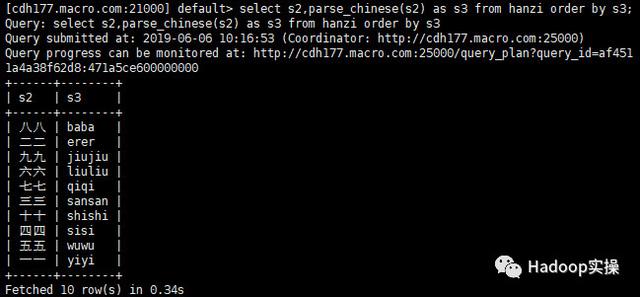
在Impala中:
由上面两张图可以看出,在Hive和Impala中排序都失败了,没有按照期望中的中文对应的拼音进行排序。
2.问题解决
1.想要实现对中文字段的排序,需要将中文字段转换成拼音,然后在Hive、Impala中对拼音进行排序即可。因此可以使用UDF在Java中写一个汉字转拼音的程序,然后在Hive、Impala中使用,代码如下:
public String evaluate(String ChineseLanguage) { char[] cl_chars = ChineseLanguage.trim().toCharArray(); String hanyupinyin = ""; HanyuPinyinOutputFormat defaultFormat = new HanyuPinyinOutputFormat(); defaultFormat.setCaseType(HanyuPinyinCaseType.LOWERCASE);// 输出拼音全部小写 defaultFormat.setToneType(HanyuPinyinToneType.WITHOUT_TONE);// 不带声调 defaultFormat.setVCharType(HanyuPinyinVCharType.WITH_V); try { for (int i = 0; i < cl_chars.length; i++) { if (String.valueOf(cl_chars[i]).matches("[一-龥]+")) {// 如果字符是中文,则将中文转为汉语拼音 hanyupinyin += PinyinHelper.toHanyuPinyinStringArray(cl_chars[i], defaultFormat)[0]; } else {// 如果字符不是中文,则不转换 hanyupinyin += cl_chars[i]; } } } catch (BadHanyuPinyinOutputFormatCombination e) { System.out.println("字符不能转成汉语拼音"); } return hanyupinyin;} 2.将编写好的代码打成jar包并上传到服务器
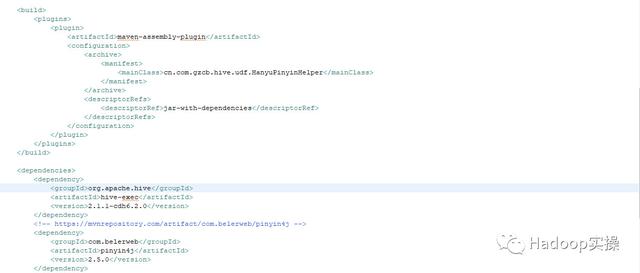
打包前在POM文件中加入配置,将所有依赖也一起打成一个jar包
maven-assembly-plugin cn.com.gzcb.hive.udf.HanyuPinyinHelperjar-with-dependenciesorg.apache.hive hive-exec 2.1.1-cdh6.2.0com.belerweb pinyin4j 2.5.0
使用mvn assembly:assembly命令打包,打好的包如下,以-jar-with-dependencies结尾
上传到服务器
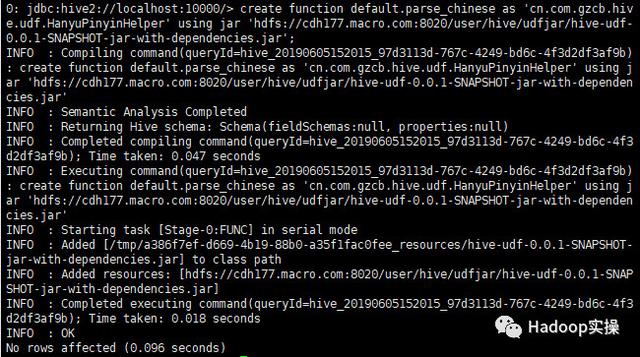
3.将jar包上传到HDFS,创建UDF函数
上传到/user/hive/udfjar目录下
进入Hive中,创建UDF函数
create function default.parse_chinese as 'cn.com.gzcb.hive.udf.HanyuPinyinHelper' using jar 'hdfs://cdh177.macro.com:8020/user/hive/udfjar/hive-udf-0.0.1-SNAPSHOT-jar-with-dependencies.jar';
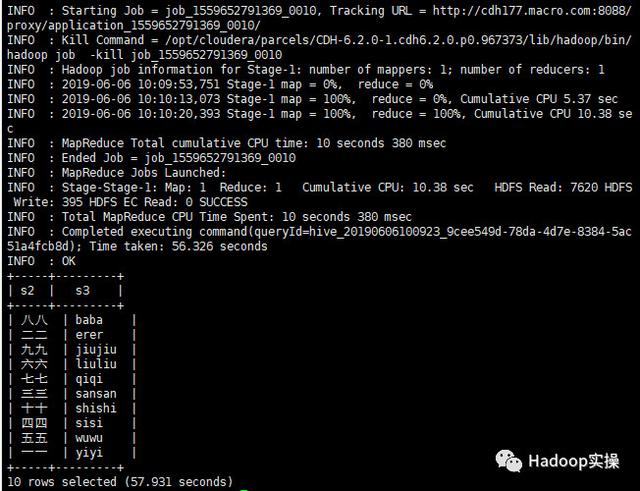
4.再次对hanzi表进行排序
select s2,parse_chinese(s2) as s3 from hanzi order by s3;
Hive
Impala
从Hive和Impala的执行结果可以看出,是按照拼音的升序成功进行了排序。
3.问题总结
无论是Hive还是Impala都不支持中文按照拼音的排序,因为它们支持的主要是标准的ASCII字符集并不包含中文,如果要对中文按照拼音排序,需要通过UDF将中文转换成拼音后实现,而中文转换成拼音的函数Java中有很多现成的参考比较方便。
转载地址:https://blog.csdn.net/weixin_34237125/article/details/112450317 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
能坚持,总会有不一样的收获!
[***.219.124.196]2024年04月12日 18时29分29秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
opencv模板匹配相同位置去除重复的框
2019-04-28
windows10+ubuntu16.04双系统安装教程--UEFI安装方法
2019-04-28
深度学习框架配置和实践
2019-04-28
Ubuntu 16.04安装截图工具Shutter
2019-04-28
ubuntu16.04安装搜狗输入法
2019-04-28
大创学习记录
2019-04-28
大创学习记录(二)
2019-04-28
大创学习记录(三)
2019-04-28
how to build your blog?
2019-04-28
大二下学期末总结
2019-04-28
[PAT B1001]害死人不偿命的(3n+1)猜想
2019-04-28
[PAT B1032]挖掘技术哪家强
2019-04-28
【5.10】实训Day-4记录
2019-04-28
【5.12-5.13】实训Day-6&Day-7记录
2019-04-28
[PAT B1011]A+B和C
2019-04-28
【5.17-5.19】实训Day9-Day11记录
2019-04-28
【5.31】实训Day19记录
2019-04-28
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 308946384 位访客
访问时间: 2024-04-29 12:15:05
访问IP: 18.222.119.148
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版